Mastering Understanding Distributed Systems: A Technical Guide
 By opsmoon
By opsmoonLearn understanding distributed systems with this practical guide. Discover core concepts, patterns, and solutions to build resilient, scalable software.
Understanding distributed systems requires picturing multiple, autonomous computing nodes that appear to their users as a single coherent system. Instead of a single server handling all computation, the workload is partitioned and coordinated across a network. This architectural paradigm is the backbone of modern scalable services like Netflix, Google Search, and AWS, which handle massive concurrent user loads without failure.
What Are Distributed Systems, Really?
In a distributed system, individual components—often called nodes—are distinct computers with their own local memory and CPUs. These nodes communicate by passing messages over a network to coordinate their actions and achieve a common goal. When you execute a search query on Google, you don't interact with a single monolithic server. Instead, your request is routed through a complex network of specialized services that find, rank, and render the results, all within milliseconds. To the end-user, the underlying complexity is entirely abstracted away.
The core objective is to create a system where the whole is greater than the sum of its parts—achieving levels of performance, reliability, and scale that are impossible for a single machine.
The Paradigm Shift: From Monolithic to Distributed
Historically, applications were built as a single, indivisible unit—a monolith. The entire codebase, encompassing the user interface, business logic, and data access layers, was tightly coupled and deployed as a single artifact on one server. While simple to develop initially, this architecture presents significant scaling limitations. If one component fails, the entire application crashes. To handle more load, you must add more resources (CPU, RAM) to the single server, a strategy known as vertical scaling, which has diminishing returns and becomes prohibitively expensive.
Distributed systems fundamentally invert this model by decomposing the application into smaller, independently deployable services. This brings several critical advantages:
- Scalability: When load increases, you add more commodity hardware nodes to the network (horizontal scaling). This is far more cost-effective and elastic than vertical scaling.
- Fault Tolerance: The system is designed to withstand node failures. If one node goes down, its workload is redistributed among the remaining healthy nodes, ensuring continuous operation. This is a prerequisite for high-availability systems.
- Concurrency: Independent components can process tasks in parallel, maximizing resource utilization and minimizing latency.
This architectural shift is not a choice but a necessity for building applications that can operate at a global scale and meet modern availability expectations.
A global e-commerce platform can process millions of concurrent transactions because the payment, inventory, and shipping services are distributed across thousands of servers worldwide. The failure of a server in one region has a negligible impact on the overall system's availability.
Now, let's delineate the technical distinctions between these architectural approaches.
Key Differences Between Distributed and Monolithic Systems
The following table provides a technical comparison of the architectural and operational characteristics of distributed versus monolithic systems.
| Attribute | Distributed System Approach | Monolithic System Approach |
|---|---|---|
| Architecture | Composed of small, independent, and loosely coupled services (e.g., microservices). Communication happens via well-defined APIs (REST, gRPC). | A single, tightly coupled application where components are interdependent and communicate via in-memory function calls. |
| Scalability | Horizontal scaling is the norm. You add more machines (nodes) to a cluster to handle increased load. | Vertical scaling is the primary method. You increase resources (CPU, RAM) on a single server, which has hard physical and cost limits. |
| Deployment | Services are deployed independently via automated CI/CD pipelines, allowing for rapid, targeted updates. | The entire application must be redeployed for any change, leading to infrequent, high-risk release cycles. |
| Fault Tolerance | High. Failure in one service is isolated and can be handled gracefully (e.g., via circuit breakers), preventing cascading failures. | Low. A single point of failure (e.g., an unhandled exception or memory leak) can crash the whole application. |
| Development | Teams can develop, test, and deploy services in parallel using heterogeneous technology stacks (polyglot persistence/programming). | A single, large codebase enforces a unified technology stack and creates tight coupling between development teams. |
| Complexity | High operational complexity. Requires sophisticated solutions for service discovery, load balancing, distributed tracing, and data consistency. | Simpler to develop and deploy initially due to a unified codebase and the absence of network communication overhead. |
Choosing between these two is a critical engineering decision that dictates not just the application's technical capabilities but also the organizational structure required to support it.
Mastering the Core Principles of System Design
To engineer robust distributed systems, you must move beyond high-level concepts and master the fundamental trade-offs that govern their behavior. These principles are not suggestions; they are the laws of physics for distributed computing.
The most critical of these is the CAP Theorem. Formulated by Eric Brewer, it states that any distributed data store can only provide two of the following three guarantees simultaneously: Consistency, Availability, and Partition Tolerance. A network partition occurs when a communication break between nodes splits the system into multiple subgroups.
Let's analyze these guarantees in the context of a distributed database:
- Consistency: Every read operation receives the most recent write or an error. All nodes see the same data at the same time. In a strongly consistent system, once a write completes, any subsequent read will reflect that write.
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write. The system remains operational for reads and writes even if some nodes are down.
- Partition Tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
In any real-world distributed system, network failures are inevitable. Therefore, Partition Tolerance (P) is a mandatory requirement. The CAP theorem thus forces a direct trade-off between Consistency and Availability during a network partition.
- CP (Consistency/Partition Tolerance): If a partition occurs, the system sacrifices availability to maintain consistency. It may block write operations or return errors until the partition is resolved to prevent data divergence. Example: A banking system that cannot afford to process a transaction based on stale data.
- AP (Availability/Partition Tolerance): If a partition occurs, the system sacrifices consistency to maintain availability. It continues to accept reads and writes, risking data conflicts that must be resolved later (e.g., through "last write wins" or more complex reconciliation logic). Example: A social media platform where showing a slightly outdated post is preferable to showing an error.
The map below visualizes these core trade-offs.
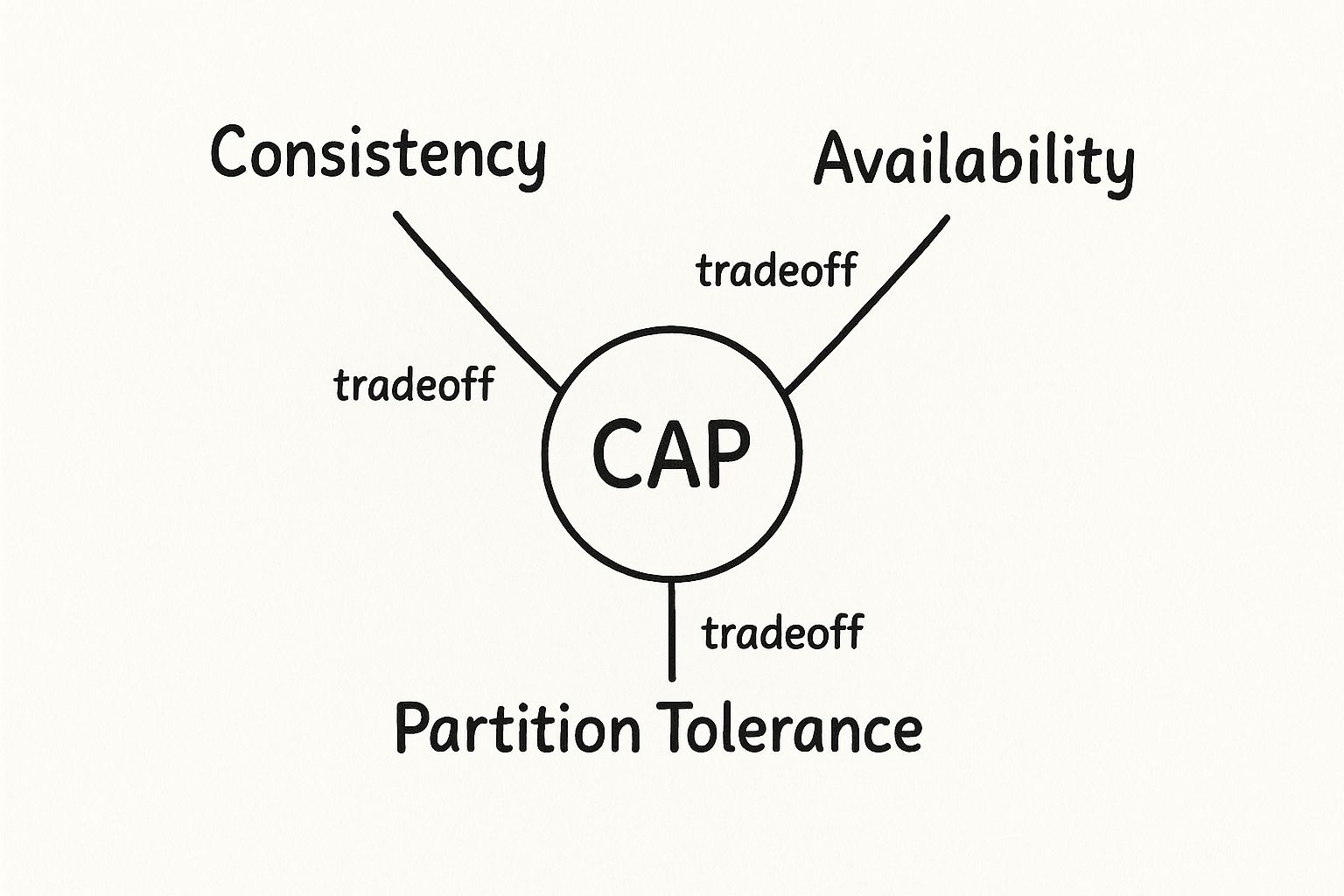
This decision between CP and AP is one of the most fundamental architectural choices an engineer makes when designing a distributed data system.
Scaling and Reliability Strategies
Beyond theory, several practical strategies are essential for building scalable and reliable systems.
- Vertical Scaling (Scaling Up): Increasing the resources (CPU, RAM, SSD) of a single node. This approach is simple but faces hard physical limits and exponential cost increases. It is often a poor choice for services expecting significant growth.
- Horizontal Scaling (Scaling Out): Distributing the load across multiple commodity machines. This is the cornerstone of modern cloud-native architecture, offering near-limitless scalability and better cost efficiency. The entire system is designed to treat nodes as ephemeral resources.
Horizontal scaling necessitates robust reliability patterns like replication and fault tolerance.
Fault tolerance is the ability of a system to continue operating correctly in the event of one or more component failures. This is achieved by designing for redundancy and eliminating single points of failure.
A common technique to achieve fault tolerance is data replication, where multiple copies of data are stored on physically separate nodes. If the primary node holding the data fails, the system can failover to a replica, ensuring both data durability and service availability.
Designing for Failure
The cardinal rule of distributed systems engineering is: failure is not an exception; it is the normal state. Networks will partition, disks will fail, and nodes will become unresponsive.
A resilient system is one that anticipates and gracefully handles these failures. A deep dive into core system design principles reveals how to architect for resilience from the ground up.
This engineering mindset is driving massive industry investment. As businesses migrate to decentralized architectures, the distributed computing market continues to expand. The global distributed control systems market is projected to reach approximately $29.37 billion by 2030. A critical aspect of this evolution is modularity; exploring concepts like modularity in Web3 system design illustrates how these principles are being applied at the cutting edge.
Choosing the Right Architectural Pattern
With a firm grasp of the core principles, the next step is to select an architectural blueprint. These patterns are not just academic exercises; they are battle-tested solutions that provide a structural framework for building scalable, maintainable, and resilient applications.
Microservices: The Modern Standard
The Microservices architectural style has emerged as the de facto standard for building complex, scalable applications. The core principle is to decompose a large monolithic application into a suite of small, independent services, each responsible for a specific business capability.
Consider a ride-sharing application like Uber, which is composed of distinct microservices:
- User Service: Manages user profiles, authentication (e.g., JWT generation/validation), and authorization.
- Trip Management Service: Handles ride requests, driver matching algorithms, and real-time location tracking via WebSockets.
- Payment Service: Integrates with payment gateways (e.g., Stripe, Adyen) to process transactions and manage billing.
- Mapping Service: Provides routing data, calculates ETAs using graph algorithms, and interacts with third-party map APIs.
Each service is independently deployable and scalable. If the mapping service experiences a surge in traffic, you can scale only that service by increasing its replica count in Kubernetes, without impacting any other part of the system. For a deeper technical dive, you can explore various microservices architecture design patterns like the Saga pattern for distributed transactions or the API Gateway for request routing.
A key advantage of microservices is technological heterogeneity. The payments team can use Java with the Spring Framework for its robust transaction management, while the mapping service team might opt for Python with libraries like NumPy and SciPy for heavy computation—all within the same logical application.
However, this autonomy introduces significant operational complexity, requiring robust solutions for service discovery, inter-service communication (e.g., gRPC vs. REST), and distributed data management.
Foundational and Niche Architectures
While microservices are popular, other architectural patterns remain highly relevant and are often superior for specific use cases.
Service-Oriented Architecture (SOA)
SOA was the precursor to microservices. It also structures applications as a collection of services, but it typically relies on a shared, centralized messaging backbone known as an Enterprise Service Bus (ESB) for communication. SOA services are often coarser-grained than microservices and may share data schemas, leading to tighter coupling. While considered more heavyweight, it laid the groundwork for modern service-based design.
Client-Server
This is the foundational architecture of the web. The Client-Server model consists of a central server that provides resources and services to multiple clients upon request. Your web browser (the client) makes HTTP requests to a web server, which processes them and returns a response. This pattern is simple and effective for many applications but can suffer from a single point of failure and scaling bottlenecks at the server.
Peer-to-Peer (P2P)
In a P2P network, there is no central server. Each node, or "peer," functions as both a client and a server, sharing resources and workloads directly with other peers. This decentralization provides extreme resilience and censorship resistance, as there is no central point to attack or shut down.
P2P architecture is crucial for:
- Blockchain and Cryptocurrencies: Bitcoin and Ethereum rely on a global P2P network of nodes to validate transactions and maintain the integrity of the distributed ledger.
- File-Sharing Systems: BitTorrent uses a P2P protocol to enable efficient distribution of large files by allowing peers to download pieces of a file from each other simultaneously.
- Real-Time Communication: Some video conferencing tools use P2P connections to establish direct media streams between participants, reducing server load and latency.
The choice of architectural pattern must be driven by the specific functional and non-functional requirements of the system, including scalability needs, fault-tolerance guarantees, and team structure.
Navigating Critical Distributed System Challenges
Transitioning from architectural theory to a production environment exposes the harsh realities of distributed computing. Many design failures stem from the Eight Fallacies of Distributed Computing—a set of erroneous assumptions engineers often make, such as "the network is reliable" or "latency is zero." Building resilient systems means architecting with the explicit assumption that these fallacies are false.
The Inevitability of Network Partitions
A network partition is one of the most common and challenging failure modes. It occurs when a network failure divides a system into two or more isolated subgroups of nodes that cannot communicate.
For instance, a network switch failure could sever the connection between two racks in a data center, or a transatlantic cable cut could isolate a European data center from its US counterpart. During a partition, the system is forced into the CAP theorem trade-off: sacrifice consistency or availability. A well-designed system will have a predefined strategy for this scenario, such as entering a read-only mode (favoring consistency) or allowing divergent writes that must be reconciled later (favoring availability).
Concurrency and the Specter of Race Conditions
Concurrency allows for high performance but introduces complex failure modes. A race condition occurs when multiple processes access and manipulate shared data concurrently, and the final outcome depends on the unpredictable timing of their execution.
Consider a financial system processing withdrawals from an account with a $100 balance:
- Process A reads the $100 balance and prepares to withdraw $80.
- Process B reads the $100 balance and prepares to withdraw $50.
Without proper concurrency control, both transactions could be approved, resulting in an overdraft. To prevent this, systems use concurrency control mechanisms:
- Pessimistic Locking: A process acquires an exclusive lock on the data, preventing other processes from accessing it until the transaction is complete.
- Optimistic Concurrency Control (OCC): Processes do not acquire locks. Instead, they read a version number along with the data. Before committing a write, the system checks if the version number has changed. If it has, the transaction is aborted and must be retried.
Concurrency bugs are notoriously difficult to debug as they are often non-deterministic. They can lead to subtle data corruption that goes unnoticed for long periods, causing significant business impact. Rigorous testing and explicit concurrency control are non-negotiable.
Securing a system also involves implementing robust data security best practices to protect data integrity from both internal bugs and external threats.
The Nightmare of Data Consistency
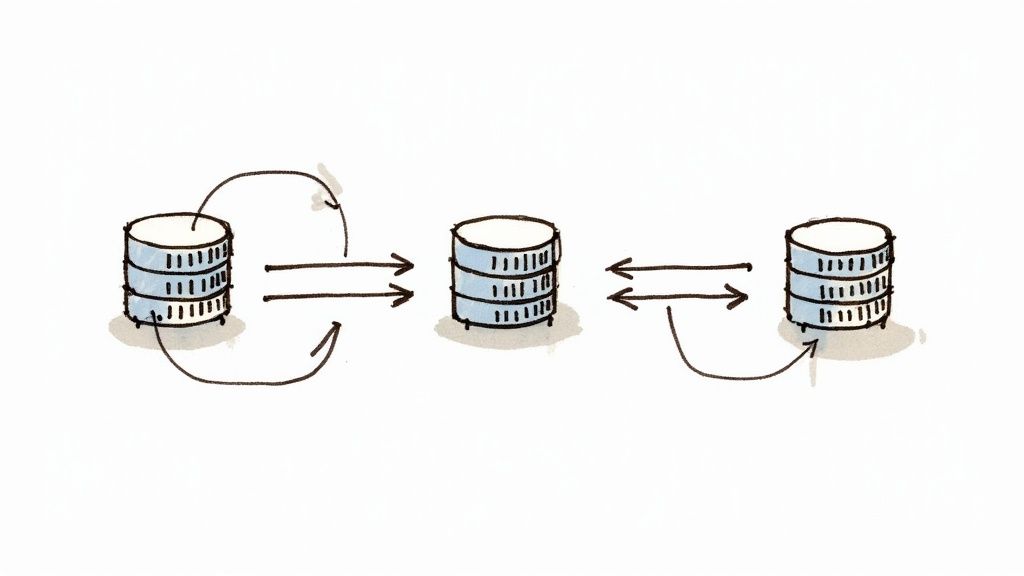
Maintaining data consistency across geographically distributed replicas is arguably the most difficult problem in distributed systems. When data is replicated to improve performance and fault tolerance, a strategy is needed to keep all copies synchronized.
Engineers must choose a consistency model that aligns with the application's requirements:
- Strong Consistency: Guarantees that any read operation will return the value from the most recent successful write. This is the easiest model for developers to reason about but often comes at the cost of higher latency and lower availability.
- Eventual Consistency: Guarantees that, if no new updates are made to a given data item, all replicas will eventually converge to the same value. This model offers high availability and low latency but requires developers to handle cases where they might read stale data.
For an e-commerce shopping cart, eventual consistency is acceptable. For a financial ledger, strong consistency is mandatory.
Common Challenges and Mitigation Strategies
The table below summarizes common distributed system challenges and their technical mitigation strategies.
| Challenge | Technical Explanation | Common Mitigation Strategy |
|---|---|---|
| Network Partition | A network failure splits the system into isolated subgroups that cannot communicate. | Implement consensus algorithms like Raft or Paxos to maintain a consistent state machine replica. Design for graceful degradation. |
| Race Condition | The outcome of an operation depends on the unpredictable sequence of concurrent events accessing shared resources. | Use locking mechanisms (pessimistic locking), optimistic concurrency control with versioning, or software transactional memory (STM). |
| Data Consistency | Replicated data across different nodes becomes out of sync due to update delays or network partitions. | Choose an appropriate consistency model (Strong vs. Eventual). Use distributed transaction protocols (e.g., Two-Phase Commit) or compensatory patterns like Sagas. |
| Observability | A single request can traverse dozens of services, making it extremely difficult to trace errors or performance bottlenecks. | Implement distributed tracing with tools like Jaeger or OpenTelemetry. Centralize logs and metrics in platforms like Prometheus and Grafana. |
Mastering distributed systems means understanding these problems and their associated trade-offs, and then selecting the appropriate solution for the specific problem domain.
Applying DevOps and Observability
Designing a distributed system is only half the battle; operating it reliably at scale is a distinct and equally complex challenge. This is where DevOps culture and observability tooling become indispensable. Without a rigorous, automated approach to deployment, monitoring, and incident response, the complexity of a distributed architecture becomes unmanageable.
DevOps is a cultural philosophy that merges software development (Dev) and IT operations (Ops). It emphasizes automation, collaboration, and a shared responsibility for the reliability of the production environment. This tight feedback loop is critical for managing the inherent fragility of distributed systems.
Safe and Frequent Deployments with CI/CD
In a monolithic architecture, deployments are often large, infrequent, and high-risk events. In a microservices architecture, the goal is to enable small, frequent, and low-risk deployments of individual services. This is achieved through a mature Continuous Integration/Continuous Deployment (CI/CD) pipeline.
A typical CI/CD pipeline automates the entire software delivery process:
- Build: Source code is compiled, and a deployable artifact (e.g., a Docker container image) is created.
- Test: A comprehensive suite of automated tests (unit, integration, contract, and end-to-end tests) is executed to validate the change.
- Deploy: Upon successful testing, the artifact is deployed to production using progressive delivery strategies like canary releases (directing a small percentage of traffic to the new version) or blue-green deployments (deploying to a parallel production environment and then switching traffic).
This automation minimizes human error and empowers teams to deploy changes confidently multiple times per day. If a deployment introduces a bug, it is isolated to a single service and can be quickly rolled back without affecting the entire system.
Understanding System Behavior with Observability
When a single user request traverses multiple services, traditional monitoring (e.g., checking CPU and memory) is insufficient for debugging. Observability provides deeper insights into a system's internal state by analyzing its outputs. It is built upon three core pillars:
Observability is the practice of instrumenting code to emit signals that allow you to ask arbitrary questions about your system's behavior without needing to ship new code to answer them. It's how you debug "unknown unknowns."
- Logs: Timestamped, immutable records of discrete events. Structured logging (e.g., JSON format) is crucial for efficient parsing and querying.
- Metrics: A numerical representation of data measured over time intervals (e.g., request latency, error rates, queue depth). Metrics are aggregated and stored in a time-series database for dashboarding and alerting.
- Traces: A representation of the end-to-end journey of a single request as it propagates through multiple services. A trace is composed of spans, each representing a single unit of work, allowing engineers to pinpoint performance bottlenecks and sources of error.
Together, these pillars provide a comprehensive, multi-faceted view of the system's health and behavior. To go deeper, explore the essential site reliability engineering principles that formalize these practices.
Ensuring Consistency with Infrastructure as Code
Manually configuring the infrastructure for hundreds of services is error-prone and unscalable. Infrastructure as Code (IaC) is the practice of managing and provisioning infrastructure through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools.
Tools like Terraform, Ansible, or AWS CloudFormation allow you to define your entire infrastructure—servers, load balancers, databases, and network rules—in declarative code. This code is stored in version control, just like application code.
The benefits are transformative:
- Repeatability: You can deterministically create identical environments for development, staging, and production from the same source code.
- Consistency: IaC eliminates "configuration drift," ensuring that production environments do not diverge from their intended state over time.
- Auditability: Every change to the infrastructure is captured in the version control history, providing a clear and immutable audit trail.
This programmatic control is fundamental to operating complex distributed systems. The reliability and automation provided by IaC are major drivers of adoption, with the market for distributed control systems in industrial automation reaching about $20.46 billion in 2024 and continuing to grow.
Your Next Steps in System Design
We have covered a significant amount of technical ground, from the theoretical limits defined by the CAP Theorem to the operational realities of CI/CD and observability. The single most important takeaway is that every decision in distributed systems is a trade-off. There is no universally correct architecture, only the optimal architecture for a given set of constraints and requirements.
The most effective way to deepen your understanding is to combine theoretical study with hands-on implementation. Reading the seminal academic papers that defined the field provides the "why," while working with open-source tools provides the "how."
Essential Reading and Projects
To bridge the gap between theory and practice, start with these foundational resources.
- Google's Foundational Papers: These papers are not just historical artifacts; they are the blueprints for modern large-scale data processing. The MapReduce paper introduced a programming model for processing vast datasets in parallel, while the Spanner paper details how Google built a globally distributed database with transactional consistency.
- Key Open-Source Projects: Reading about a concept is one thing; implementing it is another. Gain practical experience by working with these cornerstone technologies.
- Kubernetes: The de facto standard for container orchestration. Set up a local cluster using Minikube or Kind. Deploy a multi-service application and experiment with concepts like Service Discovery, ConfigMaps, and StatefulSets. This will provide invaluable hands-on experience with managing distributed workloads.
- Apache Kafka: A distributed event streaming platform. Build a simple producer-consumer application to understand how asynchronous, event-driven communication can decouple services and improve system resilience.
The goal is not merely to learn the APIs of Kubernetes or Kafka. It is to understand the fundamental problems they were designed to solve. Why does Kubernetes require an etcd cluster? Why is Kafka's core abstraction an immutable, replicated commit log? Answering these questions signifies a shift from a user to an architect.
Applying Concepts in Your Own Work
You don't need to work at a large tech company to apply these principles. Start with your current projects.
The next time you architect a feature, explicitly consider failure modes. What happens if this database call times out? What is the impact if this downstream service is unavailable? Implement a simple retry mechanism with exponential backoff or add a circuit breaker. This mindset of "designing for failure" is the first and most critical step toward building robust, production-ready distributed systems.
Frequently Asked Questions
As you delve into distributed systems, certain conceptual hurdles frequently appear. Here are clear, technical answers to some of the most common questions.
What Is the Difference Between Distributed Systems and Microservices?
This is a frequent point of confusion. The relationship is one of concept and implementation.
A distributed system is a broad computer science term for any system in which components located on networked computers communicate and coordinate their actions by passing messages to one another.
Microservices is a specific architectural style—an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
Therefore, a microservices-based application is, by definition, a distributed system. However, not all distributed systems follow a microservices architecture (e.g., a distributed database like Cassandra or a P2P network).
How Do Systems Stay Consistent Without a Central Clock?
Synchronizing state without a single, global source of time is a fundamental challenge. Physical clocks on different machines drift, making it impossible to rely on wall-clock time to determine the exact order of events across a network.
To solve this, distributed systems use logical clocks, such as Lamport Timestamps or Vector Clocks. These algorithms do not track real time; instead, they generate a sequence of numbers to establish a partial or total ordering of events based on the causal relationship ("happened-before") between them.
For state machine replication—ensuring all nodes agree on a sequence of operations—systems use consensus algorithms. Protocols like Paxos or its more understandable counterpart, Raft, provide a mathematically proven mechanism for a cluster of nodes to agree on a value or a state transition, even in the presence of network delays and node failures.
Key Takeaway: Distributed systems achieve order and consistency not through synchronized physical clocks, but through logical clocks that track causality and consensus protocols that enable collective agreement on state.
When Should I Not Use a Distributed System?
While powerful, a distributed architecture introduces significant complexity and operational overhead. It is often the wrong choice in the following scenarios:
- You're at small-scale or building an MVP. A monolithic application is vastly simpler to develop, test, deploy, and debug. Don't prematurely optimize for a scale you don't have.
- Your application requires complex ACID transactions. Implementing atomic, multi-step transactions across multiple services is extremely difficult and often requires complex patterns like Sagas, which provide eventual consistency rather than the strict atomicity of a relational database.
- Your team lacks the necessary operational expertise. Managing a distributed system requires a deep understanding of networking, container orchestration, CI/CD, and observability. A small team can easily be overwhelmed by the operational burden, distracting from core product development.
Adopting a distributed architecture is a strategic decision. You are trading developmental simplicity for scalability, resilience, and organizational autonomy. Always evaluate this trade-off critically against your actual business and technical requirements.
Feeling overwhelmed by the complexity of managing your own distributed systems? OpsMoon connects you with the world's top DevOps engineers to design, build, and operate scalable infrastructure. Get a free work planning session to map out your CI/CD, Kubernetes, and observability needs. Find your expert at https://opsmoon.com.