Mastering the Software Release Lifecycle: A Technical Guide
 By opsmoon
By opsmoonUnlock the power of the software release lifecycle with a guide on planning, testing, deployment, and optimization to deliver quality software faster.
The software release lifecycle (SRLC) is the orchestrated sequence of stages that transforms a software concept into a deployed application and manages its evolution until retirement. It's the engineering blueprint that standardizes planning, development, testing, deployment, and maintenance to ensure quality, predictability, and velocity. Without a formalized SRLC, development descends into chaos, resulting in unpredictable delivery timelines and poor-quality releases.
Understanding The Software Release Lifecycle Framework
Attempting to build a complex application without a structured lifecycle is a recipe for failure. It leads to siloed development efforts, haphazard feature implementation, and inadequate testing, culminating in a buggy, high-stress launch.
The software release lifecycle (SRLC) provides the architectural governance to prevent this chaos. It ensures every engineer, product manager, and stakeholder understands the build plan, the timeline, and how individual contributions integrate into the final product.
A robust SRLC is not just about process; it's a technical framework that aligns engineering execution with business objectives. It establishes a predictable cadence for development, which is critical for accurate resource allocation, managing stakeholder expectations, and mitigating the last-minute risks that derail releases. The SRLC is the foundational discipline for any team aiming to ship high-quality software consistently and reliably. To learn more about how this structure drives real results, you can explore how a structured SRLC drives efficiency on rtslabs.com.
The High-Level Flow of a Release
At its core, the software release lifecycle follows a logical, top-down progression. It begins with high-level strategic planning and drills down into the technical specifics of implementation and execution. Each phase is a prerequisite for the next, creating a clear, auditable path from concept to a production system.
This diagram illustrates the hierarchical flow—from strategic planning, through iterative development, and culminating in a controlled deployment.
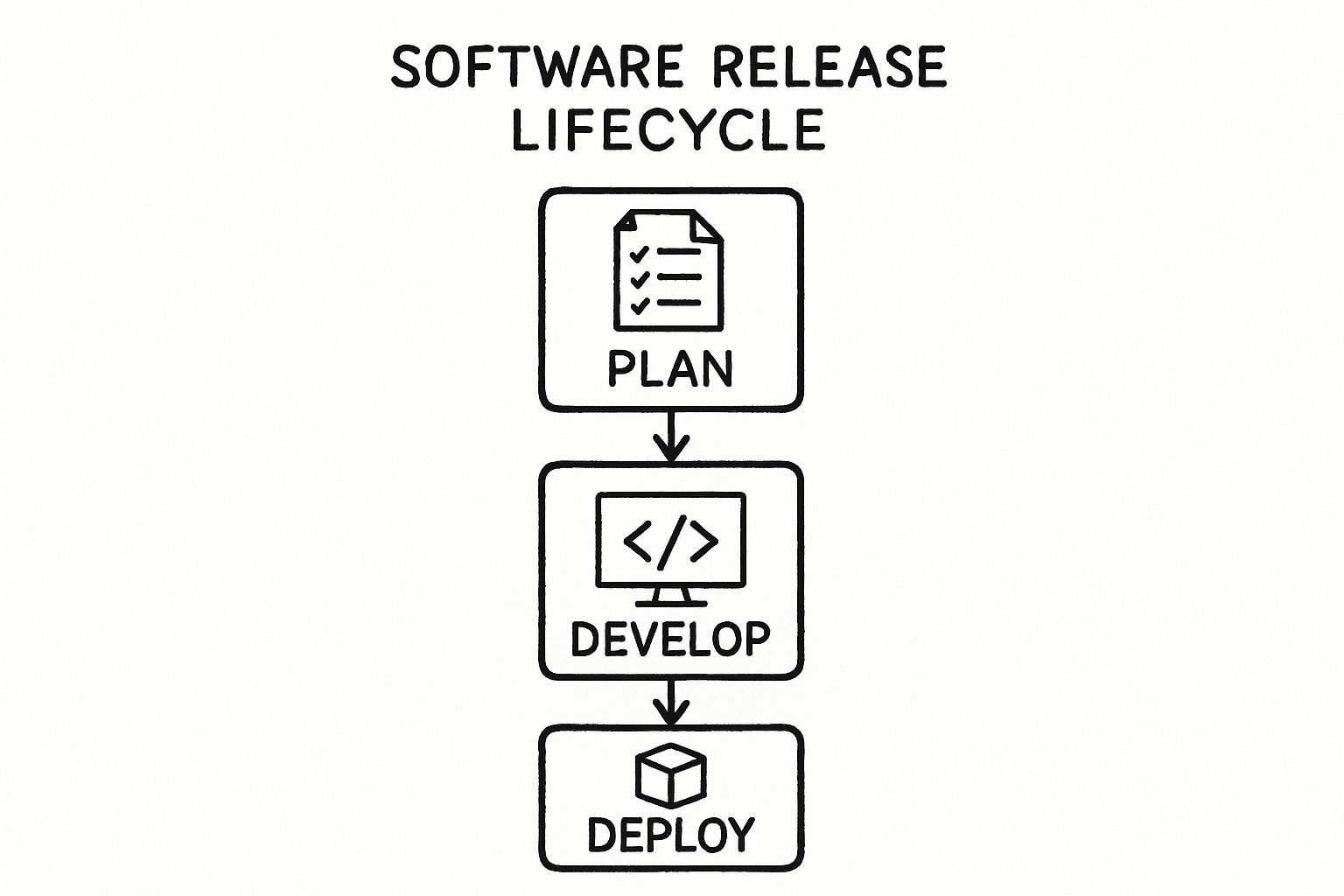
This visual representation underscores a fundamental engineering principle: a successful deployment is the direct output of meticulous planning and disciplined development. It prevents teams from taking shortcuts that compromise quality and stability.
Core Phases and Their Purpose
While organizational terminology may vary, the SRLC is universally segmented into distinct phases. Each phase has a specific objective and a set of deliverables designed to advance the software toward a production-ready state. Mastering these stages is the first step toward building a predictable and resilient release engine.
A mature software release lifecycle transforms deployments from high-stakes, stressful events into routine, low-risk operations. It’s the difference between a frantic scramble and a well-rehearsed performance.
To provide a clear overview, let's delineate the primary stages. We will perform a technical deep-dive into each of these throughout this guide.
Core Phases of the Software Release Lifecycle
The following table summarizes the main stages of the SRLC, detailing the primary objective and typical technical activities for each. Consider it a quick-reference model for the entire process.
| Phase | Primary Objective | Key Activities |
|---|---|---|
| Pre-Alpha | Define scope and initial design | Requirements gathering, architectural design (monolith vs. microservices), creating prototypes, initial project setup, defining technology stack. |
| Alpha | Develop initial working software | Core feature development, unit testing, establishing CI/CD pipelines, internal developer and QA testing, code reviews. |
| Beta | Gather user feedback on features | Feature-complete builds, external testing with a limited audience, bug fixing, performance testing, integration testing. |
| Release Candidate | Ensure stability for launch | Code freeze, comprehensive regression testing, final bug fixes, preparing release notes, final security scans. |
| General Availability | Deploy to all end-users | Production deployment (e.g., Blue-Green, Canary), monitoring application performance and health, executing rollback plans. |
| Post-Release | Maintain and support the product | Bug fixing (hotfixes), security patching, planning minor/major updates, ongoing user support, monitoring SLOs/SLIs. |
Understanding these phases is fundamental. Each one represents a critical quality gate that validates the software's correctness, performance, and security before it proceeds to the next stage.
Planning And Initial Development
Every robust software system is built on a solid architectural and developmental foundation. Shipping reliable software is impossible without first investing in rigorous planning and initial development. This critical groundwork occurs during the Pre-Alpha and Alpha stages of the software release lifecycle.
The Pre-Alpha stage is the architectural design phase. The objective is not to write production code, but to define what the system must do and how it will be architected. This involves collaboration between product managers, architects, and senior engineers to translate business requirements into a technical specification.
During this phase, requirements are captured as user stories (e.g., "As a user, I want to authenticate via OAuth 2.0 so I can securely access my account without a password") and detailed use cases. These artifacts are essential for ensuring the engineering team builds features that solve specific problems. A critical output of this stage is creating a comprehensive product roadmap that guides subsequent development sprints.
Designing The System Architecture
With clear requirements, the focus shifts to system architecture—a critical decision that dictates the application's scalability, maintainability, and operational cost. Key activities include creating Unified Modeling Language (UML) diagrams, such as sequence and component diagrams, to visualize system interactions and dependencies.
A primary architectural decision is the choice between a monolithic or microservices pattern.
- Monolith: A single, tightly-coupled application containing all business logic. It simplifies initial development and deployment but becomes difficult to scale, test, and maintain as complexity grows.
- Microservices: The application is decomposed into a set of small, independently deployable services. This pattern enhances scalability and flexibility but introduces significant operational overhead related to service discovery, inter-service communication, and distributed data management.
The optimal choice depends on team expertise, project complexity, and long-term scalability requirements. A startup might choose a monolith for speed, while a large-scale enterprise system may require a microservices architecture from day one.
Kicking Off The Alpha Phase
With an architectural blueprint defined, the Alpha stage begins. Here, the first lines of production code are written, transforming the abstract design into a tangible, functional system. The focus is on implementing core features and, equally important, establishing development practices that enforce quality from the outset.
A cornerstone of this phase is implementing a version control strategy. The GitFlow branching model is a widely adopted standard that provides a structured framework for managing the codebase. It uses dedicated branches for features, releases, and hotfixes, which minimizes merge conflicts and maintains the integrity of the main branch.
For instance, a standard GitFlow workflow would be executed via CLI commands:
# Create the main long-lived branches
git branch main
git branch develop
# Start a new feature from the 'develop' branch
git checkout develop
git checkout -b feature/user-authentication
# ... developers work on the feature and commit changes ...
# Merge the completed feature back into 'develop'
git checkout develop
git merge --no-ff feature/user-authentication
This disciplined approach ensures the main branch always represents a production-ready state, while develop serves as the integration point for new functionality.
Embedding Quality with Unit Testing
As developers build features, they must simultaneously write unit tests. These are automated tests that validate the correctness of individual code units—such as a function or class—in isolation. They are the first and most effective line of defense against regressions.
Unit testing is not an optional add-on; it is an integral part of the development process. A comprehensive unit test suite provides a safety net, enabling developers to refactor code and add features with confidence, knowing that any breaking change will be caught immediately by the CI pipeline.
For example, a unit test for a simple utility function in Python using the PyTest framework might look like this:
# utils/calculator.py
def add(a: int, b: int) -> int:
return a + b
# tests/test_calculator.py
from utils.calculator import add
import pytest
def test_add_positive_numbers():
assert add(2, 3) == 5
def test_add_negative_numbers():
assert add(-1, -1) == -2
@pytest.mark.parametrize("a,b,expected", [(10, 5, 15), (0, 0, 0)])
def test_add_various_cases(a, b, expected):
assert add(a, b) == expected
These tests are integrated into the daily workflow and executed automatically by a Continuous Integration (CI) server on every commit. This practice provides immediate feedback, preventing defective code from progressing further down the release pipeline and building a foundation of quality that persists through to final deployment.
Beta Testing And Release Candidate

Once the software exits the Alpha phase, it enters the critical Beta and Release Candidate (RC) stages. This is where the application is exposed to real-world conditions, transitioning from an internally validated product to one hardened by external users and rigorous pre-production testing.
The Beta phase commences when the software is declared feature-complete. This is a pivotal milestone. The team's focus shifts entirely from new feature development to bug extermination, user experience refinement, and performance validation under realistic load.
This is analogous to shakedown testing for a race car. The core components are assembled, but now it must be pushed to its operational limits on a test track to identify and rectify weaknesses before it competes.
Engaging Users and Gathering Feedback
The primary objective of Beta testing is to solicit structured, actionable feedback from a curated group of external users who represent the target demographic. These testers can be sourced from existing customer pools, community forums, or dedicated beta testing platforms.
The goal is to collect technical data, not just opinions. This requires a formal feedback collection system.
- Bug Tracking Tools: Utilize systems like Jira, Azure DevOps, or Linear to log every issue. A high-quality bug report includes precise steps to reproduce, client-side environment details (e.g., OS, browser version, screen resolution), and a severity classification (e.g., Blocker, Critical, Major).
- Structured Feedback Forms: Proactively solicit input on specific features or workflows using in-app surveys or feedback widgets. This provides targeted, quantifiable data.
- Performance Monitoring: Application Performance Monitoring (APM) tools (e.g., Datadog, New Relic) are essential. They provide client-side telemetry on performance metrics like page load times, API response latency, and memory consumption, revealing issues users may not explicitly report.
This disciplined data collection separates signal from noise, preventing critical insights from being lost and providing developers with a prioritized, actionable backlog. Concurrently, the QA team executes technical tests. Integration tests verify interactions between services, while performance tests using tools like JMeter or Gatling simulate concurrent user load to identify and eliminate performance bottlenecks.
The Release Candidate and Code Freeze
After incorporating beta feedback and achieving a stable build, the software is promoted to the Release Candidate (RC) stage. This is the final pre-production checkpoint. An RC is a build that is deemed functionally complete, stable, and ready for general deployment.
A Release Candidate signifies a critical shift in mindset. It's a declaration that you believe the product is ready. From this point forward, the only changes permitted are fixes for critical, show-stopping bugs—nothing else.
This policy is enforced through a code freeze. No new features, refactoring, or minor cosmetic changes are permitted in the release branch. The codebase is locked down to ensure stability and prevent last-minute changes from introducing catastrophic regressions. For a deep dive into validating mobile apps during this phase, it’s worth checking out these React Native beta testing best practices.
With the code frozen, the QA team executes a final, exhaustive regression test suite. This involves re-running all existing automated and manual tests to verify that recent bug fixes have not broken existing functionality. This is the final line of defense. If specific features need to be toggled for a subset of users without a full redeployment, it is wise to explore feature toggle management for granular control.
Finally, the team finalizes the release notes, documenting new features, bug fixes, and any known issues. Once an RC build passes all regression tests and receives final sign-off from key stakeholders, it is tagged and officially prepared for deployment.
Deployment Strategies And Post Release Maintenance

The General Availability (GA) milestone marks the culmination of the entire software release lifecycle. The application is stable, thoroughly tested, and ready for production traffic.
However, the deployment methodology is as critical as the preceding development stages. A poorly executed deployment can cause service disruptions, data integrity issues, and a loss of user trust, effectively nullifying months of work.
Modern DevOps practices provide several deployment strategies designed to minimize risk and ensure a seamless transition. The ideal approach depends on application architecture, risk tolerance, and infrastructure capabilities.
Choosing Your Deployment Strategy
Not all deployment strategies are created equal. Blue-green, canary, and rolling deployments each offer a different trade-off between speed, safety, and operational cost.
- Blue-Green Deployment: This strategy involves maintaining two identical, parallel production environments: "Blue" (the current live version) and "Green" (the new version). The new code is deployed to the Green environment for final validation. Traffic is then switched from Blue to Green at the load balancer or router level. Rollback is nearly instantaneous—simply route traffic back to Blue. The primary drawback is the cost of maintaining duplicate infrastructure.
- Canary Deployment: This is a more cautious, progressive release strategy. The new version is deployed to a small subset of users (the "canaries"). The system is monitored closely for errors, latency spikes, or other anomalies. If the new version performs as expected, traffic is gradually shifted from the old version to the new version until the rollout is complete. This minimizes the blast radius of potential bugs but adds complexity to routing and monitoring.
- Rolling Deployment: With this method, server instances are updated in batches until the entire fleet is running the new version. It is more cost-effective than blue-green but makes rollbacks more complex. It also requires the application to support running both old and new versions simultaneously during the deployment window.
For mission-critical applications where downtime is unacceptable, blue-green deployment is a powerful choice. Many cloud providers, like AWS with its Elastic Container Service (ECS) and Elastic Beanstalk, have built-in support for this pattern, simplifying its implementation.
Post-Launch Monitoring and Maintenance
Deployment is not the end of the lifecycle. The post-release phase is a continuous process of monitoring, maintenance, and iteration to ensure the application remains stable, secure, and performant.
A robust observability stack is non-negotiable for modern applications.
- Monitoring: Tools like Prometheus and Grafana are used to track and visualize key system metrics (e.g., CPU utilization, memory usage, request latency, error rates). These dashboards provide a real-time view of system health and alert engineers to potential problems before they impact users.
- Logging: Centralized logging, implemented with tools like the ELK Stack (Elasticsearch, Logstash, Kibana) or Loki, aggregates logs from all application services into a single, searchable repository. This is essential for debugging issues in distributed systems, allowing engineers to trace a single request across multiple microservices to pinpoint the source of an error.
This combination of proactive monitoring and deep logging is the foundation of effective maintenance and a hallmark of a mature delivery process. For a deeper dive, check out our guide on CI/CD pipeline best practices for building these kinds of resilient systems.
Integrating DevOps Automation

Manually managing each stage of the software release lifecycle is inefficient, error-prone, and unscalable. DevOps automation acts as the connective tissue that integrates these stages, transforming a disjointed manual process into a streamlined, repeatable, and reliable system.
This automation is embodied in a Continuous Integration/Continuous Deployment (CI/CD) pipeline. The pipeline is an automated workflow that compiles source code, executes a battery of tests, and prepares the application for deployment without manual intervention.
The fundamental goal is to make software releases a low-risk, routine event rather than a high-stress, all-hands-on-deck emergency. To understand the underlying principles, it's beneficial to learn more about what is workflow automation.
Anatomy of a Modern CI/CD Pipeline
A CI/CD pipeline is typically triggered by a code commit to a version control system like Git. This event initiates a cascade of automated actions orchestrated by tools such as Jenkins, GitLab CI, or GitHub Actions.
A modern pipeline consists of several key stages:
- Build Automation: A CI server like Jenkins fetches the latest code and compiles it into a runnable artifact, immediately catching syntax errors and dependency conflicts.
- Containerization: The compiled application is packaged into a lightweight, portable Docker container. The container encapsulates the application and all its dependencies, ensuring consistent behavior across all environments, from a developer's local machine to production.
- Automated Testing: The Docker container is instantiated in a clean, isolated environment where a series of automated tests—unit, integration, and even performance tests—are executed against it. If any test fails, the pipeline halts and notifies the development team.
- Orchestration: Upon successful validation, the container image is pushed to a container registry. From there, an orchestrator like Kubernetes manages the deployment of the container across a cluster of servers.
This automated sequence drastically reduces the lead time for changes, enabling elite teams to deploy code multiple times a day, a stark contrast to traditional release cycles measured in weeks or months.
Orchestrating Releases with Kubernetes
Kubernetes has become the de facto standard for container orchestration at scale. It automates the deployment, scaling, and management of containerized applications, enabling the execution of complex deployment strategies that would be manually infeasible.
A well-designed CI/CD pipeline doesn't just automate work; it enforces quality. By building in automated checks and gates, it makes it nearly impossible for bad code to ever reach your users. This frees developers from worrying about infrastructure so they can focus on what they do best: building great features.
Below is a simplified Kubernetes Deployment manifest written in YAML. This declarative configuration file instructs Kubernetes on the desired state of the application.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-web-app
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: my-app-container
image: your-repo/my-web-app:v1.2.0
ports:
- containerPort: 80
Let's dissect this manifest:
replicas: 3instructs Kubernetes to maintain three identical instances of the application for high availability.image: your-repo/my-web-app:v1.2.0specifies the exact Docker image version to be deployed.containerPort: 80informs Kubernetes that the application listens on port 80 within the container.
To perform an update, one simply modifies the image tag to the new version (e.g., v1.2.1) and applies the updated manifest. Kubernetes then orchestrates a zero-downtime rolling update, gracefully replacing old application instances with new ones.
This level of automation provides a significant competitive advantage, resulting in faster release velocity and improved system reliability. At OpsMoon, our experts specialize in architecting and implementing these custom, high-performance pipelines tailored to your team's specific requirements.
Dealing With Roadblocks and runaway Costs
Even a well-architected software release lifecycle will encounter obstacles. Common issues like scope creep, mounting technical debt, and testing bottlenecks can jeopardize timelines and budgets. Mitigating these requires proactive risk management and rigorous cost control.
Scope creep is best managed with a strict change-control policy. This is not about inflexibility; it's about process. Once the planning phase concludes, any new feature request must be formally evaluated for its impact on schedule, budget, and architecture. This disciplined approach prevents feature bloat and maintains project focus.
Technical debt—the implied cost of rework caused by choosing an easy solution now instead of using a better approach that would take longer—is a silent productivity killer. To combat this, integrate static analysis tools like SonarQube directly into your CI/CD pipeline. These tools automatically flag code smells, security vulnerabilities, and cyclomatic complexity, enabling teams to address debt before it accumulates.
Breaking Through Bottlenecks and Budget Squeezes
Testing is a frequent bottleneck and a significant cost center. Over-reliance on manual testing results in slow, expensive releases. The solution is strategic automation. The highest return on investment comes from automating repetitive, high-value tests such as regression suites, smoke tests, and performance tests.
This leads to the "build versus buy" dilemma for testing frameworks. Building a custom framework offers complete control but consumes significant developer resources. Licensing a commercial tool accelerates implementation and typically includes professional support, freeing your engineering team to focus on core product development.
Cost optimization isn't about blindly slashing budgets. It's about being smart with your money. Automating the right things and making informed technical decisions lets you do a lot more with what you have, without sacrificing quality or speed.
To budget effectively, you must understand your cost drivers. Recent data shows that quality assurance and testing costs have increased by up to 26%, while post-release maintenance consumes 15-20% of the initial development cost annually. However, automation is projected to reduce testing costs by approximately 20%. The path to efficiency is clear. For a deeper dive into these numbers, you can review key software development statistics on manektech.com.
The table below outlines common SRLC challenges, their impact, and practical technical solutions.
SRLC Challenges And Technical Solutions
| Common Challenge | Impact on Lifecycle | Recommended Technical Solution |
|---|---|---|
| Scope Creep | Uncontrolled feature additions lead to budget overruns, missed deadlines, and a diluted product focus. | Implement a strict change control process. All new feature requests post-planning must go through a formal approval board. |
| Technical Debt | Slows down future development, increases bug rates, and makes the codebase difficult to maintain or scale. | Integrate static code analysis tools (e.g., SonarQube) into the CI pipeline to catch issues early. Schedule regular "tech debt sprints". |
| Testing Bottlenecks | Manual testing slows down the entire release cycle, increases costs, and can be prone to human error, risking quality. | Adopt a hybrid testing strategy. Automate regression, smoke, and performance tests while using manual testing for exploratory and usability scenarios. |
| Poor Communication | Silos between Dev, QA, and Ops teams cause misunderstandings, rework, and delays in issue resolution. | Use a centralized communication platform (e.g., Slack, MS Teams) with dedicated channels and integrate it with project management tools like Jira. |
| Inconsistent Environments | Discrepancies between development, testing, and production environments lead to "it works on my machine" issues. | Leverage Infrastructure as Code (IaC) with tools like Terraform or Pulumi to ensure environments are identical and reproducible. |
By anticipating these hurdles and implementing the right tools and processes, you can transform potential crises into manageable tasks and keep your projects on schedule.
Smart Budgeting and Strategic Help
A sound budget must account for the entire lifecycle, not just the initial development phase. Funds for maintenance—including security patching, bug fixes, and minor enhancements—must be allocated from the project's inception. This prevents maintenance needs from cannibalizing resources intended for new feature development.
Strategic outsourcing is another powerful tool for cost management. Over 32% of companies now outsource some development to access specialized skills and control costs. This is particularly effective for non-core tasks or for augmenting team capacity during critical project phases.
At OpsMoon, we specialize in implementing these cost-optimization strategies. We connect you with elite DevOps engineers who can fine-tune your pipelines and infrastructure for maximum efficiency. For more in-depth tips on keeping your cloud bills in check, don’t miss our guide on effective cloud cost optimization strategies.
By combining strategic financial planning with deep technical expertise, you can overcome the common challenges of the SRLC and consistently deliver exceptional software on time and within budget.
Frequently Asked Questions
Even with a well-defined process, practical questions inevitably arise when implementing a software release lifecycle. Here are answers to some of the most common technical challenges teams face.
How Do I Choose The Right CI/CD Tools?
The optimal CI/CD tool is one that integrates seamlessly with your existing technology stack and that your team can adopt with minimal friction. There is no single "best" tool, only the right tool for your specific context.
Begin by assessing your version control system. If your codebase resides in GitHub, GitHub Actions is a logical choice due to its native integration. Similarly, for teams using GitLab, GitLab CI is the most efficient option.
For complex, multi-cloud, or hybrid environments, a platform-agnostic tool like Jenkins offers maximum flexibility and extensibility, though it comes with a higher administrative overhead. The primary goal is to select a tool that reduces process friction, not one that imposes a steep learning curve on your team.
How Do We Actually Enforce Quality Gates?
To be effective, quality gates must be automated and non-negotiable. They cannot be a manual checklist item that can be bypassed under pressure.
A quality gate isn't a person signing off on a form; it's an automated, non-negotiable step in your pipeline. If the code doesn't pass, the build fails. Period.
This requires codifying your quality standards directly into your CI/CD pipeline configuration (e.g., a Jenkinsfile or .gitlab-ci.yml). These automated checks should include:
- Unit Test Coverage: Configure the pipeline to fail any build where test coverage drops below a predefined threshold (e.g., 80%).
- Static Code Analysis: Integrate tools like SonarQube to automatically block any merge request that introduces critical vulnerabilities, bugs, or excessive technical debt.
- Security Scans: Implement container image scanning (e.g., using Trivy or Snyk) within the pipeline to prevent images with known high-severity vulnerabilities from being pushed to your container registry.
How Should We Handle Emergency Patches?
Hotfixes are inevitable. The process must be rapid but must not circumvent quality controls. A hotfix should bypass the standard release cadence but never bypass essential validation.
The GitFlow model provides an excellent pattern for this with its dedicated hotfix branch, which is created directly from the main branch. A developer commits the emergency fix to this branch, which triggers an accelerated CI pipeline. This pipeline executes a critical-path set of tests—core unit tests, essential integration tests, and security scans—while skipping longer, non-essential stages. Upon successful validation, the hotfix is merged directly into main for immediate deployment and also merged back into develop to prevent the fix from being overwritten by the next standard release.
Ready to build a robust software release lifecycle without all the operational headaches? OpsMoon connects you with the top 0.7% of DevOps engineers who can build, automate, and manage your entire delivery pipeline. We offer flexible support that scales with you, from high-level strategic planning to hands-on implementation, making sure your releases are fast, reliable, and secure. Start with a free work planning session today!