A Technical Guide to the Software Release Life Cycle
 By opsmoon
By opsmoonMaster the software release life cycle with this technical guide. Learn the key phases, best practices, and automation tools for flawless software deployment.

The software release life cycle is the engineering blueprint that transforms a conceptual feature into a production-ready, scalable application. It's the complete, repeatable process, from a specification document to a monitored, stable service handling live user traffic.
Understanding the Software Release Life Cycle
At its core, the software release life cycle (SRLC) is a structured, technical process designed to prevent software delivery from descending into chaos. Without a well-defined cycle, engineering teams are stuck in a reactive state—constantly hotfixing production, dealing with merge conflicts, and missing release targets. An effective SRLC aligns developers, operations, and product teams around a single, automated workflow.
This process is fundamentally about risk mitigation through early and continuous validation. It reduces the probability of production failures, improves system stability, and directly impacts end-user satisfaction. In an industry where global software spending is projected to hit US $1 trillion and mobile app spending reached US $35.28 billion in Q1 2024 alone, robust engineering practices are a critical business imperative. You can read more about how market trends shape release cycles.
The Core Phases of a Release
A modern software release life cycle is not a linear waterfall but a continuous, automated loop of build, test, deploy, and monitor. It's architected around key phases that act as quality gates, ensuring each artifact is rigorously validated before proceeding to the next stage.
This infographic provides a high-level overview of this technical workflow.
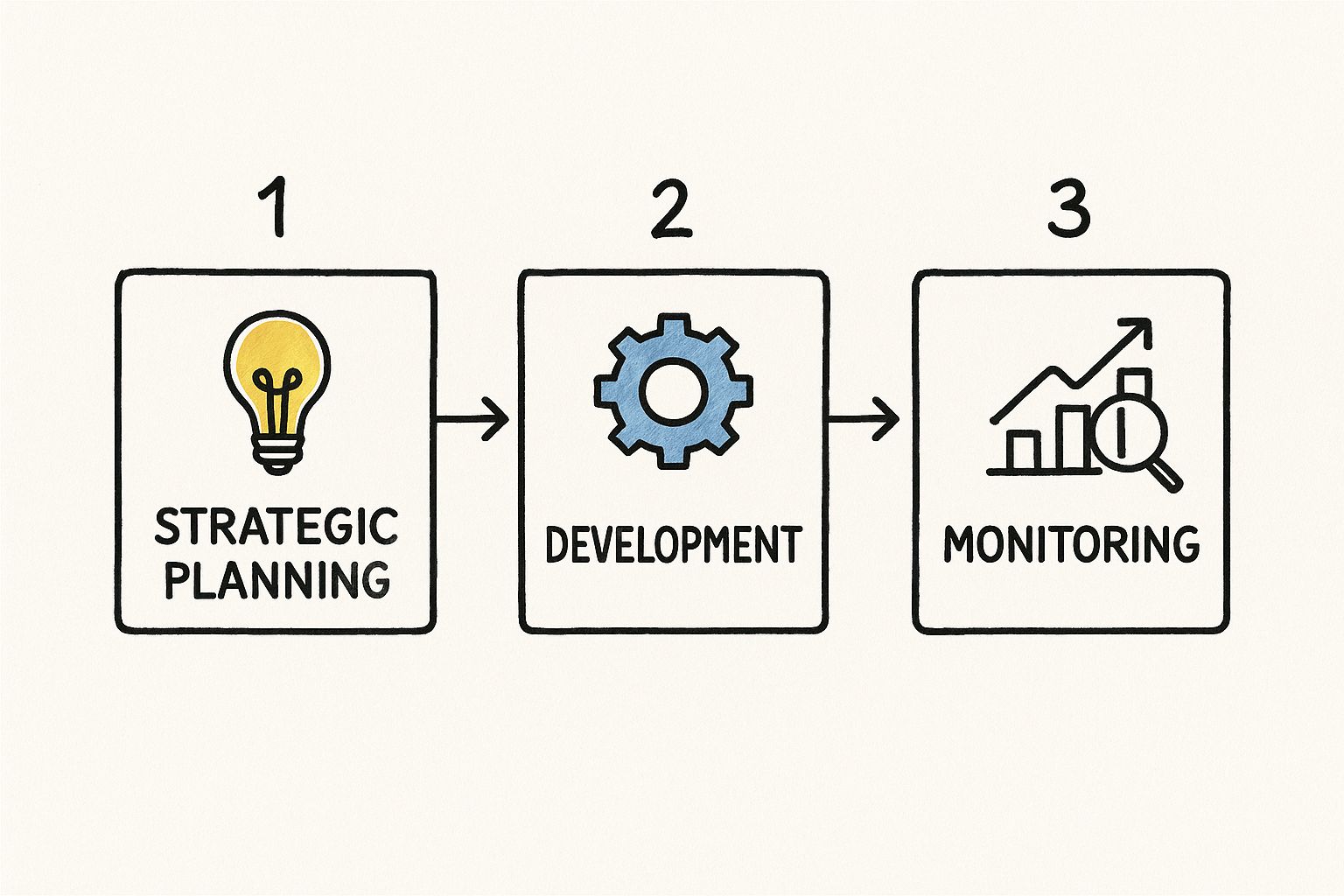
As illustrated, the process flows from strategic, technical planning into the development and CI/CD pipeline, culminating in a production deployment. Post-deployment, the cycle continues with observability and feedback loops that inform the subsequent release iteration.
Why This Process Is Non-Negotiable
A formalized SRLC provides tangible engineering advantages that translate directly to business outcomes. It is the foundation of a proactive, high-performance engineering culture.
Here are the technical benefits:
- Reduced Deployment Risk: Automated testing suites and controlled deployment strategies (like canary or blue-green) identify defects before they impact the entire user base, preventing production outages.
- Increased Predictability: A defined process with clear phases and automated gates provides reliable timelines and forecasts. Stakeholders receive accurate ETAs backed by pipeline data.
- Improved Code Quality: Mandatory code reviews, static analysis (SAST), and linting integrated into the CI pipeline act as automated quality gates. This enforces coding standards and maintains a secure, maintainable codebase.
- Faster Team Velocity: Automating build, test, and deployment pipelines eliminates manual toil, freeing up engineers to focus on high-value tasks like feature development and system architecture.
Building the Blueprint for Your Release
Every production-grade software release begins with a rigorous technical planning phase, long before a single line of code is committed. This phase translates high-level business objectives into a detailed, actionable engineering roadmap. It is the most critical stage of the software release life cycle, as failures here—such as ambiguous requirements or inadequate risk assessment—create cascading problems and significant technical debt.
The primary output of this phase is a set of precise technical specifications. These must be unambiguous, defining exactly what to build and why. A vague requirement like "improve user login" is technically useless. A proper specification would be: "Implement OAuth 2.0 Authorization Code flow for Google Sign-In. The system must store the access_token and refresh_token securely in the database, encrypted at rest. The /auth/google/callback endpoint must handle token exchange and user session creation."
Defining the Release Scope and Type
A critical first step is classifying the release using semantic versioning (SemVer). This classification dictates the scope, timeline, and risk profile, setting clear expectations for both internal teams and external consumers of an API.
- Major Release (e.g., v2.0.0): Involves breaking changes. This could be a non-backward-compatible API change, a significant architectural refactor (e.g., monolith to microservices), or a major UI overhaul.
- Minor Release (e.g., v2.1.0): Adds new functionality in a backward-compatible manner. Examples include adding a new, optional endpoint to an API or introducing a new feature module.
- Patch Release (e.g., v2.1.1): Contains backward-compatible bug fixes and security patches. A patch release must never introduce new features; its sole purpose is to correct existing behavior.
This versioning strategy directly informs resource allocation and risk management. A major release may require months of planning and dedicated QA cycles, while a critical security patch might be fast-tracked through the pipeline in hours.
Technical Planning and Risk Assessment
With the scope defined, the engineering plan is formalized within an issue tracker like Jira or Azure DevOps. The product backlog is populated with user stories, which are then decomposed into discrete technical tasks, estimated using story points, and assigned to sprints.
A core tenet of this phase is proactive technical risk assessment. Elite teams identify and mitigate potential failure modes upfront. This includes analyzing architectural dependencies, potential database bottlenecks, third-party API rate limits, or the complexities of a legacy system refactor.
For each identified risk, a mitigation plan is documented. This could involve architectural spikes (time-boxed investigations), building a proof-of-concept (PoC), or designing a fallback mechanism. This foresight is what prevents catastrophic failures later in the software release life cycle.
Finally, this phase establishes the key engineering metrics, or DORA metrics, that will be used to measure the success and efficiency of the delivery process.
- Lead Time for Changes: The median time from a code commit to production release.
- Deployment Frequency: The rate at which code is deployed to production (e.g., daily, weekly).
- Change Failure Rate: The percentage of deployments that result in a production degradation requiring remediation (e.g., a rollback or hotfix).
- Time to Restore Service: The median time taken to recover from a production failure.
Setting these benchmarks establishes a data-driven baseline for continuous improvement throughout the engineering organization. At OpsMoon, we help teams instrument their pipelines to track these metrics, ensuring release goals are measurable and consistently met.
From Code Commits to Automated Builds
With a detailed blueprint in hand, the development phase begins. This is where user stories are translated into clean, maintainable, and functional code. In modern software engineering, this stage is governed by strict practices and automation to manage complexity and maintain high velocity.
Every code commit, pull request, and CI build serves as a validation gate. Rigor in this phase is essential to prevent a cascade of defects from reaching later stages of the pipeline.
Managing Code with Version Control Workflows
A robust version control strategy is the foundation of collaborative development. While Git is the de facto standard, the choice of branching workflow directly impacts how changes are integrated, tested, and released.
Two dominant workflows are:
- GitFlow: A structured model using long-lived branches like
main,develop, andrelease/*. It provides strong separation between development, release stabilization, and hotfixes. GitFlow is well-suited for projects with scheduled, versioned releases but can introduce overhead for teams practicing continuous delivery. - Trunk-Based Development (TBD): Developers commit small, frequent changes directly to a single
mainbranch (the "trunk"). Feature development occurs in short-lived feature branches that are merged quickly. TBD simplifies the branching model and is the required workflow for achieving true Continuous Integration and Continuous Deployment (CI/CD).
For most modern cloud-native applications, Trunk-Based Development is the superior strategy, as it minimizes merge conflicts and enables a faster, more direct path to production.
Automating Builds with Continuous Integration
Continuous Integration is a non-negotiable practice in this phase. The core principle is the automated merging and validation of all code changes. Continuous Integration (CI) is an automated process where every git push triggers a pipeline that builds the application and runs a suite of automated tests.
This provides developers with feedback in minutes, allowing them to identify and fix integration bugs immediately. We provide a technical breakdown of CI in our guide on what is continuous integration.
Continuous Integration is the first line of defense in the software release life cycle. It automates the error-prone manual process of code integration, creating a reliable and rapid feedback loop for the entire engineering team.
A standard CI pipeline, configured in a tool like Jenkins (using a Jenkinsfile), GitLab CI (.gitlab-ci.yml), or GitHub Actions (.github/workflows/ci.yml), executes a series of automated stages:
- Build: The pipeline compiles the source code into a runnable artifact (e.g., a Docker image, JAR file, or binary). Build failure provides instant feedback.
- Unit Testing: Fast-running automated tests are executed to verify the correctness of individual functions and classes in isolation. Code coverage metrics are often generated here.
- Static Code Analysis (SAST): Tools like SonarQube or Snyk scan the source code for security vulnerabilities (e.g., SQL injection), code smells, and adherence to coding standards without executing the application.
This automated feedback loop is what makes CI so powerful. By validating every commit, these pipelines dramatically cut down the risk of introducing defects into the main codebase.
Upholding Quality with Peer Code Reviews
While automation provides the first layer of defense, human expertise remains crucial. Peer code reviews, typically managed through pull requests (PRs) or merge requests (MRs), are a critical practice for ensuring code quality, enforcing architectural consistency, and disseminating knowledge.
Before any feature branch is merged into the trunk, at least one other engineer must review the changes for logic, correctness, readability, and adherence to design patterns. This collaborative process not only catches subtle bugs that static analysis might miss but also serves as a key mechanism for mentoring junior developers and preventing knowledge silos. An effective code review acts as the final human quality gate before the code enters the automated pipeline.
Automating Quality Gates with Continuous Testing
Once a build artifact is successfully created, it enters the next critical stage of the software release life cycle: automated testing. The archaic model of manual QA as a separate, final phase is a major bottleneck that is incompatible with modern delivery speeds. High-performing teams embed Continuous Testing directly into the delivery pipeline.
Continuous Testing is the practice of executing a comprehensive suite of automated tests as part of the pipeline to provide immediate feedback on the business risks associated with a release candidate. Each test suite acts as an automated quality gate; only artifacts that pass all gates are promoted to the next environment.
Building a Robust Testing Pyramid
Effective continuous testing requires a strategic allocation of testing effort, best visualized by the "testing pyramid." This model advocates for a large base of fast, low-cost unit tests, a smaller middle layer of integration tests, and a very small number of slow, high-cost end-to-end tests.
A well-architected pyramid includes:
- Unit Tests: The foundation of the pyramid. These are written in code to test individual functions, methods, or classes in isolation, using mocks and stubs to remove external dependencies. They are extremely fast and should run on every commit.
- Integration Tests: This layer verifies the interaction between different components. This can include testing the communication between two microservices, or verifying that the application can correctly read from and write to a database.
- End-to-End (E2E) Tests: Simulating real user scenarios, these tests drive the application through its UI to validate complete workflows. While valuable, they are slow, brittle, and expensive to maintain. They are best executed against a fully deployed application in a staging environment using frameworks like Selenium, Cypress, or Playwright.
Embedding this pyramid into the CI/CD pipeline ensures that defects are caught at the earliest and cheapest stage. For a detailed implementation guide, see our article on how to automate software testing.
Integrating Advanced Testing Disciplines
Functional correctness is necessary but not sufficient for a production-ready application. A modern software release life cycle must also validate non-functional requirements like performance, scalability, and security.
Integrating these advanced disciplines is critical. A feature that is functionally correct but has a critical security vulnerability or cannot handle production load is a failed release. Despite the goal of the Software Development Life Cycle (SDLC) to improve quality, studies show only 31% of projects meet their original goals. A mature, automated testing strategy is the key to closing this gap. You can find more data on how SDLC frameworks reduce project risks at zencoder.ai.
By integrating performance and security testing into the delivery pipeline, you shift these concerns "left," transforming them from late-stage, expensive discoveries into automated, routine quality checks.
The table below outlines key testing types, their technical purpose, and their placement in the release cycle.
| Modern Testing Types and Their Purpose in the SRLC | |||
|---|---|---|---|
| Testing Type | Primary Purpose | Execution Stage | Example Tools |
| Unit Testing | Validates individual functions or components in isolation. | CI (on every commit) | Jest, JUnit, PyTest |
| Integration Testing | Ensures different application components work together correctly. | CI (on every commit/PR) | Supertest, Testcontainers |
| End-to-End Testing | Simulates full user journeys to validate workflows from start to finish. | CI/CD (post-deployment to a test environment) | Cypress, Selenium, Playwright |
| Performance Testing | Measures system responsiveness, stability, and scalability under load. | CD (in staging or pre-prod environments) | JMeter, Gatling |
| Security Testing (DAST) | Scans a running application for common security vulnerabilities. | CD (in staging or QA environments) | OWASP ZAP, Burp Suite |
By automating these layers of validation, you create a robust pipeline where only the most functionally correct, performant, and secure artifacts are approved for final deployment.
Mastering Automated Deployment Strategies
After an artifact has successfully navigated all automated quality gates, it is staged for production deployment. This is the pivotal moment in the software release life cycle where new code is exposed to live users.
In legacy environments, deployment is often a high-stress, manual, and error-prone event. Modern DevOps practices transform deployment into a low-risk, automated, and routine activity. This is achieved through Continuous Deployment (CD), the practice of automatically deploying every change that passes the automated test suite directly to production. The goal of CD is to make deployments a non-event, enabling a rapid and reliable flow of value to users.
Implementing Advanced Deployment Patterns
The key to safe, automated deployment is the use of advanced patterns that enable zero-downtime releases. Instead of a high-risk "big bang" deployment, these strategies progressively introduce new code, minimizing the blast radius of any potential issues.
Every modern engineering team must master these patterns:
- Blue-Green Deployment: This pattern involves maintaining two identical production environments: "Blue" (running the current version) and "Green" (running the new version). Traffic is directed to the Blue environment. The new code is deployed to the Green environment, where it can be fully tested. To release, a load balancer or router is updated to switch all traffic from Blue to Green. This provides an instantaneous release and a near-instantaneous rollback capability by simply switching traffic back to Blue.
- Canary Release: This strategy involves releasing the new version to a small subset of production traffic (e.g., 1%). The system is monitored for an increase in error rates or latency for this "canary" cohort. If metrics remain healthy, traffic is incrementally shifted to the new version until it serves 100% of requests. This allows for real-world testing with minimal user impact.
- Rolling Deployment: The new version is deployed by incrementally replacing old instances of the application with new ones, either one by one or in batches. This ensures that the application remains available throughout the deployment process, as there are always healthy instances serving traffic. This is the default deployment strategy in orchestrators like Kubernetes.
These strategies are no longer exclusive to large tech companies. Orchestration tools like Kubernetes and Infrastructure as Code (IaC) tools like Ansible and Terraform, combined with cloud services like AWS CodeDeploy, have democratized these powerful deployment techniques.
Managing Critical Release Components
A successful deployment involves more than just the application code. Other dependencies must be managed with the same level of automation and version control. Neglecting these components is a common cause of deployment failures.
The release frequency itself is highly dependent on industry and regulatory constraints. Gaming companies may deploy weekly (~52 releases/year), while e-commerce platforms average 24 annual updates. Highly regulated sectors like banking (4 times yearly) and healthcare (every four months) have slower cadences due to compliance overhead. For a deeper analysis, see this article on how industry demands influence software release frequency on eltegra.ai.
Regardless of release cadence, the primary technical goal is to decouple deployment from release. This means code can be deployed to production infrastructure without being exposed to users, typically via feature flags, providing ultimate control and risk reduction.
Here's how to manage critical deployment components:
- Automated Database Migrations: Database schema changes must be version-controlled and applied automatically as part of the deployment pipeline. Tools like Flyway or Liquibase integrate into the CD process to apply migrations idempotently and safely.
- Secure Secrets Management: API keys, database credentials, and other secrets must never be stored in source control. They should be managed in a dedicated secrets management system like HashiCorp Vault or AWS Secrets Manager and injected into the application environment at runtime.
- Strategic Feature Flags: Feature flags (or toggles) are a powerful technique for decoupling deployment from release. They allow new code paths to be deployed to production in a "dark" or inactive state. This enables testing in production, progressive rollouts to specific user segments, and an "instant off" kill switch for features that misbehave.
Closing the Loop with Proactive Monitoring
Deployment is not the end of the life cycle; it is the beginning of the operational phase. Once code is running in production, the objective shifts to ensuring its health, performance, and correctness. This final phase closes the loop by feeding real-world operational data back into the development process.
This is the domain of proactive monitoring and observability.
Post-deployment, a robust continuous monitoring strategy is essential. This is not passive dashboarding; it is the active collection and analysis of telemetry data to understand the system's internal state and identify issues before they impact users.
The Three Pillars of Modern Observability
To achieve true observability in a complex, distributed system, you need to collect and correlate three distinct types of telemetry data. These are often called the "three pillars of observability."
- Logs: These are immutable, timestamped records of discrete events. Implementing structured logging (e.g., outputting logs in JSON format) is critical. This transforms logs from simple text into a queryable dataset, enabling rapid debugging and analysis.
- Metrics: These are numerical representations of system health over time (time-series data). Key Application Performance Monitoring (APM) metrics include request latency (especially p95 and p99), error rates (e.g., HTTP 5xx), and resource utilization (CPU, memory).
- Traces: A trace represents the end-to-end journey of a single request as it propagates through multiple services in a distributed system. Distributed tracing is indispensable for diagnosing latency bottlenecks and understanding complex service interactions in a microservices architecture.
From Data Collection to Actionable Alerts
Collecting telemetry is only the first step. The value is realized by using tools like Prometheus, Datadog, or Grafana to visualize this data and, crucially, to create automated, actionable alerts. The goal is to evolve from a reactive posture (responding to outages) to a proactive one (preventing outages).
This requires intelligent alerting based on statistical methods rather than simple static thresholds. Alerts should be configured based on service-level objectives (SLOs) and can leverage anomaly detection to identify deviations from normal behavior. A well-designed alerting strategy minimizes noise and ensures that on-call engineers are only notified of issues that require human intervention.
A mature observability platform doesn't just show what is broken; it provides the context to understand why. By correlating logs, metrics, and traces from a specific incident, engineering teams can dramatically reduce their Mean Time to Resolution (MTTR) by moving directly from symptom detection to root cause analysis.
Feeding Insights Back into the Cycle
This feedback loop is what makes the process a true "cycle" and drives continuous improvement. All telemetry data, user-reported bug tickets, and product analytics must be synthesized and fed directly back into the planning phase for the next iteration.
Did a deployment correlate with an increase in p99 latency? This data should trigger the creation of a technical task to investigate and optimize the relevant database query. Is a specific feature generating a high volume of exceptions in the logs? This becomes a high-priority bug fix for the next sprint.
For a deeper technical dive, read our guide on what is continuous monitoring. This data-driven approach ensures that each release cycle benefits from the operational lessons of the previous one, creating a powerful engine for building more resilient and reliable software.
Got Questions? We've Got Answers
Let's address some common technical questions about the software release life cycle.
What's the Difference Between SDLC and SRLC?
While related, these terms describe different scopes. The Software Development Life Cycle (SDLC) is the all-encompassing macro-process that covers a product's entire lifespan, from initial conception and requirements gathering through development, maintenance, and eventual decommissioning.
The Software Release Life Cycle (SRLC) is a specific, operational, and repeatable sub-process within the SDLC. It is the tactical, automated workflow for taking a set of code changes (a new version) through the build, test, deploy, and monitoring phases.
Analogy: The SDLC is the entire process of designing and manufacturing a new aircraft model. The SRLC is the specific, automated assembly line process used to build and certify each individual aircraft unit that rolls out of the factory.
How Does CI/CD Fit into All This?
CI/CD (Continuous Integration/Continuous Deployment) is not separate from the SRLC; it is the automation engine that implements a modern, high-velocity SRLC. It provides the technical foundation for the core phases.
These practices map directly to specific SRLC stages:
- Continuous Integration (CI) is the core practice of the Development and Testing phases. It is an automated system where every commit triggers a build and the execution of unit tests and static analysis, providing rapid feedback to developers.
- Continuous Deployment (CD) is the practice that automates the Deployment phase. Once an artifact passes all preceding quality gates in the CI pipeline, CD automatically promotes and deploys it to the production environment without manual intervention.
In essence, CI/CD is the machinery that makes a modern, agile software release life cycle possible.
What’s the Most Critical Phase of the Release Life Cycle?
From an engineering and risk management perspective, the Strategic Planning phase is arguably the most critical. While a failure in any phase is problematic, errors and ambiguities introduced during planning have a compounding negative effect on all subsequent stages.
Why? A poorly defined technical specification, an incomplete risk assessment, or an incorrect architectural decision during planning will inevitably lead to rework during development, extensive bugs discovered during testing, and a high-risk, stressful deployment. The cost of fixing a design flaw is orders of magnitude higher once it has been implemented in code.
A rigorous, technically detailed planning phase is the foundation of the entire release. It enables every subsequent phase to proceed with clarity, predictability, and reduced risk, setting the entire team up for a successful production release.
Ready to build a rock-solid software release life cycle with elite engineering talent? At OpsMoon, we connect you with the top 0.7% of remote DevOps experts who can optimize your pipelines, automate deployments, and implement proactive monitoring. Start with a free work planning session to map out your technical roadmap. Find your expert at opsmoon.com