A Technical Guide to System Design Principles
 By opsmoon
By opsmoonA technical guide to essential system design principles. Learn to build scalable, reliable, and high-performance software with practical examples.
System design principles are the architectural blueprints for engineering software that is not just functional, but also reliable, scalable, and maintainable. They provide a foundational framework for making critical architectural decisions—the ones that determine whether a system can handle current load and is prepared for future scale.
Why System Design Principles Matter
Building a large-scale software system without a solid architectural plan is like starting a skyscraper with no blueprint. You wouldn't just stack I-beams and hope for structural integrity. You'd begin with a detailed architectural plan accounting for load-bearing walls, material stress limits, and occupancy capacity. System design principles serve the same purpose for software architecture.
Without this upfront design, a system might function under initial test conditions but will inevitably fail under a production load spike or during a feature expansion. A well-designed architecture must anticipate high traffic, component failures, and data growth from day one. This foresight is what separates a robust, long-lasting application from one that accrues massive technical debt and requires constant, costly re-engineering.
The Foundation of Engineering Trade-Offs
At its core, system design is a series of strategic engineering trade-offs. As engineers, we constantly balance competing non-functional requirements to meet specific business objectives. These principles provide the technical vocabulary and analytical framework to make these decisions methodically.
Common trade-offs you will encounter include:
- Consistency vs. Availability (CAP Theorem): Do you require every node in a distributed system to return the most recently written data (strong consistency), as in a banking transaction? Or is it more critical for the system to remain operational for reads and writes, even if some data is momentarily stale (eventual consistency), as in a social media feed?
- Latency vs. Throughput: Is the primary goal to minimize the response time for a single request (low latency), crucial for real-time applications like online gaming? Or is the system designed to process a high volume of operations per second (high throughput), as required for a batch data processing pipeline?
- Performance vs. Cost: How much infrastructure will you provision to achieve sub-millisecond latency? Can you leverage cheaper, less performant hardware and optimize at the software level to manage operational expenditure (OpEx)?
A well-designed system is not one that excels in every metric. It's an architecture that is intentionally optimized for its specific use case. These principles help us avoid over-engineering and allocate resources where they deliver the most impact.
From Theory to Practical Application
These are not abstract academic concepts; they are practical tools that prevent catastrophic failures and mitigate technical debt. For example, a failure to design for scalability can lead to cascading failures during a high-traffic event like a Black Friday sale, resulting in significant revenue loss. Similarly, poor reliability planning can cause extended outages that erode user trust and violate Service Level Agreements (SLAs).
To see these concepts in action, it's useful to review system integration best practices. Correctly applying core design principles ensures that as you compose individual services, they form a cohesive, resilient, and observable system. Ultimately, these foundational rules elevate software development from a reactive process to a predictable engineering discipline, ensuring the systems you build are not just functional today but durable and adaptable for years to come.
Designing Systems That Grow With Demand
When designing a system, scalability is a primary non-functional requirement. It is the measure of a system's ability to handle a growing amount of work by adding resources. This isn't just about surviving an ephemeral traffic spike; it's about architecting for sustained growth from inception.
An application that performs well for 100 concurrent users may experience exponential performance degradation and collapse entirely at 101 if not designed to scale. There are two fundamental approaches to scaling a system, each with distinct technical trade-offs. Understanding these is critical for building a robust architecture.
Vertical Scaling: The Powerful Giant
Vertical scaling (scaling up) is the process of increasing the capacity of a single machine. This involves adding more resources like CPU cores, RAM, or faster storage (e.g., upgrading from HDDs to NVMe SSDs).
This approach offers simplicity. It often requires no changes to the application code, as the underlying operating system and hardware handle the resource increase.
For example, if a monolithic database server is CPU-bound, you could upgrade its EC2 instance type from a t3.large (2 vCPUs, 8GB RAM) to an m5.4xlarge (16 vCPUs, 64GB RAM). This results in an immediate performance boost for query processing.
However, vertical scaling has inherent limitations. There is an upper physical limit to the resources you can add to a single node. Furthermore, the cost of high-end hardware increases exponentially, leading to diminishing returns. This approach also introduces a single point of failure (SPOF).
Horizontal Scaling: The Coordinated Army
Horizontal scaling (scaling out) involves adding more machines to a resource pool and distributing the load among them. Instead of one powerful server, you use a fleet of less powerful, commodity servers working in concert.
This is the dominant strategy for nearly all large-scale web applications. It offers near-linear scalability and is more cost-effective. You can leverage dozens of cheaper, commodity machines instead of a single, expensive mainframe-class server.
Horizontal scaling provides inherent fault tolerance. If one node in the cluster fails, a load balancer can redirect its traffic to healthy nodes. When a single vertically scaled machine fails, the entire system is down.
Coordinating this "army" of servers is where advanced system design patterns come into play. You need specific strategies to distribute workloads and partition data across the cluster.
How to Make Horizontal Scaling Actually Work
Implementing horizontal scaling requires several key architectural components. Each solves a specific problem that arises in a distributed environment.
Here are the essential strategies:
- Load Balancing: A load balancer (e.g., Nginx, HAProxy, or a cloud provider's ALB/NLB) acts as a reverse proxy, distributing network traffic across multiple backend servers. Common algorithms include Round Robin (sequential distribution), Least Connections (sends traffic to the server with the fewest active connections), and IP Hash (ensures a client's requests always go to the same server).
- Database Sharding: A single database instance will eventually become a performance bottleneck. Sharding partitions a database horizontally, breaking a large table into smaller, more manageable pieces called shards. Each shard is hosted on a separate database server, distributing the read/write load. For example, you might shard a
userstable based on a hash of theuser_id. - Caching: Caching is a critical performance optimization. By storing frequently accessed data in a fast, in-memory data store like Redis or Memcached, you can serve read requests without hitting the primary database. This drastically reduces latency and alleviates load on persistent storage.
- Stateless Architectures: In a stateless architecture, the server handling a request does not store any client session data between requests. All necessary state is passed from the client with each request or stored in a shared external data store (like a distributed cache or database). This is crucial for horizontal scaling, as it allows any server in the pool to process any request, making it trivial to add or remove servers dynamically.
Modern cloud platforms provide managed services that simplify these patterns. For instance, understanding autoscaling in Kubernetes demonstrates how to programmatically scale a service's replica count based on real-time metrics like CPU utilization, creating a truly elastic and cost-efficient system.
Engineering for Uptime and Fault Tolerance
While scalability prepares a system for growth, fault tolerance prepares it for failure. In any complex distributed system, component failures are not an anomaly; they are an inevitability. Network partitions, disk failures, and software bugs will occur.
Engineering for uptime means designing an architecture that can withstand component failures and continue to operate, perhaps at a degraded capacity, but without total collapse. This is akin to a multi-engine aircraft designed to remain airborne even after an engine failure.
This introduces two key system design principles: reliability and availability. Reliability is a measure of a system's probability of performing its required function correctly for a specified period under stated conditions. Availability is the percentage of time a system is operational and accessible to users, typically measured by uptime.
Availability is quantified in "nines." A system with 99.9% availability ("three nines") is down for approximately 8.77 hours per year. A "five nines" (99.999%) system is down for only 5.26 minutes per year—a significant increase in operational excellence and user experience.
Redundancy: The Heart of Fault Tolerance
The foundational strategy for achieving high availability is redundancy. This involves provisioning duplicate components that can take over if a primary component fails, thus eliminating any single point of failure (SPOF).
There are two primary models for implementing redundancy:
- Active-Passive: In this configuration, one component (active) handles the entire load while a secondary component (passive) remains on standby. The passive node is continuously monitored via a health check (heartbeat). If the active node fails, a failover mechanism reroutes traffic to the passive node, which is then promoted to active.
- Active-Active: In this model, two or more components are simultaneously active, handling traffic and sharing the load. This not only provides redundancy but also improves scalability. If one node fails, its traffic is distributed among the remaining healthy nodes.
The active-active approach offers better resource utilization and a seamless failover but is more complex to implement, often requiring sophisticated state synchronization. Active-passive is simpler and can be more cost-effective if the standby resources can be kept in a "warm" or "cold" state until needed.
Preventing a Domino Effect: Cascading Failures
Redundancy alone is insufficient. A failure in one microservice can trigger a chain reaction, overwhelming dependent services and causing a system-wide outage known as a "cascading failure."
A key mitigation technique is graceful degradation. If a non-critical downstream service (e.g., a recommendation engine) becomes unavailable, the primary application should handle the failure gracefully. Instead of returning a 500 error, an e-commerce site might simply hide the recommendation section, preserving the core functionality of browsing and purchasing.
Another critical pattern is the circuit breaker. When a client service detects that calls to a downstream service are repeatedly failing, the circuit breaker "trips," immediately failing subsequent calls for a configured timeout period without making a network request. This prevents the client from wasting resources on calls destined to fail and gives the failing service time to recover. Libraries like Resilience4j provide robust implementations of this pattern for JVM-based applications.
These techniques are central to the discipline of ensuring operational stability. For a deeper dive, explore Site Reliability Engineering principles.
By combining redundancy with failure isolation patterns, you can engineer systems that are not just robust, but truly resilient, capable of withstanding unexpected failures while maintaining service availability.
Optimizing for Speed and Resource Efficiency
Performance is a critical feature. A system with high latency will result in poor user experience and can directly impact business metrics. Optimizing for speed and resource efficiency involves designing an application that is responsive and cost-effective to operate.
This requires balancing two key performance metrics: Latency, the time required to complete a single operation (e.g., an API request), and Throughput, the number of operations the system can process per unit of time (e.g., requests per second).
A real-time trading application must prioritize ultra-low latency. A data analytics pipeline, conversely, prioritizes high throughput to process terabytes of data. Optimizing for one often comes at the expense of the other. A system with low latency but poor throughput will feel responsive to a single user but will fail under concurrent load.
Technical Strategies for Peak Performance
Achieving high performance requires a multi-faceted approach, applying optimizations across the entire technology stack.
A fundamental starting point is database indexing. An index is a data structure (typically a B-Tree) that improves the speed of data retrieval operations on a database table. Without an index, the database must perform a full table scan to find a specific row. With a well-designed index on query predicates, the database can perform a much faster seek operation, reducing query times from seconds to milliseconds.
This chart illustrates a common architectural trade-off. The choice between consistency and availability has a direct impact on system performance.
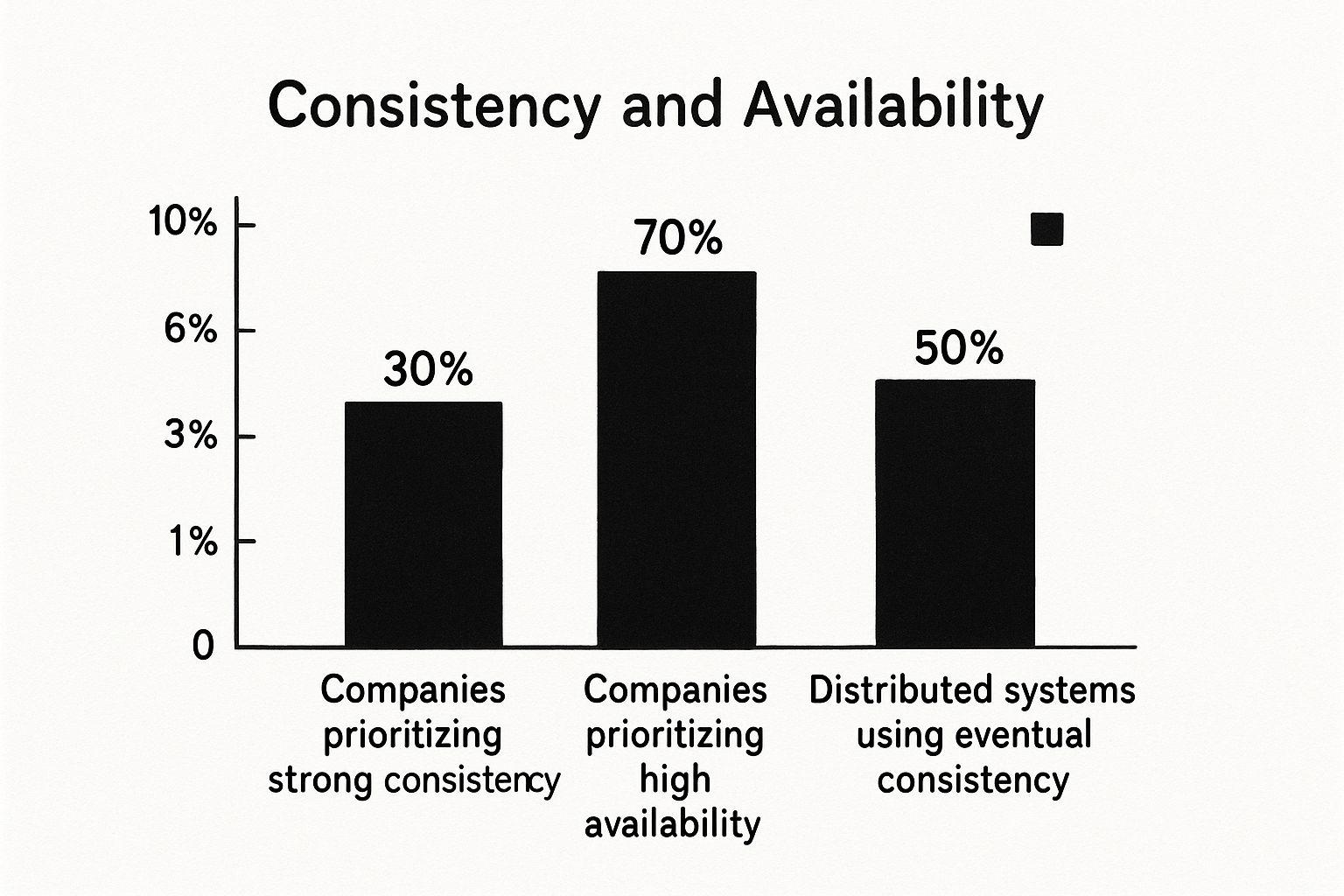
The strong preference for availability (70%) over strict consistency (30%) reflects a common engineering decision: accepting eventual consistency to achieve lower latency and higher system responsiveness, as strong consistency often requires synchronous cross-node coordination, which introduces latency.
Reducing Latency with Caching and Queues
For a globally distributed user base, network latency caused by the physical distance between users and servers is a major performance bottleneck. A Content Delivery Network (CDN) mitigates this by caching static assets (images, videos, JavaScript, CSS) in a geographically distributed network of edge servers.
When a user in Europe requests an image, it is served from a local edge server instead of fetching it from the origin server in North America, drastically reducing Round-Trip Time (RTT).
However, some operations are inherently time-consuming, such as video transcoding or generating a complex report. Executing these tasks synchronously would block the main application thread, leading to a poor user experience.
Asynchronous communication is the solution for handling long-running tasks. You decouple the initial request from the final execution by offloading the work to a background process. The main application remains responsive, immediately acknowledging the request.
This is typically implemented using message queues. A user's request is serialized into a "message" and published to a queue managed by a message broker like Apache Kafka or RabbitMQ. Independent worker services subscribe to this queue, consume messages, and execute the tasks asynchronously. This decoupling is a cornerstone of modern, resilient architectures, allowing a system to absorb large traffic bursts without performance degradation.
Different latency problems require different solutions. Here is a comparison of common techniques.
Comparing Latency Optimization Techniques
| Technique | Primary Use Case | Key Benefit | Common Trade-Off |
|---|---|---|---|
| Caching | Storing frequently accessed data in memory to avoid slower database or API calls. | Drastically reduces read latency for common queries. | Cache invalidation logic can be complex; potential for stale data. |
| CDN | Serving static assets (images, CSS) from geographically distributed servers. | Minimizes network latency for users far from the primary server. | Primarily for static content; dynamic content requires other solutions like edge computing. |
| Database Indexing | Speeding up data retrieval operations in a database. | Exponentially faster query performance for read-heavy workloads. | Increases write latency (indexes must be updated) and consumes storage space. |
| Load Balancing | Distributing incoming traffic across multiple servers. | Prevents any single server from becoming a bottleneck, improving throughput. | Adds a layer of complexity and a potential point of failure to the infrastructure. |
| Asynchronous Processing | Offloading long-running tasks to background workers using message queues. | Keeps the primary application responsive by not blocking user requests. | Introduces eventual consistency; results are not immediate, requiring a callback mechanism. |
By layering these techniques, you engineer a system that is not only perceived as fast by end-users but also operates efficiently, optimizing resource utilization and controlling operational costs.
Building Maintainable Systems with Microservices
A system that is performant and scalable is of little value if it cannot be maintained. Maintainability is a critical, though often overlooked, system design principle that dictates how easily a system can be modified, debugged, and evolved over time.
For decades, the standard architectural pattern was the monolith, where all application functionality is contained within a single, tightly coupled codebase and deployed as a single unit. While simple to develop initially, monoliths become increasingly fragile and difficult to change as they grow in complexity.
A minor change in one module can have unintended consequences across the entire application, making deployments high-risk events. This inherent rigidity led to the development of more modular architectural styles.
The Rise of Modular Design
The modern solution is to adopt a modular approach, breaking down a large application into a collection of small, independent, and loosely coupled services. This is the core concept behind a microservices architecture.
Each service is responsible for a specific business capability, has its own codebase, and is deployed independently. This architectural style has become a de facto industry standard. A 2023 survey indicated that 82% of organizations have adopted microservices, compared to older modular patterns like service-oriented architecture (SOA), used by only 35%.
Core Principles of Modular Systems
To successfully implement a microservices architecture, two foundational principles must be adhered to:
-
Loose Coupling: Services should be as independent as possible. A change to the internal implementation of the
user-profileservice should not require a corresponding change and redeployment of thepayment-processingservice. This separation allows autonomous teams to develop, test, and deploy their services independently, increasing development velocity. -
High Cohesion: Each service should have a single, well-defined responsibility. The
inventoryservice should manage inventory state and nothing else—not user reviews or shipping logistics. This principle, also known as the Single Responsibility Principle, ensures that each service is easier to understand, maintain, and test.
The combination of loose coupling and high cohesion creates a system with strong fault isolation. A bug or performance issue in one service is contained within that service's boundary, preventing a cascading failure across the entire application. This modularity is a prerequisite for building resilient systems.
Communication Is Key
For distributed services to function as a cohesive application, they require well-defined and reliable communication protocols. APIs (Application Programming Interfaces) serve as the contract between services.
Each microservice exposes a stable API (e.g., REST, gRPC) that defines how other services can interact with it. As long as this API contract is maintained, the internal implementation of a service can be completely refactored or even rewritten in a different programming language without impacting its consumers. For example, a notification service could be migrated from Python to Go, and as long as its API remains backward compatible, no other service needs to be modified.
Mastering these concepts is fundamental to building adaptable systems and is a key strategy for managing technical debt. To explore this further, see our detailed guide on microservices architecture design patterns.
Let's move from theory to a practical design exercise.
Applying system design principles to a concrete problem is the best way to solidify understanding. Let's walk through the architectural design of a URL shortening service, similar to Bitly or TinyURL. The system must accept a long URL and generate a short, unique alias, which, when accessed, redirects the user to the original destination URL.
Nailing Down the Requirements and Constraints
A precise definition of functional and non-functional requirements is the critical first step. This process informs all subsequent architectural trade-offs.
Functional Requirements:
- Given a long URL, the service must generate a unique short URL.
- Accessing a short URL must result in an HTTP redirect to the original long URL.
- Users can optionally provide a custom short alias.
Non-Functional Requirements:
- High Availability: The service must be highly available. Link redirection is a critical path; downtime renders all generated links useless. Target: 99.99% availability.
- Low Latency: Redirects must be near-instantaneous. Target: p99 latency of under 100ms.
- Scalability: The system must scale to handle a high volume of writes (link creation) and an even higher volume of reads (redirections).
Back-of-the-Envelope Calculations
Before architecting, we perform rough calculations to estimate the scale of the system. This helps in selecting appropriate technologies and design patterns.
Assume the service needs to handle 100 million new URL creations per month.
- Write Traffic (Creations): 100 million URLs / (30 days * 24 hours/day * 3600 sec/hour) ≈ 40 writes/sec.
- Read Traffic (Redirections): A common read-to-write ratio for such a service is 10:1. This gives us 400 reads/sec.
- Storage Estimation: Assume links are stored for 5 years. Total URLs = 100 million/month * 12 months/year * 5 years = 6 billion records. If each record (short key, long URL, metadata) is approximately 500 bytes, total storage needed = 6 billion * 500 bytes = 3 TB.
These estimates confirm that a single-server architecture is not viable. A distributed system is required.
Sketching Out the High-Level Architecture
Now we can apply our principles to a high-level design.
-
Load Balancer: An Application Load Balancer (ALB) will be the entry point. It will terminate TLS and distribute incoming HTTP requests across a pool of application servers. This is fundamental for horizontal scaling and high availability; if a server instance fails, the ALB's health checks will detect it and redirect traffic to healthy instances.
-
Stateless Application Servers: Behind the ALB will be a fleet of identical web servers running in an auto-scaling group. They must be stateless. All state (URL mappings) will be persisted in a database or cache. This allows us to scale the application tier horizontally by adding or removing servers based on traffic load without impacting user sessions.
-
Distributed Database: A single relational database would not handle 3 TB of data and 400+ reads/sec efficiently. A distributed NoSQL key-value store like Amazon DynamoDB or Apache Cassandra is a better fit. The short URL alias can serve as the primary key, providing O(1) lookup complexity for reads.
The database should be partitioned (sharded) across multiple nodes. This distributes the read/write load, preventing hotspots and enabling the database to scale horizontally alongside the application tier.
- Caching Layer: The 10:1 read-to-write ratio strongly indicates that a caching layer will yield significant performance improvements. We will deploy a distributed cache like Redis or Memcached using a write-through caching strategy. When a redirect request for a short URL arrives, the application first checks the cache. A cache hit returns the long URL immediately, avoiding a database query. Given our latency target, this is non-negotiable.
Common Questions About System Design
Even with a solid grasp of core concepts, applying system design principles to real-world scenarios raises practical questions. This section addresses common challenges engineers face when translating theory into practice.
Where Should I Start with a New Design?
The most effective starting point is a rigorous analysis of the system's requirements, not a diagramming tool. You must differentiate between functional requirements (what the system does) and non-functional requirements (how the system behaves under load and failure conditions).
Before designing, conduct a requirements-gathering session with stakeholders to clarify:
- What is the core business problem? Define the primary use cases and user stories.
- What are the non-functional constraints? Quantify the SLOs for availability (e.g., 99.95%), latency (e.g., p99 response time < 200ms), and data consistency (e.g., strong vs. eventual).
- What is the expected scale? Perform back-of-the-envelope calculations to estimate requests per second (RPS), data storage volume, and the read/write ratio.
This foundational work dictates every subsequent architectural decision. A system designed for high-availability reads will have a vastly different architecture from one prioritizing transactional consistency.
How Do I Choose the Right Database?
Database selection is a critical architectural decision with long-term consequences. The "right" choice is entirely dependent on the system's specific access patterns and consistency requirements.
A simplified decision framework:
- SQL (Relational): Choose for applications requiring ACID guarantees and where data has a well-defined, relational schema. Ideal for financial systems, e-commerce order management, and systems where data integrity is paramount.
- NoSQL (Non-Relational): Choose for systems requiring high scalability, flexible data models, and high throughput. Key-value stores are excellent for caching and session management. Document stores are well-suited for content management. Wide-column stores are built for large-scale analytical workloads.
The modern best practice is often polyglot persistence, which involves using multiple database technologies within a single application, selecting the best tool for each specific job. For example, use a SQL database for core user data but a time-series database for monitoring metrics.
Can a System Be Perfectly Scalable and Reliable?
No. In practice, achieving perfect scalability and reliability is impossible due to physical constraints and prohibitive costs. The goal is not abstract perfection but engineering a system that meets its defined Service Level Objectives (SLOs) within business and budget constraints.
Achieving "five nines" (99.999%) availability is a monumental engineering effort requiring redundancy at every layer of the stack, automated failover, and extensive monitoring, which incurs significant cost and operational complexity. Perfection is an asymptote; each additional "nine" of availability costs exponentially more to achieve. The engineering task is to build a system that meets the required level of resilience for its use case, not a theoretical ideal.
Ready to implement these principles with an expert team? OpsMoon connects you with the top 0.7% of remote DevOps engineers to build, scale, and manage your infrastructure. We provide a clear roadmap and flexible engagement models to accelerate your software delivery. Start with a free work planning session to map out your next project.