10 CI/CD Pipeline Best Practices for 2025
 By opsmoon
By opsmoonUnlock faster, more reliable deployments. Explore 10 actionable CI/CD pipeline best practices with technical examples for modern DevOps teams.
In modern software development, a high-quality CI/CD pipeline is the critical engine that powers competitive advantage and operational stability. Merely having an automated pipeline is insufficient; the real differentiator between a high-performing team and one struggling with deployment failures lies in the maturity and technical sophistication of its processes. A truly effective pipeline isn’t just a series of scripts, it’s a well-architected system designed for speed, reliability, and security.
This article moves beyond generic advice to provide a technical, actionable guide to the 10 most impactful CI/CD pipeline best practices you can implement today. We will dissect each practice, offering a detailed framework that includes specific implementation strategies, code snippets, and tool recommendations. You will learn not just what to do, but precisely how to do it.
For instance, we won’t just tell you to “test your code.” We will show you how to structure a multi-layered testing strategy with unit, integration, and end-to-end tests, complete with configuration examples for frameworks like Pytest or Jest. Similarly, instead of vaguely suggesting security, we will detail how to integrate SAST, DAST, and dependency scanning tools directly into your pipeline stages.
Whether you are a startup CTO designing a scalable DevOps foundation, an engineering lead refining an enterprise-level delivery process, or an SRE expert optimizing for resilience, this guide provides a clear roadmap. The following practices are your blueprint for building a pipeline that enables you to build, test, and deploy software with unparalleled speed and confidence. Each principle is designed to be a building block toward achieving genuine continuous delivery and operational excellence.
1. Version Control Everything: Your Single Source of Truth
The cornerstone of all modern software development and one of the most crucial CI/CD pipeline best practices is establishing a single source of truth (SSoT). This is achieved by storing every component of your application ecosystem in a version control system (VCS) like Git. This practice extends far beyond just application source code; it must encompass everything required to build, test, deploy, and operate your software. This includes infrastructure definitions, pipeline configurations, database schemas, and application settings.
When every asset is versioned, you gain complete traceability and reproducibility. Any change, whether to a feature flag, a firewall rule, or a CI job, is committed, reviewed, and logged. This eliminates “it works on my machine” issues and ensures that you can reliably recreate any version of your application and its environment at any point in time. This is the foundation of GitOps, where the Git repository dictates the state of your infrastructure and applications.
Why This is Foundational
Using a VCS as your SSoT provides several critical benefits:
- Auditability: Every change is linked to a commit hash, an author, and a timestamp, creating an immutable audit trail.
- Reproducibility: You can check out any historical commit to perfectly replicate the state of your system, which is invaluable for debugging production incidents.
- Collaboration: A centralized repository allows teams to work on different components concurrently, using established workflows like pull requests for code review and quality gates.
- Automation: CI/CD pipelines are triggered directly by VCS events (e.g.,
git push,merge), making automation seamless and context-aware.
Actionable Implementation Tips
- Infrastructure as Code (IaC): Use tools like Terraform (
.tf), CloudFormation (.yml), or Ansible (.yml) to define your cloud resources, networks, and permissions in declarative code files. Commit these files to your repository. - Pipeline as Code: Define your CI/CD pipeline stages, jobs, and steps in a file like
.gitlab-ci.yml,Jenkinsfile, orazure-pipelines.yml. Storing this configuration alongside your application code ensures the pipeline evolves in lockstep with the app. - Configuration Management: Separate environment-specific variables (e.g., database URLs, API keys) from your application code. Store templates or non-sensitive default configurations in Git, and inject secrets at deploy time using a secure vault like HashiCorp Vault or AWS Secrets Manager.
- Database Migrations: Version control your database schema changes using tools like Flyway (SQL-based) or Liquibase (XML/YAML/SQL). The pipeline should execute
flyway migrateas a deployment step, ensuring the database schema is always in sync with the application version.
2. Automated Testing at Multiple Levels
A core principle of effective CI/CD is building confidence with every commit. This confidence is forged through a robust, multi-layered automated testing strategy integrated directly into the pipeline. This practice involves executing a hierarchy of tests, from fast, isolated unit tests to more complex end-to-end scenarios, automatically on every code change. The goal is to catch bugs as early as possible, provide rapid feedback to developers, and prevent regressions from ever reaching production.
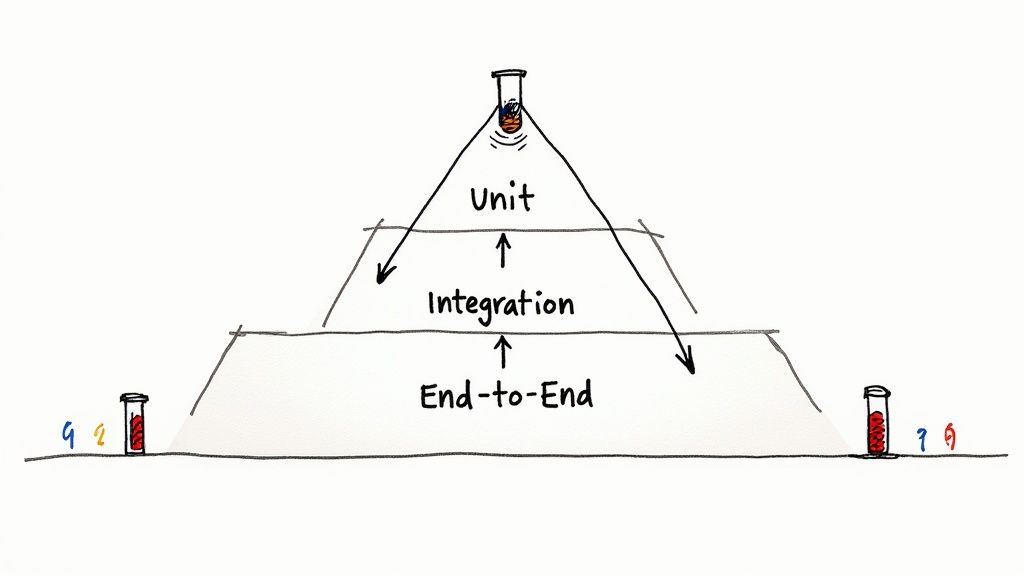
This approach, often visualized as the “Testing Pyramid,” ensures that you get the most efficient feedback loop. By automating this process, you create a powerful quality gate. A typical CI stage would run pytest for Python or jest --ci for JavaScript. This makes automated testing one of the most critical CI/CD pipeline best practices for delivering high-quality software at scale.
Why This is Foundational
A multi-layered automated testing strategy provides several transformational benefits:
- Rapid Feedback: Developers receive immediate feedback on their changes, often within minutes, allowing them to fix issues while the context is still fresh.
- Reduced Risk: By catching bugs early in the development cycle, you dramatically lower the cost of fixing them and reduce the risk of critical defects impacting users.
- Improved Code Quality: A comprehensive test suite acts as living documentation and a safety net, encouraging developers to refactor and improve the codebase with confidence.
- Enabling Velocity: Automation eliminates manual testing bottlenecks, allowing teams to deploy changes more frequently and reliably, which is the ultimate goal of CI/CD.
Actionable Implementation Tips
- Follow the Testing Pyramid: Structure your tests with a large base of fast unit tests (
pytest), a smaller layer of integration tests (e.g., usingtestcontainers), and a very small number of comprehensive (and slower) end-to-end (E2E) tests (e.g., using Cypress or Playwright). - Fail Fast: Organize your pipeline stages to run the fastest, most crucial tests first. For example, a
lint-and-unit-testjob should run before a slowerintegration-testjob. - Isolate Dependencies: Use libraries like Python’s
unittest.mockor JavaScript’ssinonto create mocks, stubs, and spies. This isolates the component under test, making unit tests faster and more reliable by avoiding dependencies on live databases or APIs. - Manage Test Data: Develop a clear strategy for managing test data. Use libraries like Faker.js to generate realistic but fake data, or employ database seeding scripts that run before your integration test suite to ensure tests execute in a consistent state.
- Tackle Flaky Tests: Actively monitor for and immediately fix “flaky” tests—tests that pass or fail inconsistently. Use test reporting tools to identify them and enforce a zero-tolerance policy, as they erode trust in the pipeline.
3. Build Once, Deploy Everywhere
A core tenet of reliable and predictable deployments, this CI/CD pipeline best practice dictates that a single build artifact should be created only once during the integration phase. This immutable artifact is then promoted across every subsequent environment, from development and QA to staging and, finally, production. This practice eliminates the risk of inconsistencies introduced by rebuilding the application for each stage, ensuring the code that passes testing is the exact same code that goes live.
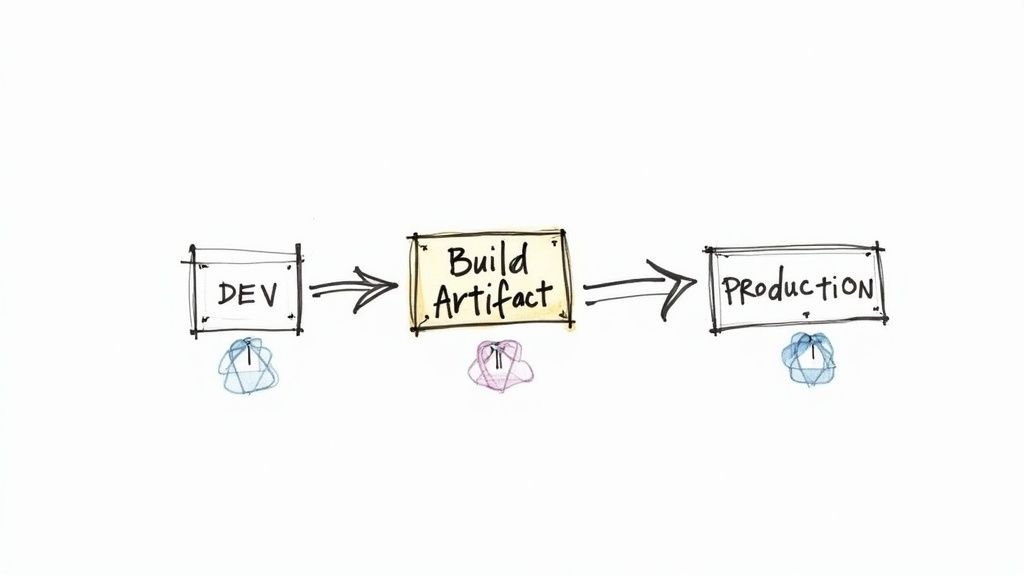
Popularized by thought leaders like Jez Humble and David Farley in their book Continuous Delivery, this approach guarantees that you are validating a known, consistent package. For example, a pipeline would execute docker build -t myapp:${CI_COMMIT_SHA} . once, push this specific image to a registry, and then reference myapp:${CI_COMMIT_SHA} in all deployment jobs. This drastically reduces environment-specific bugs and deployment failures.
Why This is Foundational
Creating a single, promotable artifact provides several powerful advantages:
- Consistency: It guarantees that the binary or package deployed to production is identical to the one that passed all tests in earlier environments.
- Speed: Promoting an existing artifact is significantly faster than rebuilding from source for each environment, accelerating the entire deployment lifecycle.
- Traceability: A single versioned artifact can be easily tracked as it moves through the pipeline, simplifying auditing and rollback procedures.
- Confidence: Teams gain higher confidence in their deployments, knowing that last-minute code changes or environmental differences won’t alter the final product.
Actionable Implementation Tips
- Containerize Your Application: Use Docker to package your application and its dependencies into a single, immutable image. This image becomes the artifact you promote through your pipeline. Your
Dockerfileshould be optimized using multi-stage builds to keep the final image lean. - Leverage an Artifact Repository: Store your versioned build artifacts (e.g., Docker images in Amazon ECR/GCR, JAR files in Nexus/Artifactory) with specific version tags. This centralizes artifact management and controls access.
- Externalize Configuration: Never bake environment-specific settings (like database credentials or API endpoints) into your build artifact. Instead, load configurations from environment variables or mount configuration files (like Kubernetes ConfigMaps/Secrets) at runtime.
- Implement a Versioning Strategy: Adopt a clear artifact versioning scheme, such as Semantic Versioning (SemVer). Tag your artifacts with both the Git commit hash (
v1.2.3-a1b2c3d) and a human-readable version for full traceability and easier rollbacks.
4. Fail Fast and Provide Quick Feedback
A core principle of effective CI/CD pipeline best practices is to design your automation to report failures as quickly as possible. The “fail fast” mantra means structuring your pipeline to detect problems early, ideally within minutes of a code commit. The longer it takes to discover a broken build or a failed test, the more developer time is wasted, and the higher the cost of context switching to fix an issue that could have been identified immediately. A slow feedback loop disrupts developer flow and delays the integration of valuable changes.

The goal is to provide developers with near-instantaneous feedback on the health of their commits. This empowers them to address issues while the context is still fresh in their minds, preventing broken code from propagating further down the pipeline or blocking other team members. High-performing engineering teams aim for pipeline feedback in under 10 minutes.
Why This is Foundational
Structuring pipelines for rapid feedback dramatically improves development velocity and code quality:
- Reduced Context Switching: Developers can fix issues immediately, without having to shelf their current task and re-learn the context of a change made hours earlier.
- Increased Developer Productivity: Fast feedback loops minimize wait times, keeping developers engaged in a productive coding flow.
- Improved Code Quality: Immediate notifications encourage smaller, more manageable commits and foster a culture of collective code ownership and responsibility.
- Faster Mean Time to Resolution (MTTR): Identifying bugs closer to their introduction point makes them significantly easier and faster to diagnose and resolve.
Actionable Implementation Tips
- Prioritize Fast Tests: Structure your pipeline in stages. Run lightweight static analysis (
eslint,flake8) and fast-running unit tests (pytest -m "not slow") first. These can catch a majority of issues in seconds, providing the quickest possible feedback. - Parallelize Test Execution: Use your CI/CD tool’s features (e.g., GitLab’s
parallelkeyword, GitHub Actions’matrixstrategy) to run independent test suites concurrently. Splitting a 20-minute test suite into four parallel jobs can reduce its execution time to just five minutes. - Leverage Caching: Cache dependencies (e.g.,
~/.m2,node_modules, Docker layers) between pipeline runs. In GitLab CI, define acache:block; in GitHub Actions, useactions/cache. This avoids re-downloading them on every execution. - Implement Smart Notifications: Configure immediate, targeted notifications upon failure. Use integrations like the Slack Orb for CircleCI or webhooks to post a message to a specific team channel, including the commit author, commit hash, and a link to the failed job log.
5. Infrastructure as Code (IaC)
Just as version control is the single source of truth for code, Infrastructure as Code (IaC) is the practice of managing and provisioning your entire technology infrastructure through machine-readable definition files. This core CI/CD pipeline best practice treats your servers, load balancers, databases, and networks as software components, defining them in code and storing them in a version control system like Git. This shifts infrastructure management from manual, error-prone configuration to an automated, repeatable, and transparent process.
By codifying your infrastructure, you can apply the same CI/CD principles used for application development. Changes are submitted via pull requests, automatically tested (terraform validate, terraform plan), and then deployed (terraform apply) through the pipeline. This approach eliminates configuration drift and ensures that your staging and production environments are identical, which is critical for reliable testing and deployment.
Why This is Foundational
Integrating IaC into your CI/CD workflow provides transformative advantages:
- Consistency: Automatically provision identical environments every time, eliminating the “it works on my machine” problem at the infrastructure level.
- Speed and Efficiency: Drastically reduce the time it takes to provision and scale resources, from hours or days to just minutes.
- Traceability: Every infrastructure change is versioned in Git, providing a complete audit trail of who changed what, when, and why.
- Disaster Recovery: Rebuild your entire infrastructure from code after a failure, ensuring rapid and reliable recovery.
Actionable Implementation Tips
- Adopt Declarative Tools: Use declarative IaC tools like Terraform or AWS CloudFormation. You define the desired end state of your infrastructure, and the tool figures out how to achieve it. For deeper insights into leveraging this approach, you can explore professional Terraform services on opsmoon.com.
- Modularize Your Code: Break down your infrastructure definitions into small, reusable, and composable modules (e.g., a Terraform module for a VPC, another for a Kubernetes cluster). This improves maintainability and reusability across projects.
- Test Your Infrastructure: Implement automated testing for your IaC. Use tools like
terratestto write Go-based tests that provision real infrastructure, validate its configuration, and tear it down. For static analysis, use tools liketfsecorcheckov. - Manage State Securely: IaC tools use state files to track resources. Always use a secure, remote backend like an S3 bucket with DynamoDB for state locking to prevent race conditions and protect sensitive information in team environments.
6. Implement Comprehensive Security Scanning
In a modern CI/CD pipeline, security cannot be an afterthought; it must be an integrated, automated part of the entire development lifecycle. This practice, often called DevSecOps, involves embedding security testing directly into your pipeline. This “shift-left” approach means moving security checks from a final, pre-release gate to the earliest possible stages of development. By doing so, you identify and remediate vulnerabilities faster, when they are significantly cheaper and easier to fix.
This comprehensive approach goes beyond a single scan. It layers multiple types of security analysis throughout the pipeline, from the moment a developer commits code to post-deployment monitoring. This creates a resilient security posture where vulnerabilities are caught automatically, making security a shared responsibility rather than the sole domain of a separate team.
Why This is Foundational
Integrating security into the pipeline is a critical CI/CD pipeline best practice for several reasons:
- Early Detection: Finds vulnerabilities in code and dependencies before they are merged into the main branch, drastically reducing the cost and effort of remediation.
- Reduced Risk: Automating scans for common vulnerabilities (like those in the OWASP Top 10), misconfigurations, and exposed secrets minimizes the attack surface of your application.
- Improved Velocity: By automating security, you eliminate manual security reviews as a bottleneck, allowing development teams to maintain speed without sacrificing safety.
- Compliance and Governance: Creates an auditable trail of security checks, helping to meet regulatory requirements like SOC 2, HIPAA, or PCI DSS.
Actionable Implementation Tips
- Static & Dependency Scanning (Pre-Build): Integrate Static Application Security Testing (SAST) tools like SonarQube or Snyk Code to analyze source code for flaws. Simultaneously, use Software Composition Analysis (SCA) tools like OWASP Dependency-Check or
npm auditto scan for known vulnerabilities in third-party libraries. This should be a required job in your merge request pipeline. - Container Image Scanning (Build): As you build container images, use tools like Trivy or Clair to scan them for OS-level vulnerabilities and misconfigurations. Integrate this scan directly after the
docker buildcommand in your pipeline:trivy image myapp:${TAG}. - Dynamic Security Testing (Post-Deployment): After deploying to a staging environment, run Dynamic Application Security Testing (DAST) tools like OWASP ZAP. These tools actively probe the running application for vulnerabilities like Cross-Site Scripting (XSS) or SQL Injection. Many CI tools have built-in DAST integrations.
- Set Gated Thresholds: Configure your pipeline to fail if scans detect critical or high-severity vulnerabilities. For example,
snyk test --severity-threshold=high. This creates a “security gate” that prevents insecure code from progressing, enforcing a minimum quality bar.
7. Use Feature Flags and Toggle-Based Deployment
Decoupling deployment from release is a hallmark of mature CI/CD pipeline best practices. This is achieved by wrapping new functionality in feature flags (also known as feature toggles), which act as remote-controlled if/else statements in your code. This allows you to deploy code to production with new features turned “off” by default, and then activate them for specific users or segments at a later time without requiring a new code deployment.
This practice fundamentally changes the risk profile of a deployment. Instead of a high-stakes, big-bang release, you can perform low-risk “dark launches” where code is live but inactive. If an issue arises when you enable the feature, you can instantly disable it with a single click in a management dashboard, effectively rolling back the feature without a complex and stressful redeployment or hotfix.
Why This is Foundational
Using feature flags transforms your release strategy from a purely technical event into a controlled business decision. This provides several powerful benefits:
- Risk Mitigation: The ability to instantly disable a faulty feature in production is the ultimate safety net, reducing Mean Time to Recovery (MTTR) to near-zero for feature-related incidents.
- Canary Releases and A/B Testing: You can release a feature to a small percentage of users (e.g., 1% of traffic, internal employees), monitor its performance and business impact, and gradually roll it out to everyone.
- Continuous Deployment: Teams can merge and deploy small, incremental changes to the main branch continuously, even if the features they are part of are incomplete. The work simply remains behind a disabled flag until ready.
- Trunk-Based Development: Feature flags are a key enabler of trunk-based development, as they eliminate the need for long-lived feature branches, reducing merge conflicts and integration complexity.
Actionable Implementation Tips
- Use a Management Platform: Instead of building a custom flagging system, leverage dedicated platforms like LaunchDarkly or Split.io. They provide robust SDKs (
if (ldclient.variation("new-checkout-flow", user, false)) { ... }), user targeting, audit logs, and performance monitoring out of the box. - Establish Flag Lifecycle Management: Create a clear process for introducing, enabling, and, most importantly, removing flags. Use tools like Jira to track flag lifecycle and create “cleanup” tickets to remove a flag once its associated feature is fully rolled out and stable.
- Integrate Flags into Testing: Your automated tests should be capable of running with flags in both enabled and disabled states to ensure all code paths are validated. You can achieve this by mocking the feature flag SDK or by setting specific flag values for your test users.
- Document and Categorize Flags: Maintain clear documentation for each flag’s purpose, owner, and expected lifespan. Categorize them by type, such as “release toggle,” “ops toggle,” or “experiment toggle,” to clarify their intent and cleanup priority.
8. Monitor and Measure Everything
A CI/CD pipeline that operates without comprehensive monitoring is like flying blind. One of the most critical CI/CD pipeline best practices is to implement end-to-end observability, which involves collecting detailed metrics, logs, and traces across your entire pipeline and the applications it deploys. This goes beyond simple pass/fail notifications; it’s about understanding the health, performance, and impact of every change pushed through the system, from commit to production.
This practice, heavily influenced by Google’s Site Reliability Engineering (SRE) principles, treats your delivery pipeline as a product itself. It needs to be measured, analyzed, and improved. By instrumenting every stage, you can track key metrics like deployment frequency, lead time for changes, change failure rate, and mean time to recovery (MTTR), known as the DORA metrics.
Why This is Foundational
Embracing full-stack monitoring provides deep insights and control over your software delivery lifecycle:
- Proactive Problem Detection: Identify bottlenecks, flaky tests, or slow deployment stages before they cause major delays or production failures.
- Data-Driven Decisions: Use quantitative data, not guesswork, to justify improvements, allocate resources, and demonstrate the ROI of DevOps initiatives.
- Improved Incident Response: Correlate deployments with application performance degradation or error spikes, enabling teams to quickly identify and roll back faulty changes.
- Business Impact Analysis: Connect deployment metrics to business KPIs to understand how engineering velocity affects user engagement and revenue.
Actionable Implementation Tips
- Define Meaningful SLIs and SLOs: Establish clear Service Level Indicators (SLIs), like p95 latency or error rate, and set Service Level Objectives (SLOs) for your applications and the pipeline itself. For instance, an SLO could be “99.9% of deployments must complete in under 15 minutes.”
- Implement Centralized Logging: Use a log aggregation tool like the ELK Stack (Elasticsearch, Logstash, Kibana) or a SaaS solution like Splunk to collect and index logs from all pipeline jobs and application instances. Structure your logs in JSON format for easier parsing.
- Use Distributed Tracing: For microservices architectures, implement distributed tracing with tools compatible with OpenTelemetry, such as Jaeger or Honeycomb. This allows you to trace a single request as it travels through multiple services, which is essential for debugging complex systems.
- Create Role-Based Dashboards: Build targeted dashboards in tools like Grafana or Datadog. A developer might need a dashboard showing test coverage and build times, while an SRE needs one focused on application error rates and deployment statuses.
- Set Up Intelligent Alerting: Configure alerts to be actionable and low-noise. Trigger alerts based on SLO breaches or significant statistical anomalies (e.g., using Prometheus’s
predict_linearfunction) rather than simple threshold crossings to avoid alert fatigue. To truly master this, you might need expert guidance; you can learn more about how Opsmoon handles observability services here.
9. Implement Blue-Green or Canary Deployments
Deploying directly to production can be a high-stakes, all-or-nothing event. A more advanced and safer approach, central to modern CI/CD pipeline best practices, is to adopt deployment strategies like blue-green or canary releases. These methods drastically reduce the risk of production failures and eliminate downtime by providing controlled, gradual rollout mechanisms and instant rollback capabilities.
Blue-green deployments involve running two identical production environments: “blue” (the current live version) and “green” (the new version). Traffic is switched at the load balancer or router level from blue to green only after the green environment is fully tested. Canary deployments gradually shift a percentage of traffic to the new version, allowing teams to monitor for issues with minimal blast radius.
Why This is Foundational
These strategies transform deployments from a source of anxiety into a low-risk, routine operation. They are critical for maintaining high availability and user trust, especially for services that cannot afford downtime.
- Risk Reduction: Problems are detected early with a limited user base (canary) or in a standby environment (blue-green), preventing widespread outages.
- Zero Downtime: Users experience no interruption in service, as traffic is seamlessly shifted from one stable environment to another.
- Instant Rollback: If a deployment introduces bugs, reverting is as simple as routing traffic back to the previous version (blue environment) or scaling down the canary release to 0%.
- Confidence in Releasing: Teams can deploy more frequently and confidently, knowing a safety net is in place. Service mesh tools like Istio and Linkerd provide powerful traffic-shifting capabilities out of the box.
Actionable Implementation Tips
- Comprehensive Health Checks: Your automation must be able to objectively determine if a new version is “healthy.” Implement deep
/healthendpoints that check not just service availability but also database connections, downstream dependencies, and key performance metrics. - Automated Rollback Triggers: Configure your pipeline to automatically initiate a rollback if key performance indicators (KPIs) like p99 latency or error rate cross predefined thresholds during a canary release. This can be scripted using monitoring tool APIs.
- Start with Small Canary Percentages: Leverage traffic management features in Kubernetes (e.g., via an Ingress controller like NGINX with weighted routing) or a service mesh to begin by exposing the new version to 1% of traffic. Gradually increase the percentage (e.g., 1% -> 10% -> 50% -> 100%) as you gain confidence.
- Plan for Database Compatibility: Ensure database schema changes are backward-compatible. A new version of the application must be able to work with the old database schema, and vice-versa, to allow for seamless rollbacks without data corruption. This often involves an “expand/contract” pattern for schema changes.
10. Maintain Clean and Organized Pipeline Code
One of the most overlooked CI/CD pipeline best practices is treating your pipeline definitions with the same rigor as your application source code. Your CI/CD configuration is not just a set of scripts; it is mission-critical code that orchestrates your entire release process. Therefore, it must be well-structured, modular, documented, and, above all, maintainable. This “Pipeline as Code” philosophy ensures your automation infrastructure remains scalable and resilient, not a fragile, monolithic script that everyone is afraid to touch.
Adopting software development best practices for your pipeline code means moving beyond simple, linear scripts. It involves creating a clean, organized structure that is easy to understand, modify, and extend. When pipelines are treated as first-class citizens, they evolve gracefully with your application, preventing them from becoming a source of technical debt and a bottleneck to delivery.
Why This is Foundational
A clean pipeline codebase directly impacts developer velocity and system reliability:
- Maintainability: A well-organized pipeline is easier to debug and update. New team members can understand the workflow faster, reducing onboarding time.
- Reusability: Modular components can be shared across multiple projects, enforcing standards and reducing duplicated effort. This is key to scaling DevOps practices across an organization.
- Scalability: As application complexity grows, a modular pipeline can be easily extended with new stages or jobs without requiring a complete rewrite.
- Reliability: Applying code reviews and testing to your pipeline code itself catches errors before they impact your deployment process, preventing failed builds and rollbacks.
Actionable Implementation Tips
- Use Reusable Templates & Libraries: Leverage features like Jenkins Shared Libraries, GitLab’s
includekeyword with YAML anchors (&), or GitHub Actions Reusable Workflows. Create reusable components for common tasks likecode-scan,docker-build, ordeploy-to-k8s. - Descriptive Naming: Name your jobs, stages, and variables clearly and consistently. A job named
deploy-web-app-to-stagingis far more informative thanjob3. Use comments in your YAML/Groovy files to explain complex logic. - Implement Robust Error Handling: Don’t let your pipeline fail silently. Use your CI/CD tool’s features to define cleanup jobs (like GitLab’s
after_scriptor GitHub Actions’if: always()) that run regardless of job status to send notifications, clean up test environments, or revert a failed change. - Regularly Refactor: Just like application code, pipeline code can suffer from “code rot.” Periodically review and refactor your pipelines to remove unused jobs, simplify complex scripts by abstracting them into functions, and update to newer, more efficient methods or tool versions. If you’re looking for expert guidance on structuring your automation, you can learn more about CI/CD services on opsmoon.com.
CI/CD Pipeline Best Practices Comparison
| Practice | Implementation Complexity | Resource Requirements | Expected Outcomes | Ideal Use Cases | Key Advantages |
|---|---|---|---|---|---|
| Version Control Everything | Moderate to High; advanced Git workflows | Moderate; needs version control tools | Complete traceability, reproducible builds | Collaborative development, compliance | Enables rollbacks, automated triggers |
| Automated Testing at Multiple Levels | High; requires test suite setup and maintenance | High; test execution infrastructure | Early bug detection, improved code quality | Continuous integration, quality assurance | Faster development cycles, reduced manual testing |
| Build Once, Deploy Everywhere | Moderate; setup for artifact management | Moderate to High; storage and tools | Consistent deployments across environments | Multi-environment deployments, microservices | Reduces deployment risks, faster rollbacks |
| Fail Fast and Provide Quick Feedback | High; requires pipeline optimization | High; parallel execution infrastructure | Rapid failure detection, faster feedback | Fast iteration cycles, early bug fixing | Improves developer productivity, reduces fix cost |
| Infrastructure as Code (IaC) | High; learning curve for IaC tools | Moderate; provisioning and versioning tools | Consistent, reproducible infrastructure | Cloud infrastructure management, automation | Reduces human error, faster provisioning |
| Implement Comprehensive Security Scanning | High; security tool integration and tuning | High; security scanning resources | Early vulnerability detection, compliance | Security-critical CI/CD pipelines | Automates security enforcement, reduces breaches |
| Use Feature Flags and Toggle-Based Deployment | Moderate; requires flag management strategy | Low to Moderate; flag management tools | Safer deployments, gradual rollouts | Controlled feature releases, A/B testing | Enables quick rollback, reduces deployment risk |
| Monitor and Measure Everything | Moderate to High; setup of monitoring systems | Moderate to High; monitoring tools and storage | Data-driven insights, incident detection | Production monitoring, DevOps feedback loops | Proactive issue detection, better decisions |
| Implement Blue-Green or Canary Deployments | High; complex orchestration and infrastructure | High; multiple environments/resources | Zero-downtime deployments, risk mitigation | Critical availability systems, phased rollouts | Minimizes downtime, quick rollback |
| Maintain Clean and Organized Pipeline Code | Moderate; requires discipline and best practices | Low to Moderate; code repos and reviews | Maintainable, reusable pipeline code | Teams with complex pipelines, collaboration | Easier maintenance, faster onboarding |
Your Roadmap to High-Maturity DevOps
Embarking on the journey to optimize your software delivery process can feel monumental, but the ten pillars we’ve explored provide a clear and actionable blueprint. Moving beyond theoretical concepts, the true power of these CI/CD pipeline best practices lies in their interconnectedness and their ability to foster a culture of continuous improvement, reliability, and speed. This is not merely about installing new tools; it’s about fundamentally re-architecting how your team collaborates, builds, and delivers value to your end-users.
By systematically implementing these principles, you transform your software delivery lifecycle from a source of friction and risk into a strategic advantage. You move from stressful, “big bang” releases to frequent, low-risk, and predictable deployments. This is the hallmark of a high-maturity DevOps organization.
Key Takeaways for Immediate Action
To crystallize your next steps, let’s distill the core themes from this guide into an actionable summary. Mastering these concepts is the most direct path to building resilient and efficient systems.
- Codify and Automate Everything: The foundational principle linking Version Control, Infrastructure as Code (IaC), and Clean Pipeline Code is that everything should be code. This ensures repeatability, traceability, and consistency, eliminating the “it works on my machine” problem and making your entire infrastructure and delivery process auditable and recoverable.
- Embed Quality and Security Early: The “shift-left” philosophy is central to modern DevOps. Practices like Automated Testing, Comprehensive Security Scanning, and Failing Fast are not gates to slow you down; they are accelerators that build quality and security into your product from the very first commit, preventing costly rework and security breaches later.
- Decouple Deployment from Release: Advanced strategies like Blue-Green Deployments, Canary Deployments, and Feature Flags are critical for reducing release-day anxiety. They separate the technical act of deploying code from the business decision of releasing features to users, giving you unparalleled control, safety, and flexibility.
- Embrace Data-Driven Decisions: The final, crucial piece is Monitoring and Measurement. A CI/CD pipeline without robust observability is a black box. By collecting metrics on pipeline performance, application health, and deployment frequency, you create feedback loops that drive informed, evidence-based improvements.
From Principles to Production-Grade Pipelines
The journey from understanding these best practices to implementing them effectively requires a strategic, phased approach. Start by assessing your current state. Which of these ten areas represents your biggest pain point or your greatest opportunity for improvement? Perhaps your testing is manual and brittle, or your deployment process is entirely manual and error-prone.
Select one or two key areas to focus on first. For example, you might start by containerizing your application and codifying its build process (Build Once, Deploy Everywhere), then move to automating your unit and integration tests (Automated Testing). Each incremental improvement builds momentum and delivers tangible benefits, making it easier to gain buy-in for the next phase of your DevOps evolution.
Ultimately, implementing these CI/CD pipeline best practices is about more than just technical execution. It is about building a robust, automated, and secure software factory that empowers your development teams to innovate faster and with greater confidence. The goal is to make deployments a non-event-a routine, predictable process that happens seamlessly in the background, allowing your engineers to focus on what they do best: building exceptional products that solve real-world problems. This transformation is the key to unlocking sustainable growth and a competitive edge in today’s fast-paced digital landscape.
Navigating the complexities of IaC, advanced deployment strategies, and observability can be challenging. OpsMoon provides elite, pre-vetted DevOps and SRE experts who specialize in implementing these exact CI/CD pipeline best practices. Accelerate your journey to DevOps maturity and build the robust, scalable pipeline your business needs by starting with a free work planning session at OpsMoon.