Mastering the Software Release Cycle: A Technical Guide
 By opsmoon
By opsmoonA technical guide to mastering the modern software release cycle. Learn the stages, tools, and best practices to ship reliable software faster than ever.
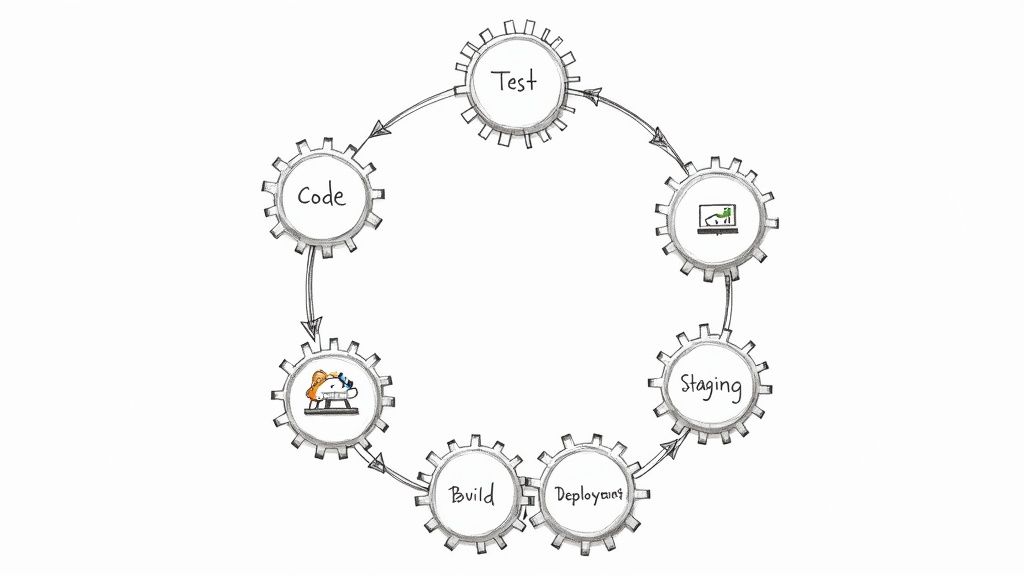
The software release cycle is the blueprint that guides a new software version from a developer's local machine to the end-user's environment. It is a repeatable, structured process that ensures every update is predictable, stable, and functionally correct. Think of it as the operational backbone for compiling raw source code into a reliable, production-grade product your customers can depend on.
Demystifying the Software Release Cycle
At its core, the software release cycle is a technical assembly line for digital products. It ingests fragmented pieces—new features, bug fixes, performance refactors—and systematically moves them through a series of automated checkpoints. These stages include compiling the code into an artifact, executing a battery of tests, and deploying to a staging environment before it ever reaches a production server.
Without this kind of structured approach, software development quickly descends into chaos. You end up with delayed launches, critical bugs slipping into production, and significant user friction.
A well-defined cycle aligns the entire engineering organization on a unified workflow. It provides clear, technical answers to critical questions like:
- What is the specific Git branching strategy we use for features versus hotfixes?
- How do we guarantee this update won't break existing API contracts?
- What is the exact, step-by-step process for deploying a containerized application to our Kubernetes cluster?
This clarity is what solves the dreaded "it works on my machine" problem. By creating consistent, scripted environments for every stage of the process, you eliminate environmental drift and deployment surprises.
The Technical Mission Behind the Method
The main goal of any software release cycle is to optimize the trade-off between velocity and stability. If you deploy too fast without sufficient automated quality gates, you introduce unacceptable operational risk. But if you're too slow and overly cautious with manual checks, you’ll lose your competitive edge. A mature cycle hits that sweet spot through robust automation.
It enables teams to deliver value to customers quickly without sacrificing the quality of the product. This means building a CI/CD pipeline that is both rigorous and efficient. For a deeper look into the broader journey from initial concept all the way to product retirement, you can explore our detailed guide on the software release lifecycle.
This framework also acts as a vital communication tool. It gives non-technical stakeholders—like product managers, marketers, and support teams—the visibility they need. They can prepare for launch campaigns, update user documentation, and get ready for the wave of customer feedback.
A disciplined release cycle transforms software delivery from an art into a science. It replaces guesswork and last-minute heroics with a predictable, data-driven process that builds stakeholder confidence and user trust with every successful release.
Ultimately, mastering the software release cycle is non-negotiable for any team that's serious about building and maintaining a successful software product. It’s the foundation for everything else, setting the stage for the technical stages, tooling, and strategies we'll dive into next.
The Six Core Stages of a Modern Release Cycle
The software release cycle is the structured journey that takes a single line of code and turns it into a valuable, working feature in your users' hands. You can think of it as a six-stage pipeline. Each stage adds another layer of quality and confidence before the work moves on to the next. Getting this flow right is the key to shipping software that's both fast and stable.
This whole process is built on a foundation of solid planning and clear steps, which is what makes a release predictable and repeatable time after time.
Let's walk through what actually happens at each stage of this journey.
To give you a quick overview, here’s a breakdown of the core stages, their main goal, and the key activities that happen in each.
Core Stages of the Software Release Cycle
| Stage | Objective | Key Technical Activities |
|---|---|---|
| Development | Translate requirements into functional source code. | Writing code, fixing bugs, and pushing commits to a feature branch in a version control system. |
| Build | Compile code into a runnable artifact and run initial checks. | Compiling source code, running linters, executing unit tests, and performing static code analysis (SAST). |
| Testing & QA | Rigorously validate the software for quality, security, and performance. | Integration testing, API contract testing, End-to-End (E2E) testing, dependency security scans (SCA), and manual QA. |
| Staging | Conduct a final dress rehearsal in a production-like environment. | User Acceptance Testing (UAT), final performance validation, and load testing against production-scale data. |
| Production Release | Deploy the new version to end-users safely and with minimal risk. | Blue-green deployments, canary releases, and phased rollouts using traffic-shifting mechanisms. |
| Post-Release Monitoring | Ensure the application is healthy and performing as expected in the live environment. | Tracking error rates, API latency, resource utilization (CPU/memory), and key business metrics. |
Now, let's dive a little deeper into what each of these stages really involves.
Stage 1: Development
This is where it all begins—the implementation phase. Developers translate user stories and bug tickets into tangible code. They write new features, patch bugs, and refactor existing code for better performance or maintainability.
The most critical action here is committing that code to a version control system like Git. Every git push to a feature branch is the trigger for the automated CI/CD pipeline, kicking off the hand-off from human logic to a machine-driven validation process.
Stage 2: Build
As soon as code is pushed, the build stage kicks into gear. A Continuous Integration (CI) server pulls the latest changes from the repository and compiles everything into a single, deployable artifact (e.g., a JAR file, a Docker image, or a static binary).
But it's not just about compilation. The CI server also runs a few crucial, automated checks:
- Static Code Analysis (SAST): Tools like SonarQube or Checkmarx scan the raw source code for security vulnerabilities (e.g., SQL injection), code smells, and bugs without executing it.
- Unit Tests: These are fast, isolated tests that verify the logic of individual functions or classes. High test coverage at this stage is critical for rapid feedback.
If the build fails or a unit test breaks, the entire pipeline halts immediately. The developer gets a notification via Slack or email. This fast feedback loop is essential for preventing broken code from ever being merged into the main branch.
Stage 3: Testing and QA
Now the focus shifts to comprehensive quality validation. This is where the artifact is put through a gauntlet of tests to ensure it's stable, secure, and performant.
The industry has leaned heavily into automation here. Recent data shows that about 50% of organizations now use automated testing, which has helped slash release cycles by 30% and cut down on bugs by roughly 25%. For a closer look at how the industry is evolving, check out these insightful software development statistics.
Key automated tests in this phase include:
- Integration Testing: Verifies that different modules or microservices work correctly together. This often involves spinning up dependent services like a database in a test environment.
- End-to-End (E2E) Testing: Simulates a real user's journey through the application UI to validate critical workflows from start to finish.
- Performance Testing: Tools like JMeter or Gatling put the application under heavy load to identify performance bottlenecks and measure response times.
- Security Scans: Dynamic Application Security Testing (DAST) and Software Composition Analysis (SCA) tools scan for runtime vulnerabilities and known issues in third-party libraries.
This stage is a partnership between automated scripts and human QA engineers who perform exploratory testing to find edge cases that automation might miss.
Stage 4: Staging
The staging environment is a mirror image of production. It should use the same infrastructure-as-code templates, the same network configurations, and a recent, anonymized copy of the production database. Deploying the software here is the final dress rehearsal.
The purpose of staging is to answer one critical question: "Will this release work exactly as we expect it to in the production environment?"
This is the last chance to spot environment-specific issues in a safe, controlled setting. It’s where teams conduct User Acceptance Testing (UAT), giving product managers a chance to validate that the new features meet business requirements.
Stage 5: Production Release
This is the moment the new software version goes live. Modern teams avoid "big bang" deployments by using progressive delivery strategies to minimize risk.
Two of the most common technical approaches are:
- Blue-Green Deployment: You run two identical production environments ("Blue" and "Green"). If Blue is live, you deploy the new version to the idle Green environment. After verifying Green is healthy, you reconfigure the load balancer or DNS to switch all traffic to it. If an issue occurs, rollback is as simple as switching traffic back to Blue.
- Canary Release: The new version is released to a small subset of production traffic—say, 5%. The team closely monitors telemetry data. If error rates and latency remain stable, they incrementally increase the traffic percentage (e.g., to 25%, 50%, and then 100%) until the rollout is complete.
Stage 6: Post-Release Monitoring
The job isn't done just because the code is live. The final stage is all about observing the application's health and performance in production. This is a shared responsibility between operations, Site Reliability Engineers (SREs), and developers, following the "you build it, you run it" principle.
Teams use observability platforms to track key signals: error rates (e.g., HTTP 5xx), response times (p95, p99 latency), CPU and memory utilization, and application-specific metrics. If any of these metrics deviate from their baseline after a release, it’s an all-hands-on-deck situation. This data-driven approach means teams can detect and remediate production issues rapidly.
Choosing Your Release Strategy and Cadence
Selecting a release strategy and cadence is a critical technical and business decision. The right approach can accelerate your time-to-market, while the wrong one can lead to missed deadlines and engineering burnout. The optimal strategy is a function of your product's architecture, your team's operational maturity, and your market's demands.
Think of it like choosing a deployment method. A monolithic application might be best suited for a scheduled release train, while a decoupled microservices architecture is built for rapid, continuous releases. The goal is to match your release methodology to your technical and business context.
Time-Based Releases: Predictability and Structure
Time-based releases, often called "release trains," deploy on a fixed schedule, such as weekly, bi-weekly, or quarterly. Any features and bug fixes that have passed all QA checks by the "code freeze" date are included in the release candidate.
This model is common in large enterprises or regulated industries like finance and healthcare, where predictability is paramount.
- Marketing and Sales: Teams have a concrete date to build campaigns around.
- Customer Support: Staff can be trained and documentation updated in advance.
- Stakeholders: Everyone receives a clear roadmap and timeline for feature delivery.
The trade-off is velocity. A critical feature completed one day after the code freeze must wait for the next release train, which could be weeks away. This can create a significant delay in delivering value.
Feature-Based Releases: Delivering Complete Value
A feature-based strategy decouples releases from the calendar. A new version is shipped only when a specific feature or a cohesive set of features is fully implemented and tested. Value delivery, not a date, triggers the release.
This approach is a natural fit for product-led organizations focused on delivering a complete, impactful user experience in a single update. It ensures users receive a polished, fully-functional feature, not a collection of minor, unrelated changes. The main challenge is managing release date expectations, as unforeseen technical complexity can cause delays.
Continuous Deployment: The Gold Standard of Speed
Continuous Deployment (CD) is the apex of release agility. In this model, every single commit to the main branch that passes the entire suite of automated tests is automatically deployed to production, often within minutes. This can result in multiple production releases per day.
Continuous Deployment is the ultimate expression of confidence in your automation and testing pipeline. It’s a system where the pipeline itself, not a human, makes the final go/no-go decision for every single change.
This is the standard for competitive SaaS products and tech giants. It enables rapid iteration, A/B testing, and immediate feedback from real user traffic. However, it requires a mature engineering culture, high automated test coverage, and robust monitoring and rollback capabilities. It’s a core principle of the DevOps methodology.
How to Choose Your Cadence
Selecting the right strategy requires a pragmatic technical assessment. Adopting continuous deployment because it’s trendy can be disastrous if your test automation and monitoring are not mature enough. For many organizations, a critical goal is ensuring seamless updates, so it's wise to explore various zero downtime deployment strategies that can complement your chosen cadence.
To determine your optimal cadence, ask these questions:
- Product and Market: Does your market demand constant feature velocity, or does it prioritize stability and predictability? A B2C mobile app has different release pressures than an enterprise ERP system.
- Team Maturity and Tooling: Do you have a robust CI/CD pipeline with comprehensive automated test coverage (e.g., >80% code coverage for unit tests)? Is your team disciplined with trunk-based development and peer reviews?
- Risk Tolerance: What is the technical and business impact of a production bug? A minor UI glitch is an inconvenience; a data corruption bug is a catastrophic failure that requires immediate rollback.
By carefully evaluating these factors, you can design a software release cycle that aligns your technical capabilities with your business objectives, ensuring every release delivers maximum impact with minimum risk.
Essential Tooling for an Automated Release Pipeline
A modern software release cycle is not a series of manual handoffs; it's a highly choreographed, automated workflow powered by an integrated toolchain. This CI/CD (Continuous Integration/Continuous Deployment) pipeline is the engine that transforms a git push command into a live, monitored feature with minimal human intervention.
Selecting the right tools doesn’t just increase velocity. It enforces engineering standards, improves quality through repeatable processes, and creates the tight feedback loops that define high-performing teams. Each tool in this pipeline has a specific, critical job in a chain of automated events.

Version Control: The Single Source of Truth
Every action in a modern release cycle originates from a Version Control System (VCS). It serves as the project's immutable ledger, meticulously tracking every code change, the author, and the timestamp.
Git is the industry standard. When a developer executes a git push, it acts as a webhook trigger for the entire automated pipeline. This single action initiates the build, test, and deploy sequence, ensuring every release is based on a known, auditable state of the codebase.
CI/CD Platforms: The Pipeline's Conductor
Once code is pushed, a CI/CD platform orchestrates the entire workflow. This tool is the central nervous system of your automation, executing the predefined stages of your release pipeline. It continuously listens for changes in your Git repository and immediately puts the new code into motion.
Key platforms include:
- Jenkins: An open-source, highly extensible automation server known for its flexibility and massive plugin ecosystem.
- GitLab CI/CD: Tightly integrated into the GitLab platform, it provides a seamless experience from source code management to deployment within a single application.
These platforms automate the heavy lifting of building artifacts and running initial tests, ensuring every commit is validated.
Containerization and Orchestration: Building Predictable Environments
One of the most persistent problems in software delivery is environmental inconsistency—the "it works on my machine" syndrome. Containerization solves this by packaging an application with all its dependencies (libraries, binaries, configuration files) into a standardized, isolated unit.
A container is a lightweight, standalone, executable package of software that includes everything needed to run it. This guarantees that the software will always run the same way, regardless of the deployment environment.
Docker is the de facto standard for containerization. However, managing hundreds or thousands of containers across a cluster of servers requires an orchestration platform.
Kubernetes (K8s) has become the industry standard for managing containerized applications at scale. It automates the deployment, scaling, and operational management of your containers, ensuring high availability and resilience for production workloads.
Automated Testing and Observability: The Quality Gates
With the application containerized and ready for deployment, the pipeline proceeds to rigorous quality checks. Automated Testing Frameworks act as quality gates that prevent bugs from reaching production.
- Selenium is a powerful tool for browser automation, ideal for end-to-end testing of complex user interfaces and workflows.
- Cypress offers a more modern, developer-centric approach to E2E testing, known for its speed and reliability.
The process doesn't end at deployment. Observability Platforms serve as your eyes and ears in production, collecting detailed telemetry (metrics, logs, and traces) to provide deep insight into your application's real-time health.
Tools like Prometheus (for time-series metrics and alerting) and Datadog (a comprehensive monitoring platform) are essential for post-release monitoring. They enable teams to rapidly detect and diagnose production issues, often before users are impacted.
The rise of these powerful tools is happening as enterprise software investment is projected to hit $1.25 trillion globally. This push is heavily influenced by new AI coding assistants, now used by a staggering 92% of developers in the U.S. to speed up their work. To see what's driving this trend, you can discover more insights about software development statistics on designrush.com. This entire toolchain creates a powerful, self-reinforcing loop that defines what a mature software release cycle looks like today.
Best Practices for a High-Performing Release Process
Implementing the right tools and stages is foundational, but transforming a functional software release cycle into a high-performing engine requires technical discipline and proven best practices. Elite engineering teams don't just follow the process; they relentlessly optimize it. Adopting these battle-tested practices is what separates chaotic, high-stress deployments from the smooth, predictable releases that enable business agility.
This is about moving beyond simple task automation. It's about building a culture of proactive quality control and systematic risk reduction. The goal is to build a system so robust that deploying to production feels routine, not like a high-stakes gamble.

Implement a Robust Automated Testing Pyramid
A high-velocity release process is built on a foundation of comprehensive automated testing. The "testing pyramid" is a strategic framework that allocates testing effort effectively. It advocates for a large volume of fast, low-level tests at the base and a smaller number of slow, high-level tests at the peak.
- Unit Tests (The Base): This is the largest part of your testing suite. These are fast, isolated tests that verify individual functions or classes. A strong unit test foundation with high code coverage catches the majority of bugs early in the development cycle, where they are cheapest to fix.
- Integration Tests (The Middle): This layer validates the interactions between different components or services. It ensures that API contracts are honored and data flows correctly between different parts of the application.
- End-to-End Tests (The Peak): At the top are a small number of tests that simulate a complete user journey through the application's UI. These tests are valuable for validating critical business flows but are often slow and brittle, so they should be used judiciously.
A strong testing culture isn't just a technical nice-to-have; it's a huge business investment. The global software testing market is on track to hit $97.3 billion by 2032. Big companies are leading the way, with 40% dedicating over a quarter of their entire software budget to quality assurance.
Use Infrastructure as Code for Consistency
One of the primary causes of deployment failures is "environment drift," where the staging environment differs subtly but critically from production. Infrastructure as Code (IaC) eliminates this problem. It allows you to define and manage your infrastructure—servers, load balancers, network rules—using declarative configuration files (e.g., Terraform, CloudFormation) that are stored in version control.
With IaC, your environments are not just similar; they are identical, version-controlled artifacts. This completely eliminates the "it worked in staging!" problem and makes your deployments deterministic, repeatable, and auditable.
This practice guarantees that the environment you test in is exactly the same as the environment you deploy to, drastically reducing the risk of unexpected production failures. For a deeper dive into this kind of automation, check out our guide on CI/CD pipeline best practices.
Decouple Deployment from Release with Feature Flags
This is perhaps the most powerful technique for de-risking a release: separating the technical act of deploying code from the business decision of releasing a feature. Feature flags (or feature toggles) are the mechanism. They are conditional statements in your code that allow you to enable or disable functionality for users at runtime without requiring a new deployment.
This fundamentally changes your release process:
- Deploy with Confidence: You can merge and deploy new, incomplete code to production behind a "disabled" feature flag. The code is live on production servers but is not executed for any users, mitigating risk.
- Test in Production: You can then enable the feature for a small internal group or a tiny percentage of users (a "canary release") to validate its performance and functionality with real production traffic.
- Instant Rollback: If the new feature causes issues, you can instantly disable it for all users by toggling the flag in a dashboard. This is an order of magnitude faster and safer than executing a full deployment rollback.
A key part of a high-performing release process is transparency, and maintaining a comprehensive changelog is essential for tracking what's happening. A well-kept log, like Obsibrain's Changelog, ensures everyone on the team knows what changes are being flagged and released. By adopting these practices, you transform your team from reactive firefighters into proactive builders who ship high-quality software with confidence.
Frequently Asked Questions
Even the most optimized software release cycle encounters technical challenges. Getting stuck on architectural questions or operational hurdles can kill momentum. Here are clear, technical answers to the most common questions.
These are not just textbook definitions; they are practical insights to help you refine your process, whether you are building your first CI/CD pipeline or optimizing a mature one for higher performance.
What Is the Main Difference Between Continuous Delivery and Continuous Deployment?
This is a critical distinction that comes down to a single, final step: the deployment to production. Both Continuous Delivery and Continuous Deployment rely on a fully automated pipeline that builds and tests every code change committed to the main branch.
The divergence occurs at the final gate to production.
-
Continuous Delivery: In this model, every change that passes all automated tests is automatically deployed to a production-like staging environment. The artifact is proven to be "releasable." However, the final push to production requires a manual trigger, such as a button click. This keeps a human in the loop for final business approval or to coordinate the release with other activities.
-
Continuous Deployment: This model takes automation one step further. If a build passes every single automated quality gate, it is automatically deployed directly to production without any human intervention. This is the goal for high-velocity teams who have extreme confidence in their test automation and monitoring capabilities.
The core difference is the final trigger. Continuous Delivery ensures a release is ready to go at any time, while Continuous Deployment automatically executes the release.
How Do Feature Flags Improve the Release Cycle?
Feature flags (or feature toggles) are conditional logic in your code that allows you to dynamically enable or disable functionality at runtime. They are a powerful technique for decoupling code deployment from feature release, which provides several technical advantages for your release cycle.
- Eliminate Large, Risky Releases: You can merge and deploy small, incremental code changes into production behind a "disabled" flag. This avoids the need for long-lived feature branches that are difficult to merge and allows teams to ship smaller, less risky changes continuously.
- Enable Testing in Production: Feature flags allow you to safely expose a new feature to a controlled audience in the production environment—first to internal teams, then to a small percentage of beta users. This provides invaluable feedback on how the code behaves under real production load and with real user data.
- Instantaneous Rollback: If a newly enabled feature causes production issues (e.g., a spike in error rates or latency), you can instantly disable it by toggling the flag. This is a much faster and safer remediation action than a full deployment rollback, which can take several minutes and is itself a risky operation.
What Are the Most Critical Metrics to Monitor Post-Release?
Post-release monitoring is your first line of defense against production incidents. While application-specific metrics are important, a few key signals are universally critical for assessing the health of a new release.
The industry standard is to start with the "Four Golden Signals" of monitoring:
- Latency: The time it takes to service a request, typically measured at the 50th, 95th, and 99th percentiles. A sudden increase in p99 latency after a release often indicates a performance bottleneck affecting a subset of users.
- Traffic: A measure of demand on your system, often expressed in requests per second (RPS). Monitoring traffic helps you understand load and capacity.
- Errors: The rate of requests that fail, such as HTTP 500 errors. A sharp increase in the error rate is a clear and immediate signal that a release has introduced a critical bug.
- Saturation: A measure of how "full" your system is, typically focused on its most constrained resources (e.g., CPU utilization, memory usage, or disk I/O). High saturation indicates the system is approaching its capacity limit and is a leading indicator of future outages.
Beyond these four, you should monitor application performance monitoring (APM) data for transaction traces, user-facing crash reports from the client-side, and key business metrics (e.g., user sign-ups or completed purchases) to ensure the release is having the desired impact.
Ready to build a high-performing, automated software release cycle without the overhead? OpsMoon provides elite, remote DevOps engineers and tailored project support to optimize your entire delivery pipeline. Start with a free work planning session to map out your roadmap and match with the top-tier talent you need to accelerate your releases with confidence.