Mastering Microservices Architecture Design Patterns: A Technical Guide
 By opsmoon
By opsmoonDiscover key microservices architecture design patterns to optimize system decomposition, integration, and data handling for robust applications.
When first approaching microservices, the associated design patterns can seem abstract. However, these are not just academic theories. They are field-tested blueprints designed to solve the recurring, practical challenges encountered when architecting applications from small, independent services. This guide provides a technical deep-dive into these essential patterns, which serve as the foundational toolkit for any architect transitioning from a monolithic system. These patterns offer proven solutions to critical issues like data consistency, service communication, and system decomposition.
From Monolith to Microservices: A Practical Blueprint
A traditional monolithic application functions like a single, large-scale factory where every process—user authentication, payment processing, inventory management—is part of one giant, interconnected assembly line. This is a monolithic architecture.
Initially, it’s straightforward to build. However, significant problems emerge as the system grows. A failure in one component can halt the entire factory. Scaling up requires duplicating the entire infrastructure, an inefficient and costly process.
In contrast, a microservices architecture operates like a network of small, specialized workshops. Each workshop is independent and excels at a single function: one handles payments, another manages user profiles, and a third oversees product catalogs. These services are loosely coupled but communicate through well-defined APIs to accomplish business goals.
This distributed model offers significant technical advantages:
- Independent Scalability: If the payment service experiences high load, only that specific service needs to be scaled. Other services remain unaffected, optimizing resource utilization.
- Enhanced Resilience (Fault Isolation): A failure in one service is contained and does not cascade to bring down the entire application. The other services continue to operate, isolating the fault.
- Technological Freedom (Polyglot Architecture): Each service team can select the optimal technology stack for their specific requirements. For instance, the inventory service might use Java and a relational database, while a machine learning-based recommendation engine could be built with Python and a graph database.
This architectural freedom, however, introduces new complexities. How do independent services communicate reliably? How do you guarantee atomicity for transactions that span multiple services, like a customer order that must update payment, inventory, and shipping systems? This is precisely where microservices architecture design patterns become indispensable.
These patterns represent the collective wisdom from countless real-world distributed systems implementations. They are the standardized schematics for addressing classic challenges such as service discovery, data management, and fault tolerance.
Think of them as the essential blueprints for constructing a robust and efficient network of services. They guide critical architectural decisions: how to decompose a monolith, how services should communicate, and how to maintain data integrity in a distributed environment.
Attempting to build a microservices-based system without these patterns is akin to constructing a skyscraper without architectural plans—it predisposes the project to common, solved problems that can be avoided. This guide provides a technical exploration of these foundational patterns, positioning them as a prerequisite for success.
Let’s begin with the first critical step: strategically breaking down a monolithic application.
How to Strategically Decompose a Monolith
The initial and most critical phase in migrating to microservices is the strategic decomposition of the existing monolith. This process must be deliberate and rooted in a deep understanding of the business domain. A misstep here can lead to a “distributed monolith”—a system with all the operational complexity of microservices but none of the architectural benefits.
Two primary patterns have become industry standards for guiding this decomposition: Decomposition by Business Capability and Decomposition by Subdomain. These patterns offer different lenses through which to analyze an application and draw logical service boundaries. The increasing adoption of these patterns is a key driver behind the projected growth of the microservices market from $6.27 billion to nearly $15.97 billion by 2029, as organizations migrate to scalable, cloud-native systems. You can read the full market research report for detailed market analysis.
Decomposition by Business Capability
This pattern is the most direct and often the best starting point. The core principle is to model services around what the business does, not how the existing software is structured. A business capability represents a high-level function that generates value.
Consider a standard e-commerce platform. Its business capabilities can be clearly identified:
- Order Management: Encapsulates all logic for order creation, tracking, and fulfillment.
- Product Catalog Management: Manages product information, pricing, images, and categorization.
- User Authentication: Handles user accounts, credentials, and access control.
- Payment Processing: Integrates with payment gateways to handle financial transactions.
Each of these capabilities is a strong candidate for a dedicated microservice. The ‘Order Management’ service would own all code and data related to orders. This approach is highly effective because it aligns the software architecture with the business structure, fostering clear ownership and accountability for development teams.
The objective is to design services that are highly cohesive. This means that all code within a service is focused on a single, well-defined purpose. Achieving high cohesion naturally leads to loose coupling between services. For example, the ‘Product Catalog’ service should not have any knowledge of the internal implementation details of the ‘Payment Processing’ service.
Decomposition by Subdomain
While business capabilities provide a strong starting point, complex domains often require a more granular analysis. This is where Domain-Driven Design (DDD) and the Decomposition by Subdomain pattern become critical. DDD is an approach to software development that emphasizes building a rich, shared understanding of the business domain.
In DDD, a large business domain is broken down into smaller subdomains. Returning to our e-commerce example, the ‘Order Management’ capability can be further analyzed to reveal distinct subdomains:
- Core Subdomain: This is the unique, strategic part of the business that provides a competitive advantage. For our e-commerce application, this might be a
Pricing & Promotions Enginethat executes complex, dynamic discount logic. This subdomain warrants the most significant investment and top engineering talent. - Supporting Subdomain: These are necessary functions that support the core, but are not themselves key differentiators.
Order Fulfillment, which involves generating shipping labels and coordinating with warehouse logistics, is a prime example. It must be reliable but can be implemented with standard solutions. - Generic Subdomain: These are solved problems that are not specific to the business.
User Authenticationis a classic example. It is often more strategic to integrate a third-party Identity-as-a-Service (IDaaS) solution than to build this functionality from scratch.
This pattern enforces strategic prioritization. The Pricing & Promotions core subdomain would likely become a highly optimized, custom-built microservice. The Order Fulfillment service might be a simpler, more straightforward application. User Authentication could be offloaded entirely to an external provider.
Effectively managing a heterogeneous environment of custom, simple, and third-party services is a central challenge of modern software delivery. A mature DevOps practice is non-negotiable. To enhance your team’s ability to manage this complexity, engaging specialized DevOps services can provide the necessary expertise and acceleration.
Choosing Your Service Communication Patterns
Once the monolith is decomposed into a set of independent services, the next architectural challenge is to define how these services will communicate. The choice of communication patterns directly impacts system performance, fault tolerance, and operational complexity. This decision represents a fundamental fork in the road for any microservices project, with the primary choice being between synchronous and asynchronous communication paradigms.
Synchronous vs. Asynchronous Communication
Let’s dissect these two styles with a technical focus.
Synchronous communication operates on a request/response model. Service A initiates a request to Service B and then blocks its execution, waiting for a response.
This direct, blocking model is implemented using protocols like HTTP for REST APIs or binary protocols like gRPC. It is intuitive and relatively simple to implement for state-dependent interactions. For example, a User Profile service must synchronously call an Authentication service to validate a user’s credentials before returning sensitive profile data.
However, this simplicity comes at the cost of temporal coupling. If the Authentication service is latent or unavailable, the User Profile service is blocked. This can lead to thread pool exhaustion and trigger cascading failures that propagate through the system, impacting overall availability.
Asynchronous communication, in contrast, uses a message-based, non-blocking model. Service A sends a message to an intermediary, typically a message broker like RabbitMQ or a distributed log like Apache Kafka, and can immediately continue its own processing without waiting for a response. Service B later consumes the message from the broker, processes it, and may publish a response message.
This pattern completely decouples the services in time and space. An Order Processing service can publish an OrderPlaced event without any knowledge of the consumers. The Inventory, Shipping, and Notifications services can all subscribe to this event and react independently and in parallel. This architecture is inherently resilient and scalable. If the Shipping service is offline, messages queue up in the broker, ready for processing when the service recovers. No data is lost, and the producing service remains unaffected.
To clarify the technical trade-offs, consider this comparison:
Synchronous vs Asynchronous Communication Patterns
| Attribute | Synchronous (e.g., gRPC, REST API Call) | Asynchronous (e.g., Message Queue, Event Stream) |
|---|---|---|
| Interaction Style | Request-Response. Caller blocks until a response is received. | Event-based/Message-based. Sender is non-blocking. |
| Coupling | High (temporal coupling). Services must be available simultaneously. | Low. Services are decoupled by a message broker intermediary. |
| Latency | Lower for a single request, but can create high end-to-end latency in long chains. | Higher initial latency due to broker overhead, but improves overall system throughput and responsiveness. |
| Resilience | Lower. A failure in a downstream service directly impacts the caller. | Higher. Consumer failures are isolated and do not impact the producer. |
| Complexity | Simpler to implement and debug for direct, point-to-point interactions. | More complex due to the need for a message broker and handling eventual consistency. |
| Ideal Use Cases | Real-time queries requiring immediate response (e.g., data validation, user authentication). | Long-running jobs, parallel processing, event-driven workflows (e.g., order processing, notifications). |
In practice, most sophisticated systems employ a hybrid approach, using synchronous communication for real-time queries and asynchronous patterns for workflows that demand resilience and scalability.
The API Gateway and Aggregator Patterns
As the number of microservices increases, allowing client applications (e.g., web frontends, mobile apps) to communicate directly with dozens of individual services becomes unmanageable. This creates a “chatty” interface, makes the client complex and brittle, and exposes internal service endpoints.
The API Gateway pattern addresses this by providing a single, unified entry point for all client requests.
Instead of clients invoking multiple service endpoints, they make a single request to the API Gateway. The gateway acts as a reverse proxy, routing requests to the appropriate downstream services. It also centralizes cross-cutting concerns such as authentication/authorization, SSL termination, request logging, and rate limiting. This simplifies client code, enhances security, and encapsulates the internal system architecture.
The Aggregator pattern often works in conjunction with the API Gateway. Consider a product detail page that requires data from the Product Catalog, Inventory, and Reviews services. The Aggregator is a component (which can be implemented within the gateway or as a standalone service) that receives the initial client request, fans out multiple requests to the downstream services, and then aggregates their responses into a single, composite data transfer object for the client. This offloads the orchestration logic from the client to the server side.
Building Resilience with the Circuit Breaker Pattern
In a distributed system, transient failures are inevitable. A service may become overloaded, a network connection may be lost, or a database may become unresponsive. The Circuit Breaker pattern is a critical mechanism for preventing these transient issues from causing cascading failures.
The diagram below illustrates the state machine of a circuit breaker, which functions like an electrical switch to halt requests to a failing service.
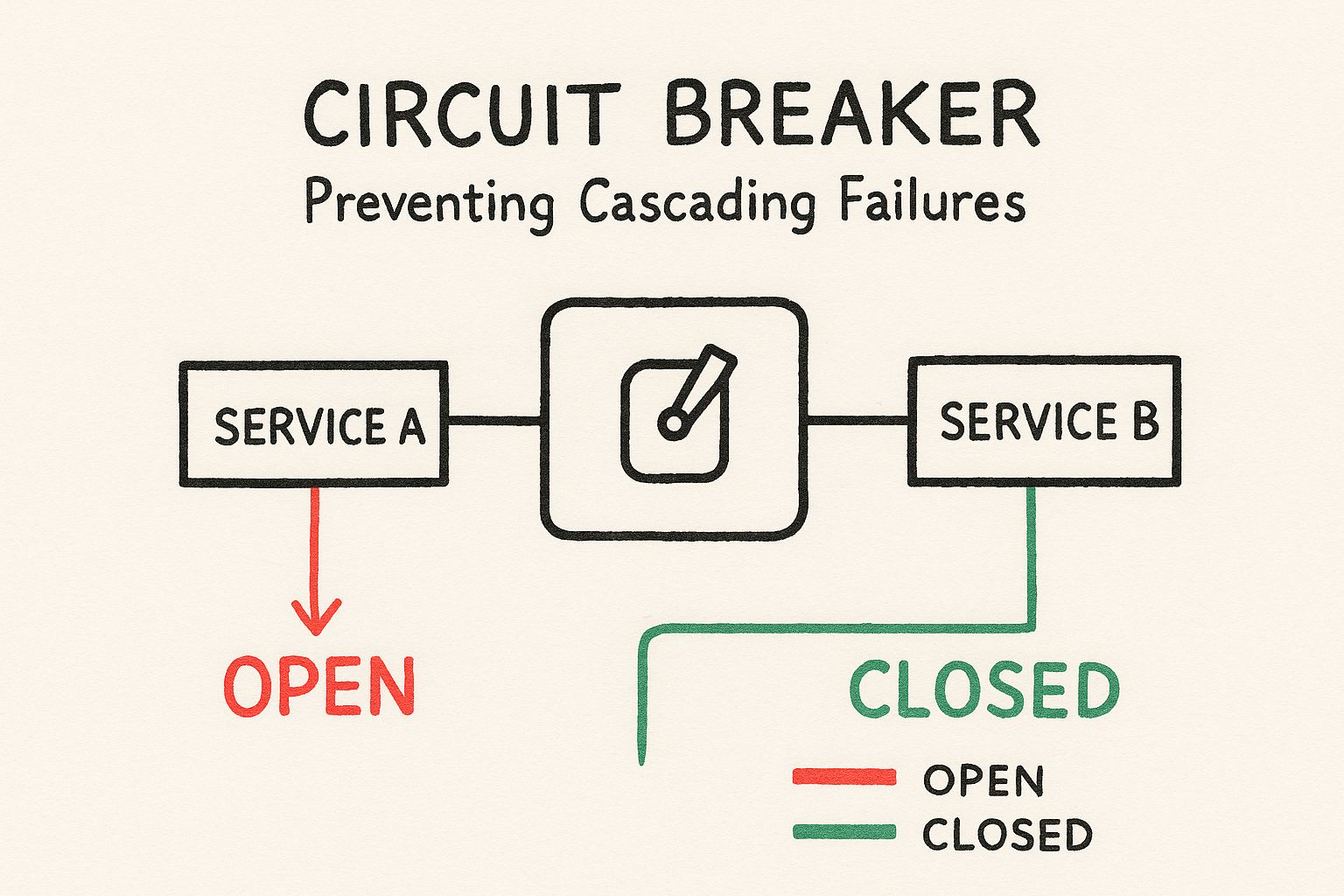
A circuit breaker wraps a potentially failing operation, such as a network call, and monitors it for failures. It operates in three states:
- Closed: The default state. Requests are passed through to the downstream service. The breaker monitors the number of failures. If failures exceed a configured threshold, it transitions to the “Open” state.
- Open: The circuit is “tripped.” For a configured timeout period, all subsequent calls to the protected service fail immediately without being executed. This “fail-fast” behavior prevents the calling service from wasting resources on doomed requests and gives the failing service time to recover.
- Half-Open: After the timeout expires, the breaker transitions to this state. It allows a single test request to pass through to the downstream service. If this request succeeds, the breaker transitions back to “Closed.” If it fails, the breaker returns to “Open,” restarting the timeout.
This pattern is non-negotiable for building fault-tolerant systems. When a Payment Processing service starts timing out, the circuit breaker in the Order service will trip, preventing a backlog of failed payments from crashing the checkout flow and instead providing immediate, graceful feedback to the user. Implementing this level of resilience is often coupled with containerization technologies. For a deeper exploration of the tools involved, consult our guide to Docker services.
Solving Data Management in Distributed Systems
Having defined service boundaries and communication protocols, we now face the most formidable challenge in microservices architecture: data management. In a monolith, a single, shared database provides transactional integrity (ACID) and simplifies data access. In a distributed system, a shared database becomes a major bottleneck and violates the core principle of service autonomy. The following patterns provide battle-tested strategies for managing data consistency and performance in a distributed environment.
Adopting the Database per Service Pattern
The foundational pattern for data management is Database per Service. This principle is non-negotiable: each microservice must own its own private data store, and no other service is allowed to access it directly. The Order service has its own database, the Customer service has its database, and the Inventory service has its own. This is a strict enforcement of encapsulation at the data level.
This strict boundary grants genuine loose coupling and autonomy. The Inventory team can refactor their database schema, migrate from a relational database to a NoSQL store, or optimize query performance without coordinating with or impacting the Order team.
This separation, however, introduces a critical challenge: how to execute business transactions that span multiple services and how to perform queries that join data from different services.
Executing Distributed Transactions with the Saga Pattern
Consider a customer placing an order—a business transaction that requires coordinated updates across multiple services:
- The
Orderservice must create an order record. - The
Paymentservice must authorize the payment. - The
Inventoryservice must reserve the products.
Since a traditional distributed transaction (2PC) is not viable in a high-throughput microservices environment due to its locking behavior, the event-driven Saga pattern is employed to manage long-lived transactions.
A Saga is a sequence of local transactions. Each local transaction updates the database within a single service and then publishes an event that triggers the next local transaction in the saga. If any local transaction fails, the saga executes a series of compensating transactions to semantically roll back the preceding changes, thus maintaining data consistency.
Let’s model the e-commerce order using a Choreographic Saga:
- Step 1 (Transaction): The
Orderservice executes a local transaction to create the order with a “PENDING” status and publishes anOrderCreatedevent. - Step 2 (Transaction): The
Paymentservice, subscribed toOrderCreated, processes the payment. On success, it publishes aPaymentSucceededevent. - Step 3 (Transaction): The
Inventoryservice, subscribed toPaymentSucceeded, reserves the stock and publishesItemsReserved. - Step 4 (Finalization): The
Orderservice, subscribed toItemsReserved, updates the order status to “CONFIRMED.”
Failure Scenario: If the inventory reservation fails, the Inventory service publishes an InventoryReservationFailed event. The Payment service, subscribed to this event, executes a compensating transaction to refund the payment and publishes a PaymentRefunded event. The Order service then updates the order status to “FAILED.” This choreography achieves eventual consistency without the need for distributed locks.
Optimizing Reads with CQRS
The Saga pattern is highly effective for managing state changes (writes), but querying data across multiple service-owned databases can be complex and inefficient. The Command Query Responsibility Segregation (CQRS) pattern addresses this by separating the models used for updating data (Commands) from the models used for reading data (Queries).
- Commands: These represent intents to change system state (e.g.,
CreateOrder,UpdateInventory). They are processed by the write-side of the application, which typically uses the domain model and handles transactional logic via Sagas. - Queries: These are requests for data that do not alter system state (e.g.,
GetOrderHistory,ViewProductDetails).
CQRS allows you to create highly optimized, denormalized read models (often called “materialized views”) in a separate database. For example, as an order progresses, the Order service can publish events. A dedicated reporting service can subscribe to these events and build a pre-computed view specifically designed for displaying a customer’s order history page. This eliminates the need for complex, real-time joins across multiple service APIs, dramatically improving query performance.
The need for robust data management patterns like CQRS is especially pronounced in industries like BFSI (Banking, Financial Services, and Insurance), where on-premises deployments and strict data controls are paramount. This sector’s rapid adoption of microservices underscores the demand for scalable and secure architectures. You can learn more about microservices market trends and industry-specific adoption rates.
With the system decomposed and data management strategies in place, the next challenge is visibility. A distributed system can quickly become an opaque “black box” without proper instrumentation.
When a single request propagates through multiple services, diagnosing failures or performance bottlenecks becomes exceptionally difficult. Observability is therefore not an optional feature but a foundational requirement for operating a microservices architecture in production.
Observability is the ability to ask arbitrary questions about your system’s state—”Why was this user’s request slow yesterday?” or “Which service is experiencing the highest error rate?”—without needing to deploy new code. This is achieved through three interconnected pillars that provide a comprehensive view of system behavior.
The Three Pillars of Observability
True system insight is derived from the correlation of logs, traces, and metrics (or health checks). Each provides a different perspective, and together they create a complete operational picture.
- Log Aggregation: Each microservice generates logs. In a distributed environment, these logs are scattered. The Log Aggregation pattern centralizes these logs into a single, searchable repository.
- Distributed Tracing: When a request traverses multiple services, Distributed Tracing provides a causal chain, stitching together the entire request lifecycle as it moves through the architecture.
- Health Check APIs: A Health Check API is a simple endpoint exposed by a service to report its operational status, enabling automated health monitoring and self-healing.
Implementing Log Aggregation
Without centralized logging, debugging is a prohibitively manual and time-consuming process. Imagine an outage requiring an engineer to SSH into numerous containers and manually search log files with grep. Log Aggregation solves this by creating a unified logging pipeline.
A standard and powerful implementation is the ELK Stack: Elasticsearch, Logstash, and Kibana.
- Logstash (or alternatives like Fluentd) acts as the data collection agent, pulling logs from all services.
- Elasticsearch is a distributed search and analytics engine that indexes the logs for fast, full-text search.
- Kibana provides a web-based UI for querying, visualizing, and creating dashboards from the log data.
This setup enables engineers to search for all log entries associated with a specific user ID or error code across the entire system in seconds.
Technical Deep Dive on Distributed Tracing
While logs provide detail about events within a single service, traces tell the story of a request across the entire system. Tracing is essential for diagnosing latency bottlenecks and understanding complex failure modes. The core mechanism is context propagation using a correlation ID (or trace ID).
When a request first enters the system (e.g., at the API Gateway), a unique trace ID is generated. This ID is then propagated in the headers (e.g., as a X-Request-ID or using W3C Trace Context headers) of every subsequent downstream call made as part of that request’s execution path.
By ensuring that every log message generated for that request, across every service, is annotated with this trace ID, you can filter aggregated logs to instantly reconstruct the complete end-to-end request flow. This is fundamental for latency analysis and debugging distributed workflows.
Why Health Check APIs Are Crucial
A Health Check API is a dedicated endpoint, such as /health or /livez, exposed by a service. While simple, it is a critical component for automated orchestration platforms like Kubernetes.
Kubernetes can be configured with a “liveness probe” to periodically ping this endpoint. If the endpoint fails to respond or returns a non-200 status code, Kubernetes deems the instance unhealthy. It will then automatically terminate that instance and attempt to restart it. A separate “readiness probe” can be used to determine if a service instance is ready to accept traffic, preventing traffic from being routed to a service that is still initializing.
This automated self-healing is the bedrock of building a highly available system. It also integrates directly with service discovery mechanisms to ensure that the service mesh only routes traffic to healthy and ready instances.
Building a truly observable system requires more than just implementing tools; it requires a cultural shift. For a deeper dive into the strategies and technologies involved, explore our comprehensive guide to achieving true system observability.
Mastering Advanced Coordination Patterns
As a microservices architecture scales from a few services to an ecosystem of dozens or hundreds, the complexity of inter-service coordination grows exponentially. Simple request/response communication is insufficient for managing complex, multi-service business workflows. Advanced patterns for service discovery and workflow management become essential for building a resilient and scalable system.
Service Discovery: Client-Side vs. Server-Side
In a dynamic environment where service instances are ephemeral, hard-coding IP addresses or hostnames is not viable. Services require a dynamic mechanism to locate each other. This is the role of Service Discovery, which is typically implemented in one of two ways.
- Client-Side Discovery: In this pattern, the client service is responsible for discovering the network location of a target service. It queries a central Service Registry (e.g., Consul, Eureka) to obtain a list of available and healthy instances for the target service. The client then uses its own client-side load-balancing algorithm (e.g., round-robin, least connections) to select an instance and make a request.
- Server-Side Discovery: This pattern abstracts the discovery logic from the client. The client makes a request to a well-known endpoint, such as a load balancer or a service mesh proxy. This intermediary component then queries the Service Registry, selects a healthy target instance, and forwards the request. This is the model used by container orchestrators like Kubernetes, where services are exposed via a stable virtual IP.
While client-side discovery offers greater flexibility and control, server-side discovery is generally preferred in modern architectures as it simplifies client code and centralizes routing logic, making the overall system easier to manage and maintain.
The Great Debate: Orchestration vs. Choreography
When managing a business process that spans multiple services, two distinct coordination patterns emerge: orchestration and choreography. The analogy of a symphony orchestra versus a jazz ensemble effectively illustrates the difference.
Orchestration is analogous to a symphony orchestra. A central “conductor” service, the orchestrator, explicitly directs the workflow. It makes direct, synchronous calls to each participating service in a predefined sequence. For an order fulfillment process, the orchestrator would first call the Payment service, then the Inventory service, and finally the Shipping service.
This pattern provides centralized control and visibility. The entire business logic is encapsulated in one place, which can simplify debugging and process monitoring. However, the orchestrator becomes a central point of failure and a potential performance bottleneck. It also creates tight coupling between the orchestrator and the participating services.
The market reflects the importance of this pattern; the microservices orchestration market was valued at $4.7 billion and is projected to reach $72.3 billion by 2037. This growth highlights the critical need for centralized workflow management in large-scale enterprise systems. You can discover more insights about the orchestration market growth on Research Nester.
Choreography, in contrast, is like a jazz ensemble. There is no central conductor. Each service is an autonomous agent that listens for events and reacts accordingly. An Order service does not command other services; it simply publishes an OrderPlaced event. The Payment and Inventory services are independently subscribed to this event and execute their respective tasks upon receiving it.
This event-driven approach results in a highly decoupled, resilient, and scalable system. Services can be added, removed, or updated without disrupting the overall process. The trade-off is that the business logic becomes distributed and implicit, making end-to-end process monitoring and debugging significantly more challenging.
Even with a solid grasp of these patterns, practical implementation often raises recurring questions. Let’s address some of the most common challenges.
How Big Should a Microservice Be?
There is no definitive answer based on lines of code or team size. The most effective heuristic is to size a service according to the Single Responsibility Principle, bounded by a single business capability. A microservice should be large enough to encapsulate a complete business function but small enough to be owned and maintained by a single, small team (the “two-pizza team” rule).
The architectural goals are high cohesion and loose coupling. All code within a service should be tightly focused on its specific domain (high cohesion). Its dependencies on other services should be minimal and restricted to well-defined, asynchronous APIs (loose coupling). If a service becomes responsible for multiple, unrelated business functions or requires deep knowledge of other services’ internals, it is a strong candidate for decomposition.
When Is It a Bad Idea to Use Microservices?
Microservices are not a universal solution. Adopting them prematurely or for the wrong reasons can lead to significant operational overhead and complexity. They are generally a poor choice for:
- Early-stage products and startups: When iterating rapidly to find product-market fit, the simplicity and development velocity of a monolith are significant advantages. Avoid premature optimization.
- Small, simple applications: The operational overhead of managing a distributed system (CI/CD, monitoring, service discovery) outweighs the benefits for applications with limited functional scope.
- Teams without mature DevOps capabilities: Microservices require a high degree of automation for testing, deployment, and operations. Without a strong CI/CD pipeline and robust observability practices, a microservices architecture will be unmanageable.
The migration to microservices should be a strategic response to concrete problems, such as scaling bottlenecks, slow development cycles, or organizational constraints in a large monolithic system.
Can Services Share a Database?
While technically possible, sharing a database between services is a critical anti-pattern that violates the core principles of microservice architecture. Shared databases create tight, implicit coupling at the data layer, completely undermining the autonomy of services. If the Order service and the Inventory service share a database, a schema change required by the Inventory team could instantly break the Order service, causing a major production incident.
The correct approach is the strict enforcement of the Database per Service pattern. Each service encapsulates its own private database. If the Order service needs to check stock levels, it must query the Inventory service via its public API. It is not permitted to access the inventory database directly. This enforces clean boundaries and enables independent evolution of services.
Ready to build a resilient, scalable system without all the guesswork? OpsMoon connects you with the top 0.7% of remote DevOps engineers who can implement these patterns the right way. From Kubernetes orchestration to CI/CD pipelines, we provide the expert talent and strategic guidance to accelerate your software delivery. Get a free DevOps work plan and expert match today.