Mastering DevOps Maturity Levels: A Technical Guide
 By opsmoon
By opsmoonDiscover the DevOps maturity levels with our technical guide. Learn how to assess your current stage and follow a roadmap to advance your capabilities.

DevOps maturity levels provide a technical roadmap for an organization's engineering journey. It’s more than adopting new tools; it’s about integrating culture, processes, and technology into a high-performance delivery system. Imagine constructing a skyscraper: you lay a rock-solid foundation with version control and CI, then add structural steel with Infrastructure as Code, and finally install intelligent systems like AIOps until the tower stands resilient and efficient.
Understanding DevOps Maturity And Why It Matters
Before you can build a roadmap, you must define DevOps maturity. It’s a framework for measuring the integration level between your development and operations teams, the depth of your automation, and how tightly your engineering efforts align with business objectives. It’s not about having the latest tools—it’s about embedding those tools into a culture of shared ownership, where every engineer is empowered to improve the entire software delivery lifecycle.
Think of it this way: owning a collection of high-performance engine parts doesn't make you a Formula 1 champion. Only when you assemble those parts into a finely tuned machine—supported by an expert pit crew and a data-driven race strategy—do you achieve peak performance. Advancing through DevOps maturity levels follows the same logic: every tool, script, and process must execute in unison, driven by teams that share a common goal of reliable, rapid delivery. For a deeper dive into these principles, check our guide on the DevOps methodology.
The Business Case For Climbing The Ladder
Why invest in this? The ROI is measured in tangible metrics and market advantage. Organizations that advance their DevOps maturity consistently outperform their competitors because they deploy faster, recover from incidents quicker, and innovate at a higher velocity.
Key performance gains include:
- Accelerated Delivery: Mature teams ship code multiple times a day, with minimal risk and maximum confidence.
- Improved Stability: Automated quality gates and end-to-end observability catch failures before they become production outages.
- Enhanced Innovation: When toil is automated away, engineers can focus on solving complex business problems and building new features.
The objective isn’t a perfect score on a maturity model; it’s about building a robust feedback loop that drives continuous improvement, making each release safer, faster, and more predictable than the last.
A Widespread And Impactful Shift
This isn’t a niche strategy—it’s the standard operating procedure for elite engineering organizations. By 2025, over 78% of organizations will have adopted DevOps practices, and 90% of Fortune 500 firms already report doing so. High-performers deploy code 46 times more often and bounce back from incidents 96 times faster than their less mature peers. You can discover more insights about these DevOps adoption statistics on devopsbay.com. In short, mastering DevOps maturity is no longer optional—it’s a critical component of technical excellence and market survival.
The Five Levels Of DevOps Maturity Explained
Knowing your current state is the first step toward optimization. DevOps maturity models provide a map for that journey. They offer a clear framework to benchmark your current operational capabilities, identify specific weaknesses in your toolchain and processes, and chart an actionable course for improvement.
Each level represents a significant leap in how you manage processes, automation, and culture. Moving through these stages isn't just about checking boxes; it's about fundamentally re-architecting how your organization builds, tests, deploys, and operates software—transforming your workflows from reactive and manual to proactive and autonomous.
This is what the starting line looks like for most companies.
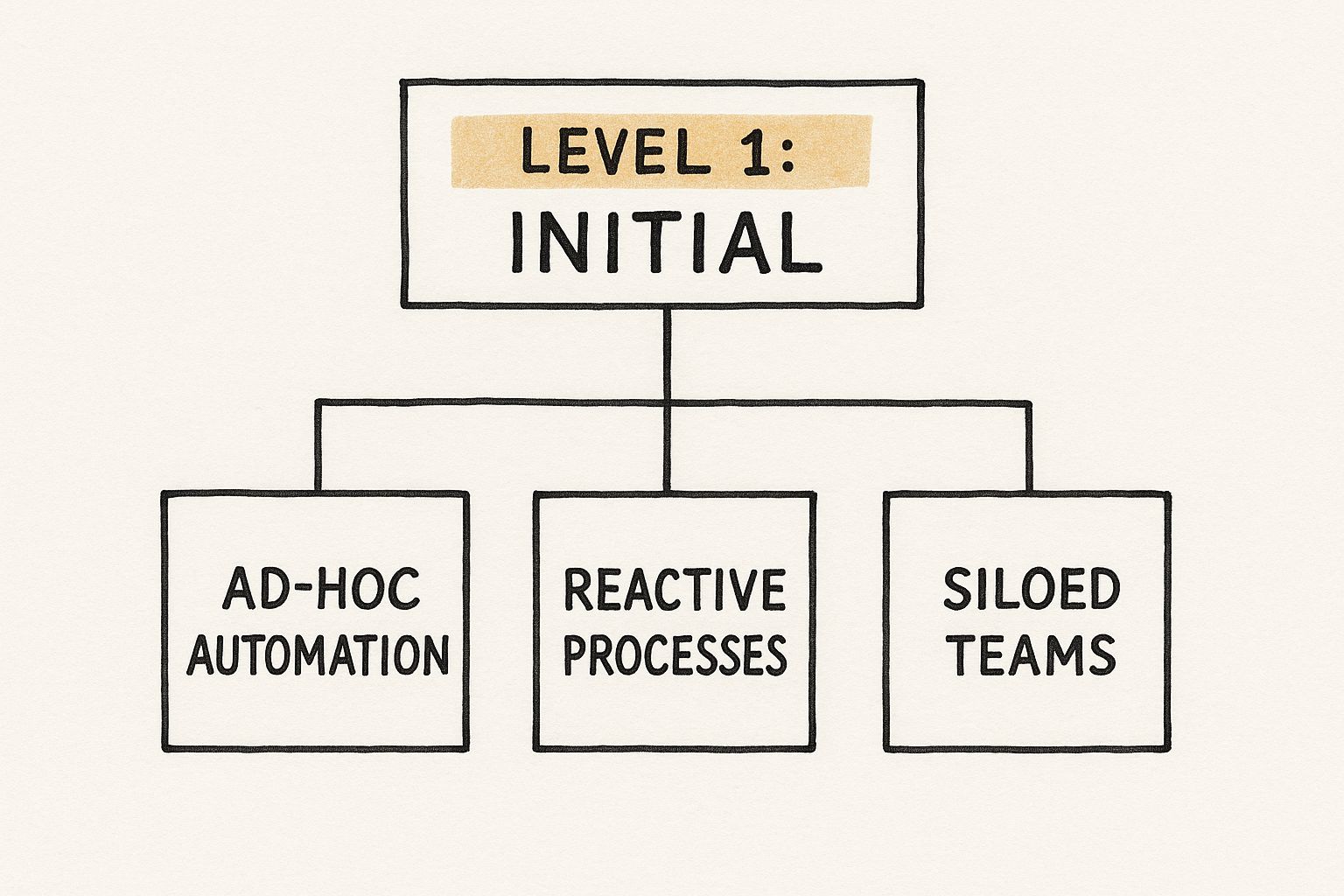
Level 1 is a world of siloed teams, ad-hoc automation, and constant firefighting. Without foundational DevOps principles, your delivery process is inefficient, unpredictable, and unstable. It's a challenging position, but it's also the starting point for a transformative journey.
Level 1: Initial
At the Initial level, processes are chaotic and unpredictable. Your development and operations teams operate in separate worlds, communicating via tickets and formal handoffs. Deployments are manual, high-risk events that often result in late nights and "heroic" efforts to fix what broke in production.
Constant firefighting is standard procedure. There is little to no automation for builds, testing, or infrastructure provisioning. Each deployment is a unique, manual procedure, making rollbacks a nightmare and downtime a frequent, unwelcome occurrence.
- Technical Markers: Manual deployments via SCP/FTP or direct SSH access. Infrastructure is "click-ops" in a cloud console, and configuration drift between environments is rampant. There's no version control for infrastructure.
- Obstacles: High Change Failure Rate (CFR), long Lead Time for Changes, and engineer burnout from repetitive, reactive work.
- Objective: The first, most critical technical goal is to establish a single source of truth by getting all application code into a centralized source control system like Git.
Level 2: Repeatable
The Repeatable stage introduces the first signs of consistency. At this point, your organization has adopted source control—typically Git—for application code. This is a monumental step, enabling change tracking and collaborative development.
Basic automation begins to appear, usually in the form of simple build or deployment scripts. An engineer might write a shell script to pull the latest code from Git and restart a service. The problem? These scripts are often brittle, undocumented, and live on a specific server or an engineer's laptop, creating new knowledge silos and single points of failure.
A classic example of Level 2 is a rudimentary Jenkins CI job that runs mvn package to build a JAR file. It's progress, but it’s a long way from a fully automated, end-to-end pipeline.
Level 3: Defined
Welcome to the Defined level. This is where DevOps practices transition from isolated experiments to standardized, organization-wide procedures. The focus shifts from fragile, ad-hoc scripts to robust, automated CI/CD pipelines that manage the entire workflow from code commit to deployment, including integrated, automated testing.
The real technical game-changer at this stage is Infrastructure as Code (IaC). Using declarative tools like Terraform or Pulumi, teams define their entire infrastructure—VPCs, subnets, servers, load balancers—in version-controlled code. This code is reviewed, tested, and applied just like application code, eliminating configuration drift and enabling reproducible environments.
By standardizing toolsets and adopting IaC, organizations create versioned, auditable, and reproducible environments that drastically boost engineering velocity and accelerate developer onboarding. This is the stage where DevOps begins to deliver significant, measurable improvements in software quality and delivery speed.
As teams integrate more technology and refine their processes, their delivery performance and agility improve dramatically. Many organizations begin at Level 1 with siloed teams and manual work, leading to high risk and slow product velocity. By Level 2, they've introduced basic workflows but still struggle to scale. It's at Level 3, with standardized tools and IaC, that they unlock real efficiency and quality gains. Industry leaders like Netflix take this even further, achieving higher maturity through scalable, autonomous systems, as detailed on appinventiv.com.
Level 4: Managed
At the Managed level, the focus moves beyond simple automation to data-driven optimization. Organizations here implement comprehensive observability stacks with tools for structured logging, metrics, and distributed tracing—think a full ELK/EFK stack, Prometheus with Grafana, and service instrumentation via OpenTelemetry. This deep, real-time visibility allows teams to diagnose and resolve issues proactively, often before customers are impacted.
Security becomes a first-class citizen through DevSecOps. Security is "shifted left," meaning it's integrated and automated throughout the pipeline. Instead of a final, manual security review, automated scans run at every stage. For example, a CI/CD pipeline built with GitHub Actions might automatically run a Static Application Security Testing (SAST) scan on every pull request, dependency vulnerability scans on every build, and Dynamic Application Security Testing (DAST) against a staging environment, catching vulnerabilities early.
Level 5: Optimizing
The final stage, Optimizing, represents the pinnacle of DevOps maturity. Here, the focus is on relentless, data-driven continuous improvement and self-optimization. Processes are not just automated; they are often autonomous, with systems capable of self-healing and predictive scaling based on real-time data.
This is the domain of AIOps (AI for IT Operations). Machine learning models analyze observability data to predict potential failures, detect subtle performance anomalies, and automatically trigger remediation actions. Imagine an AIOps system detecting a slow memory leak in a microservice, correlating it with a recent deployment, and automatically initiating a rollback or restarting the service during a low-traffic window—all without human intervention. The goal is to build an intelligent, resilient system that learns and adapts on its own.
Characteristics Of DevOps Maturity Levels
This table summarizes the key technical markers, tools, and objectives for each stage of the DevOps journey. Use it as a quick reference to benchmark your current state and identify the next technical milestone.
| Maturity Level | Key Characteristics | Example Tools & Practices | Primary Goal |
|---|---|---|---|
| Level 1: Initial | Chaotic, manual processes; siloed teams; constant firefighting; no version control for infrastructure. | Manual FTP/SSH deployments, ticketing systems (e.g., Jira for handoffs). | Establish a single source of truth with source control (Git). |
| Level 2: Repeatable | Basic source control adopted; simple, ad-hoc automation scripts; knowledge silos form around scripts. | Git, basic Jenkins jobs (build only), simple shell scripts for deployment. | Achieve consistent, repeatable builds and deployments. |
| Level 3: Defined | Standardized CI/CD pipelines; Infrastructure as Code (IaC) is implemented; automated testing is integrated. | Terraform, Pulumi, GitHub Actions, comprehensive automated testing suites. | Create reproducible, consistent environments and automated workflows. |
| Level 4: Managed | Data-driven decisions via observability; security is integrated ("shift left"); proactive monitoring and risk management. | Prometheus, Grafana, OpenTelemetry, SAST/DAST scanning tools. | Gain deep system visibility and embed security into the pipeline. |
| Level 5: Optimizing | Focus on continuous improvement; self-healing and autonomous systems; predictive analysis with AIOps. | AIOps platforms, machine learning models for anomaly detection, automated remediation. | Build a resilient, self-optimizing system with minimal human intervention. |
As you can see, the path from Level 1 to Level 5 is a gradual but powerful technical transformation—moving from simply surviving to actively thriving.
How To Assess Your Current DevOps Maturity
Before you can chart a course for improvement, you need an objective, data-driven assessment of your current state. This self-assessment is a technical audit of your people, processes, and technology, designed to provide a baseline for your roadmap. This isn't about subjective feelings; it's about a rigorous evaluation of your engineering capabilities.
This audit framework is built on three pillars that define modern software delivery: Culture, Process, and Technology. By asking specific, technical questions in each category, you can get a precise snapshot of your team's current maturity level and identify the highest-impact areas for improvement.
Evaluating The Technology Pillar
The technology pillar is the most straightforward to assess as it deals with concrete tools, configurations, and automation. The goal is to quantify the level of automation and sophistication in your tech stack. Avoid vague answers and be brutally honest.
Start by asking these technical questions:
- Infrastructure Management: Is 100% of your production infrastructure managed via a declarative Infrastructure as Code (IaC) tool like Terraform or Pulumi? If not, what percentage is still configured manually via a cloud console or SSH?
- Test Automation: What is your code coverage percentage for unit tests? Do you have an automated integration and end-to-end test suite? Crucially, do these tests run automatically on every single commit to your main development branch?
- Observability: Do you have centralized, structured logging (e.g., ELK/EFK stack), time-series metrics (e.g., Prometheus), and distributed tracing (e.g., OpenTelemetry)? Are alerts defined as code and triggered based on SLOs, or are you still manually searching logs after an incident?
- Containerization: Are your applications containerized using a tool like Docker? Are these containers orchestrated with a platform like Kubernetes to provide self-healing and automated scaling?
The answers will quickly place you on the maturity spectrum. A team manually managing servers is at a fundamentally different level than one deploying containerized applications via a GitOps workflow to a Kubernetes cluster defined in Terraform.
Analyzing The Process Pillar
The process pillar examines the "how" of your software delivery pipeline. A mature process is fully automated, predictable, and requires minimal human intervention to move code from a developer's machine to production. Manual handoffs, approval gates, and "deployment day" ceremonies are clear indicators of immaturity.
Consider these process-focused questions:
- Deployment Pipeline: Can your CI/CD pipeline deploy a single change to production with zero manual steps after a pull request is merged? Or does the process involve manual approvals, running scripts by hand, or SSHing into servers?
- Database Migrations: How are database schema changes managed? Are they automated and version-controlled using tools like Flyway or Liquibase as an integral part of the deployment pipeline, or does a DBA have to execute SQL scripts manually?
- Incident Response: When an incident occurs, do you have a defined, blameless post-mortem process to identify the systemic root cause? What is your Mean Time to Recovery (MTTR), and how quickly can you execute a rollback?
A zero-touch, fully automated deployment pipeline is the gold standard of high DevOps maturity. To objectively measure your progress, learning to effectively utilize DORA metrics will provide invaluable, data-backed insights into your pipeline's performance and stability.
Auditing The Culture Pillar
Culture is the most abstract pillar, but it is the most critical for sustained success. It encompasses collaboration, ownership, and the engineering mindset. A mature DevOps culture demolishes silos and fosters a shared sense of responsibility for the entire software lifecycle, from ideation to operation.
A team's ability to learn from failure is a direct reflection of its cultural maturity. Blameless post-mortems, where the focus is on systemic improvements rather than individual fault, are a non-negotiable trait of high-performing organizations.
To assess your cultural maturity, ask:
- Team Structure: Are development and operations separate teams that communicate primarily through tickets? Or are you organized into cross-functional product teams that own their services from "code to cloud"?
- Ownership: When a production alert fires at 3 AM, is it "ops' problem"? Or does the team that built the service own its operational health and carry the pager?
- Feedback Loops: How quickly does feedback from production—such as error rates from Sentry or performance metrics from Grafana—get back to the developers who wrote the code? Is this information easily accessible or locked away in ops-only dashboards?
Honest answers here are crucial. A team with the most advanced toolchain will ultimately fail if its culture is built on blame, finger-pointing, and siloed responsibilities. For a more structured approach, you can find helpful frameworks and checklists in our detailed guide to conducting a DevOps maturity assessment. This audit will give you the clarity you need to take your next steps.
Your Technical Roadmap For Advancing Each Level
Knowing your position on the DevOps maturity scale is one thing; building an actionable plan to advance is another. This is a technical blueprint with specific tools, configurations, and code snippets to drive forward momentum.

Think of this as a tactical playbook. Each action is a tangible step you can implement today to build momentum and deliver immediate value. While not exhaustive, it covers the critical first moves that yield the greatest impact.
From Level 1 (Initial) To Level 2 (Repeatable)
The goal here is to establish order from chaos. You must move away from manual, non-repeatable processes and create a single source of truth for your code. This is the foundational layer for all future automation.
Action 1: Lock Down Source Control With a Real Branching Strategy
This is the non-negotiable first step: all application code must live in a Git repository (GitHub, GitLab, or Bitbucket). But simply using Git isn't enough; you need a defined process.
A structured branching model is essential.
- Implement GitFlow: A well-defined model that provides a robust framework for managing feature development, releases, and hotfixes.
- Protect
main: Yourmainbranch must always represent production-ready code. Enforce this with branch protection rules, requiring pull requests and status checks before merging. No direct commits. - Use
develop: This is your primary integration branch. All feature branches are merged here before being promoted to a release. - Isolate work in
featurebranches: All new development occurs infeature/*branches created fromdevelop.
Action 2: Build Your First CI Job
With code organized, automate the build process. A Continuous Integration (CI) job eliminates manual guesswork in compiling and packaging code. It automatically validates every change pushed to your repository.
GitHub Actions is an accessible tool for this. Create a file at .github/workflows/ci.yml in your repository:
name: Basic CI Pipeline
on:
push:
branches: [ main, develop ]
pull_request:
branches: [ develop ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up JDK 17
uses: actions/setup-java@v3
with:
java-version: '17'
distribution: 'temurin'
- name: Build with Maven
run: mvn -B package --file pom.xml
This YAML configuration instructs GitHub Actions to trigger on pushes to main or develop. It checks out the code, sets up a Java 17 environment, and executes a standard Maven build. This simple automation eliminates a repetitive manual task and provides immediate feedback on code integrity.
From Level 2 (Repeatable) To Level 3 (Defined)
You have basic automation; now it's time to create standardized, reproducible systems. This means treating servers as ephemeral cattle, not indispensable pets, through containerization and Infrastructure as Code (IaC).
Action 1: Containerize Your Application with Docker
Containers solve the "it works on my machine" problem. By creating a Dockerfile in your project's root, you package your application and all its dependencies into a single, portable, and immutable artifact.
For a typical Spring Boot application, the Dockerfile is concise:
# Use an official OpenJDK runtime as a parent image
FROM openjdk:17-jdk-slim
# Add a volume pointing to /tmp
VOLUME /tmp
# Make port 8080 available to the world outside this container
EXPOSE 8080
# The application's JAR file
ARG JAR_FILE=target/*.jar
# Add the application's JAR to the container
ADD ${JAR_FILE} app.jar
# Run the JAR file
ENTRYPOINT ["java","-jar","/app.jar"]
This file defines a consistent image that runs identically wherever Docker is installed—a developer's laptop, a CI runner, or a cloud VM.
Action 2: Automate Infrastructure with Terraform
Stop provisioning infrastructure manually via cloud consoles. Define it as code. Terraform allows you to declaratively manage your infrastructure's desired state.
Start with a simple resource. Create a file named s3.tf to provision an S3 bucket in AWS for your build artifacts:
resource "aws_s3_bucket" "artifacts" {
bucket = "my-app-build-artifacts-bucket"
tags = {
Name = "Build Artifacts"
Environment = "Dev"
}
}
resource "aws_s3_bucket_versioning" "versioning_example" {
bucket = aws_s3_bucket.artifacts.id
versioning_configuration {
status = "Enabled"
}
}
This is a declaration, not a script. You check this file into Git, run terraform plan to preview changes, and terraform apply to create the bucket repeatably and reliably.
From Level 3 (Defined) To Level 4 (Managed)
Moving to Level 4 is about injecting intelligence into your processes. You'll shift from reactive to proactive by embedding security, deep observability, and data-driven reliability directly into your pipeline.
The leap to a managed state is marked by a fundamental shift from reactive problem-solving to proactive risk mitigation. By embedding security and observability directly into the pipeline, you begin to anticipate failures instead of just responding to them.
Action 1: Embed SAST with SonarQube
"Shift left" on security by finding vulnerabilities early. Integrating Static Application Security Testing (SAST) into your CI pipeline is the most effective way, and SonarQube is an industry-standard tool for this.
Add a SonarQube scan step to your GitHub Actions workflow:
- name: Build and analyze with SonarQube
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
SONAR_TOKEN: ${{ secrets.SONAR_TOKEN }}
SONAR_HOST_URL: ${{ secrets.SONAR_HOST_URL }}
run: mvn -B verify org.sonarsource.scanner.maven:sonar-maven-plugin:sonar
This step automatically analyzes code for bugs, vulnerabilities, and code smells. If the analysis fails to meet predefined quality gates, the build fails, preventing insecure code from progressing.
Action 2: Implement Distributed Tracing
In a microservices architecture, isolating the root cause of latency or errors is nearly impossible without distributed tracing. OpenTelemetry provides a vendor-neutral standard for instrumenting your code to trace a single request as it propagates through multiple services.
Adding the OpenTelemetry agent to your application's startup command is a quick win for deep visibility:
java -javaagent:path/to/opentelemetry-javaagent.jar \
-Dotel.service.name=my-app \
-Dotel.exporter.otlp.endpoint=http://collector:4317 \
-jar my-app.jar
This gives you the end-to-end visibility required for debugging and optimizing modern distributed systems. You're no longer flying blind.
Translating DevOps Wins Into Business Impact
Technical achievements like reduced build times are valuable to engineering teams, but they only become significant to the business when translated into financial impact. Advancing through DevOps maturity levels is not just about superior pipelines; it's about building a solid business case that connects engineering improvements to revenue, operational efficiency, and competitive advantage.

Every milestone on your maturity roadmap should have a direct, measurable business outcome. When you frame your team’s technical wins in terms of financial and operational metrics, you create a common language that stakeholders across the organization can understand and support.
From Automation To Accelerated Time-To-Market
Reaching Level 3 (Defined) is a pivotal moment. Your standardized CI/CD pipelines and Infrastructure as Code (IaC) are no longer just engineering conveniences; they become business accelerators.
This level of automation directly reduces your deployment lead time—the time from code commit to production deployment. New features and critical bug fixes are delivered to customers faster, shrinking your time-to-market and providing the agility to respond to market changes. When a competitor launches a new feature, a Level 3 organization can develop, test, and deploy a response in days, not months.
From Observability To Revenue Protection
By the time you reach Level 4 (Managed), you are fundamentally altering how the business safeguards its revenue streams. The deep observability gained from tools like Prometheus and OpenTelemetry dramatically reduces your Mean Time to Resolution (MTTR) during incidents.
Every minute of downtime translates directly to lost revenue, customer churn, and brand damage. By shifting from reactive firefighting to a proactive, data-driven incident response model, you are not just minimizing revenue loss from outages—you are actively protecting customer trust and brand reputation.
This transforms the operations team from a perceived cost center into a value-protection powerhouse. To see how this works in practice, check out our dedicated DevOps services, where we focus on building exactly these kinds of resilient systems.
The market has taken notice. The global DevOps market, valued at $18.4 billion in 2023, is projected to reach $25 billion by 2025. This growth is driven by the undeniable correlation between DevOps maturity and business performance.
With 80% of Global 2000 companies now operating dedicated DevOps teams, it’s evident that advancing on the maturity model has become a core component of a competitive strategy. You can dig deeper into these DevOps market trends on radixweb.com. This massive investment underscores a simple truth: mastering DevOps is a direct investment in your company’s future viability.
Common DevOps Maturity Questions Answered
As teams begin their journey up the DevOps maturity ladder, practical questions inevitably arise regarding team size, priorities, and goals.
Getting direct, experience-based answers is crucial for building a realistic and effective roadmap. Let's address some of the most common questions.
Can A Small Team Achieve A High DevOps Maturity Level?
Absolutely. DevOps maturity is a function of process and culture, not headcount. A small, agile team can often achieve Level 3 or Level 4 maturity more rapidly than a large enterprise.
The reason is a lack of organizational inertia. Small teams are not burdened by entrenched silos, legacy processes, or bureaucratic red tape.
The key is to integrate automation and a continuous improvement mindset from the outset. A startup that adopts Infrastructure as Code (IaC), containerization, and a robust CI/CD pipeline from day one can operate at a remarkably high level of maturity, even with a small engineering team.
What Is The Most Critical Factor For Improving DevOps Maturity?
While tools are essential, they are not the most critical factor. The single most important element is a culture of shared ownership reinforced by blameless post-mortems.
Without this foundation of psychological safety, even the most advanced toolchain will fail to deliver its full potential.
When developers, operations, and security engineers function as a single team with shared responsibility for the entire service lifecycle, the dynamic changes. Silos are dismantled, collaboration becomes the default, and everyone is invested in improving automation and reliability.
Technology enables higher DevOps maturity levels, but culture sustains it. An environment where failure is treated as a systemic learning opportunity—not an individual's fault—is the true engine of progress.
Is Reaching Level 5 Maturity A Necessary Goal For Everyone?
No, it is not. Level 5 (Optimizing) represents a state of hyper-automation with AI-driven, self-healing systems. For hyperscale companies like Netflix or Google, where manual intervention is operationally infeasible, this level is a necessity.
However, for most organizations, achieving a solid Level 3 (Defined) or Level 4 (Managed) is a transformative accomplishment that delivers immense business value. At these levels, you have established:
- Standardized Automation: Consistent, repeatable CI/CD pipelines for all services.
- Robust Observability: Real-time visibility into system health and performance.
- Proactive Security: Automated security checks integrated into the development pipeline.
Align your maturity goals with your specific business needs and constraints. For the vast majority of companies, Level 3 or 4 represents the optimal balance of investment and return.
How Does DevSecOps Fit Into The DevOps Maturity Model?
DevSecOps is not a separate discipline; it is an integral part of the DevOps maturity model. It embodies the principle of "shifting security left," which means integrating security practices and tools early and throughout the software development lifecycle.
At lower maturity levels, security is typically a manual, late-stage gatekeeper. As maturity increases, security becomes an automated, shared responsibility.
- At Level 3, you integrate automated Static Application Security Testing (SAST) tools directly into your CI pipeline.
- By Level 4, security is fully embedded. Your pipeline includes automated Dynamic Application Security Testing (DAST), software composition analysis (SCA) for dependencies, and continuous infrastructure compliance scanning.
High maturity means security is an automated, continuous, and ubiquitous aspect of software delivery, owned by every engineer on the team.
Ready to assess and elevate your DevOps practices? At OpsMoon, we start with a free work planning session to map your current maturity and build a clear roadmap for success. Connect with our top-tier remote engineers and start your journey today.