What is the Goal of a DevOps Methodology? A Technical Guide
 By opsmoon
By opsmoonCurious about what is the goal of a devops methodology? Discover how DevOps practices speed delivery, improve stability, and empower teams.
At its core, the goal of a DevOps methodology is to unify software development (Dev) and IT operations (Ops) to ship better software, faster and more reliably. It systematically dismantles the organizational and technical walls between the teams building new features and the teams responsible for production stability, creating a single, highly automated workflow from code commit to production deployment.
This fusion is engineered to increase deployment frequency and reduce lead time for changes while simultaneously improving operational stability and mean time to recovery (MTTR).
Balancing Software Velocity and System Stability
In traditional IT structures, a fundamental conflict exists. Development teams are incentivized by feature velocity—how quickly they can ship new code. Operations teams are measured on stability and uptime, making them inherently risk-averse to frequent changes. This creates a natural tension, a "wall of confusion" that slows down value delivery and pits teams against each other.
DevOps doesn't just reduce this friction; it re-engineers the system to align incentives and processes.
Consider a Formula 1 team. The driver (Development) is focused on maximum speed to win the race. The pit crew (Operations) needs the car to be mechanically sound and predictable to avoid catastrophic failure. Without tight integration and real-time data flow, they are guaranteed to lose. The driver might over-stress the engine, or an overly cautious pit crew might perform slow, unnecessary checks that cost valuable seconds.
A true DevOps culture integrates them into a single functional unit. The driver receives constant telemetry from the car (monitoring), and the pit crew uses that data to perform precise, high-speed adjustments (automated deployments). They share the same objective, measured by the same KPIs: win the race by perfectly balancing raw speed with flawless execution and resilience.
The Shift From Silos to Synergy
This is more than a procedural adjustment; it's a fundamental re-architecture of culture and technology. High-performing organizations that correctly implement DevOps can deploy 30 times more frequently with 200 times shorter lead times than their peers. This performance leap isn't achieved by a single tool—it's the result of breaking down silos, automating workflows, and focusing the entire engineering organization on shared, measurable outcomes. You can read more about the impact of these statistics on DevOps trends from invensislearning.com.
To fully grasp this paradigm, it’s useful to understand its relationship with other frameworks. DevOps and Agile, for example, both value iterative delivery and continuous improvement, but they address different scopes within the software lifecycle. A deeper technical comparison of Agile vs DevOps can clarify their distinct roles and synergistic potential.
To illustrate the technical and philosophical shift, let's contrast the operational goals.
DevOps Goals vs Traditional IT Goals
The table below contrasts the siloed metrics of traditional IT with the shared, outcome-focused goals of a DevOps culture. It’s a clear illustration of the shift from protecting functional domains to optimizing end-to-end value delivery.
| Metric | Traditional IT Goal | DevOps Goal |
|---|---|---|
| Deployment | Minimize deployments to reduce risk. Each release is a large, high-stakes event. | Increase deployment frequency. Small, frequent releases lower risk and speed up feedback. |
| Failure Management | Avoid failure at all costs (Maximize Mean Time Between Failures – MTBF). | Recover from failure instantly (Minimize Mean Time To Recovery – MTTR). |
| Team Responsibility | Dev builds it, Ops runs it. Clear separation of duties and handoffs. | "You build it, you run it." Shared ownership across the entire application lifecycle. |
| Change | Control and restrict change through rigid processes and long approval cycles. | Embrace and enable change through automation and collaborative review. |
| Measurement | Measure individual team performance (e.g., tickets closed, server uptime). | Measure end-to-end delivery performance (e.g., lead time for changes, change failure rate). |
This comparison makes it obvious: DevOps isn't just about doing the same things faster. It's about changing what you measure, what you value, and ultimately, how you work together.
The central objective is to create a resilient, efficient, and value-driven software delivery lifecycle. It’s not just about tools or automation; it's a strategic approach to achieving measurable business outcomes through a combination of cultural philosophy and technical excellence.
Ultimately, DevOps redefines engineering success. Instead of grading teams on isolated metrics like "story points completed" or "99.9% server uptime," the focus shifts to holistic results—like faster time-to-market, improved mean time to recovery (MTTR), and lower change failure rates. This alignment gets the entire organization moving in the same direction, delivering real value to users faster and more safely than ever before.
Exploring the Five Technical Pillars of DevOps
To truly understand DevOps, we must move beyond the abstract goal of "balancing speed and stability" and analyze the concrete technical pillars that enable it. These five pillars—Speed, Quality, Stability, Collaboration, and Security—are not just concepts. They are implemented through specific engineering practices and toolchains. Each pillar supports the others, creating a robust system for delivering high-quality software.
This concept map illustrates the core principle: a continuous, automated loop between Development and Operations.
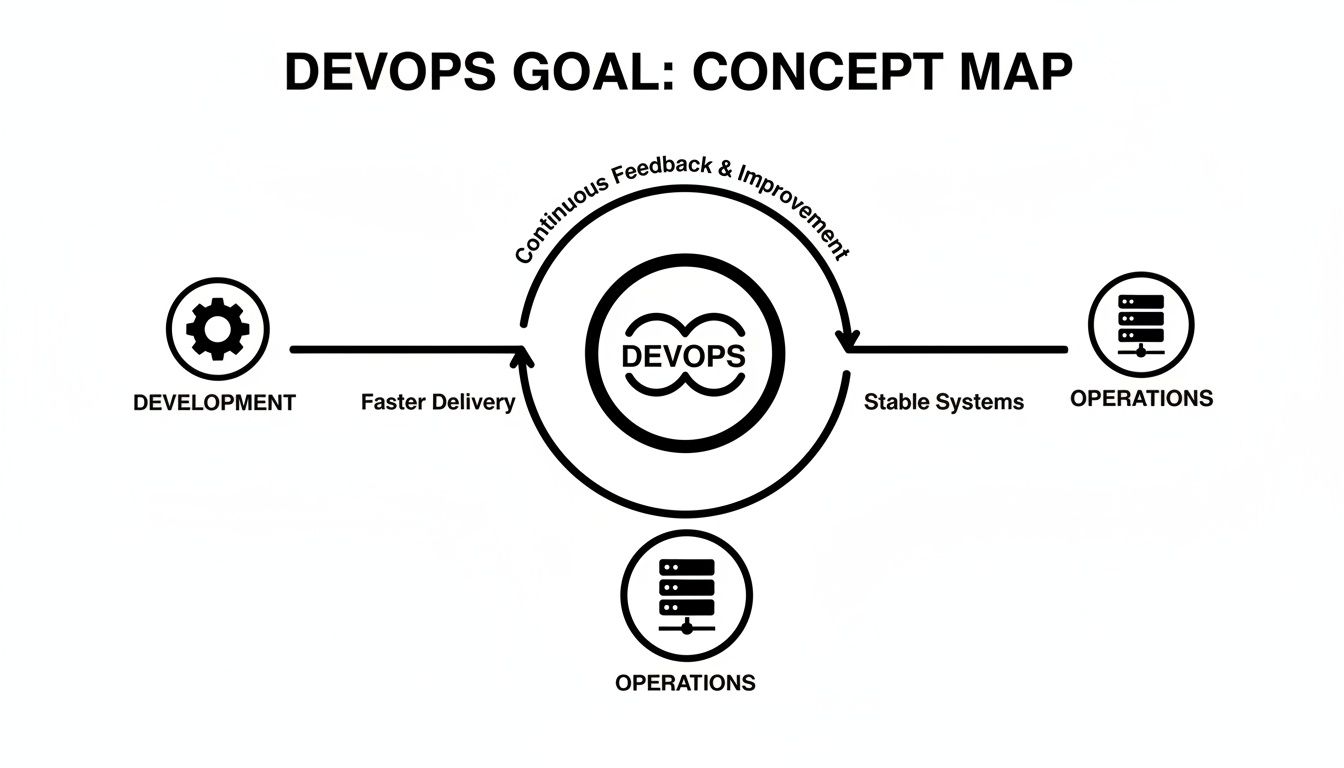
It’s no longer a linear handoff from one team to the next. Development and Operations are fused into a single, unending cycle of building, deploying, and operating software. This continuous flow is what powers the five pillars.
Accelerating Delivery with Speed
Speed in DevOps is not about cutting corners; it's about building an automated, repeatable, and low-friction pipeline from a developer's local machine to production. Continuous Integration/Continuous Delivery (CI/CD) pipelines are the engine of this speed.
A CI/CD pipeline automates the entire software release process: compiling code, executing automated tests, packaging artifacts (e.g., Docker images), and deploying to various environments. Instead of manual handoffs that introduce delays and human error, automated pipelines execute these steps in minutes.
A crucial enabler of speed is Infrastructure as Code (IaC). Using declarative tools like Terraform or AWS CloudFormation, you define your entire infrastructure—VPCs, subnets, EC2 instances, load balancers, databases—in version-controlled configuration files.
With IaC, provisioning a complete, production-identical staging environment is reduced to a single command (
terraform apply). This eliminates configuration drift between environments and transforms a multi-week manual process into a repeatable, on-demand action.
Embedding Quality from the Start
The goal of DevOps is to ship high-quality software rapidly, not just to ship software rapidly. This pillar focuses on shifting quality assurance from a final, manual inspection gate to a continuous, automated process that begins with the first line of code. This is known as "shifting left."
This is achieved by integrating a suite of automated tests directly into the CI/CD pipeline:
- Unit Tests: Fast, isolated tests (e.g., using JUnit, PyTest) that verify the correctness of individual functions or classes. They are the first line of defense, executed on every commit.
- Integration Tests: Verify that different components or microservices interact correctly, ensuring that API contracts are honored and data flows as expected.
- Static Code Analysis: Tools like SonarQube or linters are integrated into the pipeline to automatically scan source code for bugs, security vulnerabilities, and code complexity issues ("code smells"). This enforces coding standards and prevents common errors from being merged.
Automating these checks provides developers with immediate feedback within minutes of a commit, allowing them to fix issues while the context is fresh, dramatically reducing the cost and effort of remediation.
Engineering for Stability and Resilience
Stability is the foundation of user trust. A high-velocity pipeline is a liability if it consistently deploys fragile, failure-prone software. This pillar is about architecting resilient systems and instrumenting them with deep, real-time visibility. This is the domain of observability.
A robust observability strategy is built on three core data types:
- Metrics: Time-series numerical data that provides a high-level view of system health. Tools like Prometheus scrape endpoints to track key indicators like CPU utilization, memory consumption, and request latency.
- Logs: Immutable, timestamped records of discrete events. Implementing structured logging (e.g., outputting logs as JSON) is critical, as it allows for efficient parsing, querying, and analysis in platforms like Elasticsearch or Splunk.
- Traces: Capture the end-to-end journey of a single request as it propagates through a distributed system (e.g., multiple microservices). This is essential for debugging latency issues and identifying bottlenecks.
This telemetry is aggregated into dashboards using tools like Grafana, providing engineering teams with a unified view for performance monitoring, anomaly detection, and rapid troubleshooting.
Fostering Technical Collaboration
While DevOps is a cultural shift, specific technical practices are required to facilitate that collaboration. The cornerstone is version control, specifically Git. Git provides the distributed model necessary for parallel development and the branching/merging strategies (like GitFlow or trunk-based development) that enable controlled, auditable code integration.
Beyond source code, technical processes like blameless postmortems are critical. When an incident occurs, the objective is not to assign blame but to conduct a systematic root cause analysis across the technical stack and operational procedures. This creates a culture of psychological safety where engineers can openly discuss failures, which is the only way to implement meaningful preventative actions.
Integrating Security into the Lifecycle
Historically, security was a final, often manual, gate before a release, frequently causing significant delays. DevSecOps reframes this by "shifting security left," embedding automated security controls into every phase of the software lifecycle.
Key DevSecOps practices integrated into the CI/CD pipeline include:
- Static Application Security Testing (SAST): Scans source code for known vulnerability patterns (e.g., SQL injection, cross-site scripting).
- Dynamic Application Security Testing (DAST): Analyzes the running application to identify security flaws from an external perspective.
- Software Composition Analysis (SCA): Scans project dependencies (e.g., npm packages, Maven libraries) against databases of known vulnerabilities (CVEs).
By automating these scans, security becomes a shared, continuous responsibility, ensuring applications are secure by design, not by a last-minute audit.
Measuring Success with Actionable DevOps KPIs
To truly understand the goal of DevOps, you must move from principles to empirical data. Goals without measurement are merely aspirations. Key Performance Indicators (KPIs) transform the five pillars of DevOps into a practical dashboard that demonstrates value, justifies investment, and guides continuous improvement.
Without data, you're flying blind. You might feel like your processes are improving, but can you prove it? KPIs provide the objective evidence needed to demonstrate a return on investment (ROI) and make data-driven decisions.
The real-world results are compelling. According to research highlighted on Instatus.com, elite DevOps performers recover from failures 24 times faster and have a 3 times lower change failure rate. They also spend 22% less time on unplanned work and rework, freeing up engineering cycles for innovation rather than firefighting.
The Four DORA Metrics
The DevOps Research and Assessment (DORA) team identified four key metrics that are powerful predictors of engineering team performance. Elite teams excel at these, and they have become the industry gold standard for measuring DevOps effectiveness.
- Deployment Frequency: How often an organization successfully releases to production. This is a direct proxy for batch size and team throughput.
- Lead Time for Changes: The median time it takes for a commit to get into production. This measures the efficiency of the entire development and delivery pipeline.
- Change Failure Rate: The percentage of deployments to production that result in a degraded service and require remediation (e.g., a rollback, hotfix). This is a critical measure of quality and stability.
- Mean Time to Recovery (MTTR): The median time it takes to restore service after a production failure. This is the ultimate measure of a system's resilience and the team's incident response capability.
These four metrics create a balanced system. They ensure that velocity (Deployment Frequency, Lead Time) is not achieved at the expense of stability (Change Failure Rate, MTTR). Optimizing one pair while ignoring the other leads to predictable failure modes.
How to Technically Measure These KPIs
Tracking these KPIs is not a manual process; it's about instrumenting your toolchain to extract this data automatically.
- Lead Time for Changes: This is calculated as
timestamp(deployment) - timestamp(commit). Your version control system (like Git) provides the commit timestamp, and your CI/CD tool (like GitLab CI, GitHub Actions, or Jenkins) provides the successful deployment timestamp. - Deployment Frequency: This is a simple count of successful production deployments over a given time period. This data is extracted directly from the deployment logs of your CI/CD tool.
- Change Failure Rate: This requires correlating deployment events with incidents. An API integration can link a deployment from your CI/CD tool to an incident ticket created in a system like Jira or a high-severity alert from PagerDuty. The formula is: (Number of deployments causing a failure / Total number of deployments) * 100.
- Mean Time to Recovery (MTTR): This is calculated as
timestamp(incident_resolved) - timestamp(incident_detected). This data is sourced from your incident management or observability platform.
For a more comprehensive guide, see our article on engineering productivity measurement, which details how to build a complete measurement framework.
Beyond DORA: Other Essential Metrics
While the DORA four are your north star, a holistic view of operational health requires additional telemetry.
A well-rounded DevOps dashboard doesn't just measure delivery speed; it also quantifies system reliability, user experience, and financial efficiency. This holistic view connects engineering efforts directly to business value.
Here are other critical KPIs to monitor:
- System Uptime/Availability: A fundamental measure of reliability, typically expressed as a percentage (e.g., 99.99% uptime), often tied to Service Level Objectives (SLOs).
- Error Rates: The frequency of application-level errors (e.g., HTTP 500s) or unhandled exceptions, often tracked via Application Performance Monitoring (APM) tools.
- Cloud Spend Optimization (FinOps): Tracking cloud resource costs against utilization to prevent waste and ensure financial efficiency. This metric links operational decisions directly to business profitability.
This reference table outlines the technical implementation for tracking key metrics.
| Key DevOps KPIs and Measurement Methods |
| —————————————– | ——————————————————————————————————————– | ———————————————————————————————— |
| KPI | What It Measures | How to Track It (Example Tools) |
| Deployment Frequency | The rate of successful deployments to production, indicating development velocity. | CI/CD pipeline logs from tools like Jenkins, GitLab CI, or GitHub Actions. |
| Lead Time for Changes | The time from code commit to successful production deployment, measuring pipeline efficiency. | Timestamps from Git (commit) and CI/CD tools (deployment). |
| Change Failure Rate | The percentage of deployments that result in a production failure or service degradation. | Correlate deployment data (CI/CD tools) with incident data (Jira, PagerDuty). |
| Mean Time to Recovery (MTTR) | The average time it takes to restore service after a production failure, reflecting system resilience. | Incident management platforms like PagerDuty or observability tools like Datadog. |
| System Uptime/Availability | The percentage of time a system is operational and accessible to users. | Monitoring tools like Prometheus, Grafana, or cloud provider metrics (e.g., AWS CloudWatch). |
| Error Rates | The frequency of errors (e.g., HTTP 500s) generated by the application. | Application Performance Monitoring (APM) tools like Sentry, New Relic, or Datadog. |
| Cloud Spend | The cost of cloud infrastructure, ideally correlated with usage and business value. | Cloud provider billing dashboards (AWS Cost Explorer, Azure Cost Management) or FinOps platforms. |
Tracking these metrics provides an objective, data-driven view of your DevOps implementation's performance and highlights areas for targeted improvement.
Adoption Models and Common Implementation Pitfalls
Knowing the goals of DevOps is necessary but insufficient for success. Transitioning from theory to practice requires a deliberate adoption strategy, and no single model fits all organizations. The optimal path depends on your company's scale, existing team structure, and technical maturity.
Choosing an adoption model is a strategic decision aimed at achieving the core DevOps balance of velocity and stability. However, even the best strategy can be undermined by common implementation pitfalls that derail progress.
Choosing Your Implementation Path
Organizations typically follow one of three primary models when initiating a DevOps transformation. Each presents distinct advantages and challenges.
- The Pilot Project Model: This involves selecting a single, non-critical but high-impact project to serve as a testbed for new tools, processes, and collaborative structures. This model contains risk and allows a small, dedicated team to iterate quickly, creating a proven blueprint for broader organizational adoption.
- The Center of Excellence (CoE) Model: A central team of DevOps experts is established to research, standardize, and promote best practices and tooling across the organization. The CoE acts as an internal consultancy, ensuring consistency and preventing disparate teams from solving the same problems independently. This is particularly effective in large enterprises.
- The Embedded Platform Model: This modern approach involves creating a platform engineering team that builds and maintains a paved road of self-service tools and infrastructure. Platform engineers may be embedded within product teams to help them leverage these shared services effectively, ensuring the platform evolves to meet real developer needs.
As you consider your implementation, understanding the context of other methodologies is helpful. For a detailed comparison, see this guide on Agile vs. DevOps methodologies.
Critical Pitfalls to Avoid on Your Journey
Successful DevOps adoption is as much about avoiding common failure modes as it is about choosing the right model. Many initiatives fail due to a fundamental misunderstanding of the required changes.
The most common reason DevOps initiatives fail is a narrow focus on tools while ignoring the necessary cultural and process transformation. A shiny new CI/CD pipeline is useless if development and operations teams still operate in adversarial silos.
Here are four of the most destructive traps and how to architect your way around them:
-
Focusing Only on Tools, Not Culture
This is the "cargo cult" approach: buying a suite of automation tools and expecting behavior to change. True DevOps requires automating re-engineered, collaborative processes, not just paving over existing broken ones.Actionable Advice: Prioritize cultural change. Institute blameless postmortems, establish shared SLOs for Dev and Ops, and create unified dashboards so everyone is looking at the same data.
-
Creating a New "DevOps Team" Silo
Ironically, many organizations try to break down silos by creating a new one: a "DevOps Team" that becomes a bottleneck for all automation and infrastructure requests, sitting between Dev and Ops.Actionable Advice: Adopt a platform engineering mindset. The goal of a central team should be to build self-service capabilities that empower product teams to manage their own delivery pipelines and infrastructure, not to do the work for them.
-
Neglecting Security Until the End (Bolting It On)
If security reviews remain a final, manual gate before deployment, you are not practicing DevOps. "Bolting on" security at the end of the lifecycle creates friction, delays, and an adversarial relationship with the security team.Actionable Advice: Implement DevSecOps by integrating automated security tools (SAST, DAST, SCA) directly into the CI/CD pipeline. Make security a shared responsibility from the first commit.
-
Failing to Secure Executive Sponsorship
A genuine DevOps transformation requires investment in tools, training, and—most critically—time for teams to learn and adapt. Without strong, consistent support from leadership, initiatives will stall when they encounter organizational resistance or require budget.Actionable Advice: Frame the business case for DevOps in terms of the KPIs leadership cares about: reduced time-to-market, lower change failure rates, and improved system resilience and availability.
Understanding your organization's current state is crucial. You can assess your progress by mapping your practices against standard DevOps maturity levels to identify the next logical steps in your evolution.
The Future of DevOps Goals: Resilience and Governance
The DevOps landscape is constantly evolving. While speed and stability remain foundational, the leading edge of DevOps has shifted its focus toward two more advanced goals: building inherently resilient systems and embedding automated governance.
This represents a significant evolution in thinking. The original question was, "How fast can we deploy code?" The more mature, business-critical question is now: "How quickly can we detect and recover from failure with minimal user impact?" The focus is shifting from preventing failure (an impossibility in complex systems) to building antifragile systems that gracefully handle failure.
From Reactive Fixes to Proactive Resilience
Modern resilience engineering is not about having an on-call team that is good at firefighting. It's about proactively discovering system weaknesses before they manifest as production incidents. This is the domain of chaos engineering. This practice involves running controlled experiments to inject failures—such as terminating EC2 instances, injecting network latency, or maxing out CPU—to verify that the system responds as expected. The goal is to uncover hidden dependencies and single points of failure before they impact users.
Another key component is progressive delivery. Instead of high-risk "big bang" deployments, teams use advanced deployment strategies to limit the blast radius of a potential failure.
- Canary Releases: A new version is deployed to a small subset of production traffic. The system's key metrics (error rates, latency) are monitored closely. If they remain healthy, traffic is gradually shifted to the new version.
- Feature Flags: This technique decouples code deployment from feature release. New code can be deployed to production in a "dark" or "off" state. This allows for instant rollbacks by simply flipping a switch in a configuration service, without requiring a full redeployment.
These practices are central to Site Reliability Engineering (SRE), a discipline focused on building ultra-reliable, scalable systems. To delve deeper, it's essential to understand the core site reliability engineering principles that underpin this mindset.
Weaving Governance into the Automation Fabric
As DevOps matures within an organization, governance and compliance cannot remain manual, after-the-fact processes. The goal is to automate these controls directly within the CI/CD pipeline, making them an inherent part of the delivery process rather than a bottleneck.
This emerging discipline shifts the focus from deployment velocity alone to the system's ability to absorb change safely. Mature organizations measure resilience with metrics that track the time to detect, isolate, and remediate failures. Governance is no longer a separate function but is encoded into the system with automated policy enforcement and auditable trails.
Two technologies are central to this shift:
Policy as Code (PaC): Using frameworks like Open Policy Agent (OPA), teams define security, compliance, and operational policies as code. This code is version-controlled, testable, and can be automatically enforced at various stages of the CI/CD pipeline. For example, a pipeline could automatically fail a Terraform plan if it attempts to create a publicly exposed S3 bucket.
FinOps (Cloud Financial Operations): This practice integrates cost management directly into the DevOps lifecycle. By incorporating cost estimation tools into the CI/CD pipeline, teams can see the financial impact of their infrastructure changes before they are applied, preventing budget overruns.
The future of DevOps is about building intelligent, self-healing, and self-governing systems. The goal is a software delivery apparatus that is not just fast, but secure, compliant, resilient, and cost-effective by design.
How to Actually Hit Your DevOps Goals
Understanding the technical goals of DevOps is the first step. Executing them successfully is the real challenge. This is where a specialist partner like OpsMoon can bridge the gap between strategy and implementation. The process begins not with tool selection, but with a rigorous, data-driven assessment of your current state.
We start by benchmarking your current DevOps maturity against elite industry performers. This analysis identifies specific gaps in your culture, processes, and technology stack. The output is not a generic recommendation, but a detailed, actionable roadmap with prioritized initiatives designed to deliver the highest impact on your software delivery performance.
Overcoming the Engineering Skill Gap
One of the most significant impediments to achieving DevOps goals is the highly competitive market for specialized engineering talent. Finding engineers with deep, hands-on expertise in foundational DevOps technologies is a major bottleneck for many organizations. A managed framework provides an immediate solution.
Instead of engaging in a lengthy and expensive talent search, you gain access to pre-vetted engineers from the top 0.7% of the global talent pool. These are not generalists; they are specialists who have designed, built, and scaled complex systems using the exact technologies you need.
- Kubernetes Orchestration: Experts in designing and operating resilient, scalable containerized platforms.
- Terraform Expertise: Masters of creating modular, reusable, and automated infrastructure using Infrastructure as Code (IaC).
- CI/CD Pipeline Mastery: Architects of sophisticated, secure, and efficient build, test, and deployment workflows.
- Advanced Observability: Specialists in implementing the monitoring, logging, and tracing stacks required for deep system visibility.
Integrating this level of expertise instantly closes critical skill gaps, allowing your in-house team to focus on their core competency—building business-differentiating product features—rather than being mired in complex infrastructure management.
A true strategic partner doesn’t just provide staff augmentation. They deliver a managed framework, complete with architectural oversight and continuous progress monitoring, making ambitious DevOps goals achievable for any organization.
Flexible Models for Every Business Need
DevOps is not a monolithic solution. A startup building its first CI/CD pipeline has vastly different requirements from a large enterprise migrating legacy workloads to a multi-cloud environment. A rigid, one-size-fits-all engagement model is therefore ineffective.
Flexible engagement models are crucial. Whether you require strategic advisory consulting, end-to-end project delivery, or hourly capacity to augment your existing team, the right model ensures you receive the precise expertise you need, precisely when you need it. This makes world-class DevOps capabilities accessible, regardless of your organization's scale or maturity.
With a clear roadmap, elite engineering talent, and a flexible structure, achieving your DevOps goals transforms from an abstract objective into a systematic, measurable process of value creation.
DevOps Goals: Your Questions Answered
When teams begin their DevOps journey, several practical, technical questions inevitably arise. Here are direct answers to the most common ones.
What's the First Real Technical Step We Should Take?
Start with universal version control using Git. Put everything under version control: application source code, infrastructure configurations (e.g., Terraform files), pipeline definitions (e.g., Jenkinsfile), and application configuration. This establishes a single source of truth for your entire system.
This is the non-negotiable prerequisite for both Infrastructure as Code (IaC) and CI/CD. Once everything is in Git, the next logical step is to automate your build. Configure a CI server (like Jenkins or GitLab CI) to trigger on every commit, compile the code, and run unit tests. This initial automation creates immediate value and builds momentum for more advanced pipeline stages.
How Is DevOps Actually Different from Agile Day-to-Day?
They are complementary but address different scopes. Agile is a project management methodology focused on organizing the work of the development team. It uses iterative cycles (sprints) to manage complexity and adapt to changing product requirements. Its domain is primarily "plan, code, and build."
DevOps extends the principles of iterative work and fast feedback to the entire software delivery lifecycle, from a developer's commit to production operations. It encompasses Agile development but also integrates QA, security, and operations through automation. DevOps is concerned with the "test, release, deploy, and operate" phases that follow the initial build.
In technical terms: Agile optimizes the
git commitloop for developers. DevOps optimizes the entire end-to-end process fromgit pushto production monitoring and incident response.
Can a Small Startup Really Build a Full CI/CD Pipeline?
Absolutely. In fact, startups are often in the best position to do it right from the start without the burden of legacy systems or entrenched processes. Modern cloud-native CI/CD platforms have dramatically lowered the barrier to entry.
A startup can achieve significant value with a minimal viable pipeline:
- Trigger: A developer pushes code to a specific branch in a Git repository.
- Build & Test: A cloud-based CI/CD service like GitHub Actions or GitLab CI is triggered. It spins up a containerized environment, builds the application artifact (e.g., a Docker image), and runs a suite of automated tests (unit, integration).
- Deploy: Upon successful test completion, the pipeline automatically pushes the Docker image to a container registry and triggers a deployment to a container orchestration platform like Kubernetes or AWS ECS.
This entire workflow can be defined in a single YAML file and implemented in a matter of days, providing immediate ROI in the form of automated, repeatable, and low-risk deployments.
Hitting your DevOps goals comes down to having the right strategy and the right people. At OpsMoon, we connect you with the top 0.7% of global engineering talent to build, automate, and scale your infrastructure the right way. Start with a free work planning session to map out your path to success. Learn more at https://opsmoon.com.