A Technical Deep Dive into the Phases of the Software Development Process
 By opsmoon
By opsmoonDiscover the key phases of the software development process, their objectives, tools, and best practices to ensure successful project delivery.
The phases of the software development process, collectively known as the Software Development Life Cycle (SDLC), provide a systematic engineering discipline for converting a conceptual requirement into a deployed and maintained software system. This structured framework is not merely a project management tool; it's an engineering blueprint designed to enforce quality, manage complexity, and ensure predictable outcomes in software delivery.
The SDLC: An Engineering Blueprint for Software Delivery
Before any code is compiled, a robust SDLC provides the foundational strategy. Its primary function is to deconstruct the complex, often abstract, process of software creation into a series of discrete, verifiable stages. Each phase has defined inputs, processes, and deliverables, creating a clear chain of accountability. This structured approach mitigates common project failure modes like scope creep, budget overruns, and catastrophic delays by establishing clear checkpoints for validation and stakeholder alignment.
Core Methodologies Guiding the Process
Within the overarching SDLC framework, two primary methodologies dictate the execution of these phases: Waterfall and Agile. Understanding their technical and operational differences is fundamental to selecting the appropriate model for a given project.
- Waterfall Model: A sequential, linear methodology where progress flows downwards through the phases of conception, initiation, analysis, design, construction, testing, deployment, and maintenance. Each phase must be fully completed before the next begins. This model demands comprehensive upfront planning and documentation, making it suitable for projects with static, well-understood requirements where change is improbable.
- Agile Model: An iterative and incremental approach that segments the project into time-boxed development cycles known as "sprints." The core tenet is adaptive planning and continuous feedback, allowing for dynamic requirement changes. Agile prioritizes working software and stakeholder collaboration over exhaustive documentation.
The selection between Waterfall and Agile is a critical architectural decision. It dictates the project's risk management strategy, stakeholder engagement model, and velocity. The choice fundamentally defines the technical and operational trajectory of the entire development effort.
Modern engineering practices often employ hybrid models. The rise of the DevOps methodology further evolves this by integrating development and operations, aiming to automate and shorten the systems development life cycle while delivering features, fixes, and updates in close alignment with business objectives. For a more exhaustive look at the entire process, this a complete guide to Software Development Lifecycle Phases is an excellent resource.
Phase 1 Requirement Analysis and Planning

This initial phase is the engineering bedrock of the project. Analogous to drafting architectural blueprints for a structure, any ambiguity or error introduced here will propagate and amplify, leading to systemic failures in later stages. The objective is to translate abstract business needs into precise, unambiguous, and verifiable technical requirements. Failure at this stage is a leading cause of project failure, resulting in significant cost overruns due to rework.
Mastering Requirement Elicitation
Effective requirement elicitation is an active, investigative process. It moves beyond passive data collection to structured stakeholder interviews, workshops, and business process analysis. The objective is to deconstruct vague requests like "the system needs to be faster" into quantifiable metrics, user workflows, and specific business outcomes that define performance targets (e.g., "API response time for endpoint X must be <200ms under a load of 500 concurrent users").
Following initial data gathering, a feasibility study is executed to validate the project's viability across key dimensions:
- Technical Feasibility: Assesses the availability of required technology, infrastructure, and technical expertise.
- Economic Feasibility: Conducts a cost-benefit analysis to determine if the projected return on investment (ROI) justifies the development costs.
- Operational Feasibility: Evaluates how the proposed system will integrate with existing business processes and whether it will meet user acceptance criteria.
Defining Scope and Documenting Specifications
With validated requirements, the next deliverable is the Software Requirement Specification (SRS) document. This document becomes the definitive source of truth, meticulously detailing the system's behavior and constraints.
The SRS functions as a technical contract between stakeholders and the engineering team. It is the primary defense against scope creep by establishing immutable boundaries for the project's deliverables.
A well-architected SRS clearly delineates between two requirement types:
- Functional Requirements: Define the system's specific behaviors (e.g., "The system shall authenticate users via OAuth 2.0 with a JWT token.").
- Non-Functional Requirements (NFRs): Define the system's quality attributes (e.g., "The system must maintain 99.9% uptime," or "All sensitive data must be encrypted at rest using AES-256.").
To make these requirements actionable, engineering teams often use user story mapping to visualize the user journey and prioritize features based on business value. Acceptance criteria are then formalized using a behavior-driven development (BDD) syntax like Gherkin:
Given the user is authenticated and has 'editor' permissions,When the user submits a POST request to the /articles endpoint with a valid JSON payload,Then the system shall respond with a 201 status code and the created article object.
This precise, testable format ensures a shared understanding of "done" among developers, QA engineers, and product owners. This precision is a driver behind Agile's dominance; a 2023 report showed that 71% of organizations now use Agile, seeking to accelerate value delivery and improve alignment with business outcomes. You can discover more insights about Agile adoption trends on notta.ai.
Phase 2: System Design And Architecture
With the what defined by the Software Requirement Specification (SRS), this phase addresses the how. Here, abstract requirements are translated into a concrete technical blueprint, defining the system's architecture, components, modules, interfaces, and data structures. The decisions made in this phase have profound, long-term implications for the system's scalability, maintainability, and total cost of ownership. An architectural flaw here introduces significant technical debt—a system that is brittle, difficult to modify, and unable to scale.
High-Level Design: The System Blueprint
The High-Level Design (HLD) provides a macro-level, 30,000-foot view of the system. It defines the major components and their interactions, establishing the core architectural patterns. A primary decision at this stage is the choice between Monolithic and Microservices architectures.
- Monolithic Architecture: A traditional model where the entire application is built as a single, tightly coupled unit. The UI, business logic, and data access layers are all contained within one codebase and deployed as a single artifact.
- Microservices Architecture: A modern architectural style that structures an application as a collection of loosely coupled, independently deployable services. Each service is organized around a specific business capability, runs in its own process, and communicates via well-defined APIs.
The optimal choice is a trade-off analysis based on complexity, scalability requirements, and team structure.
This infographic illustrates the key considerations during the design phase.
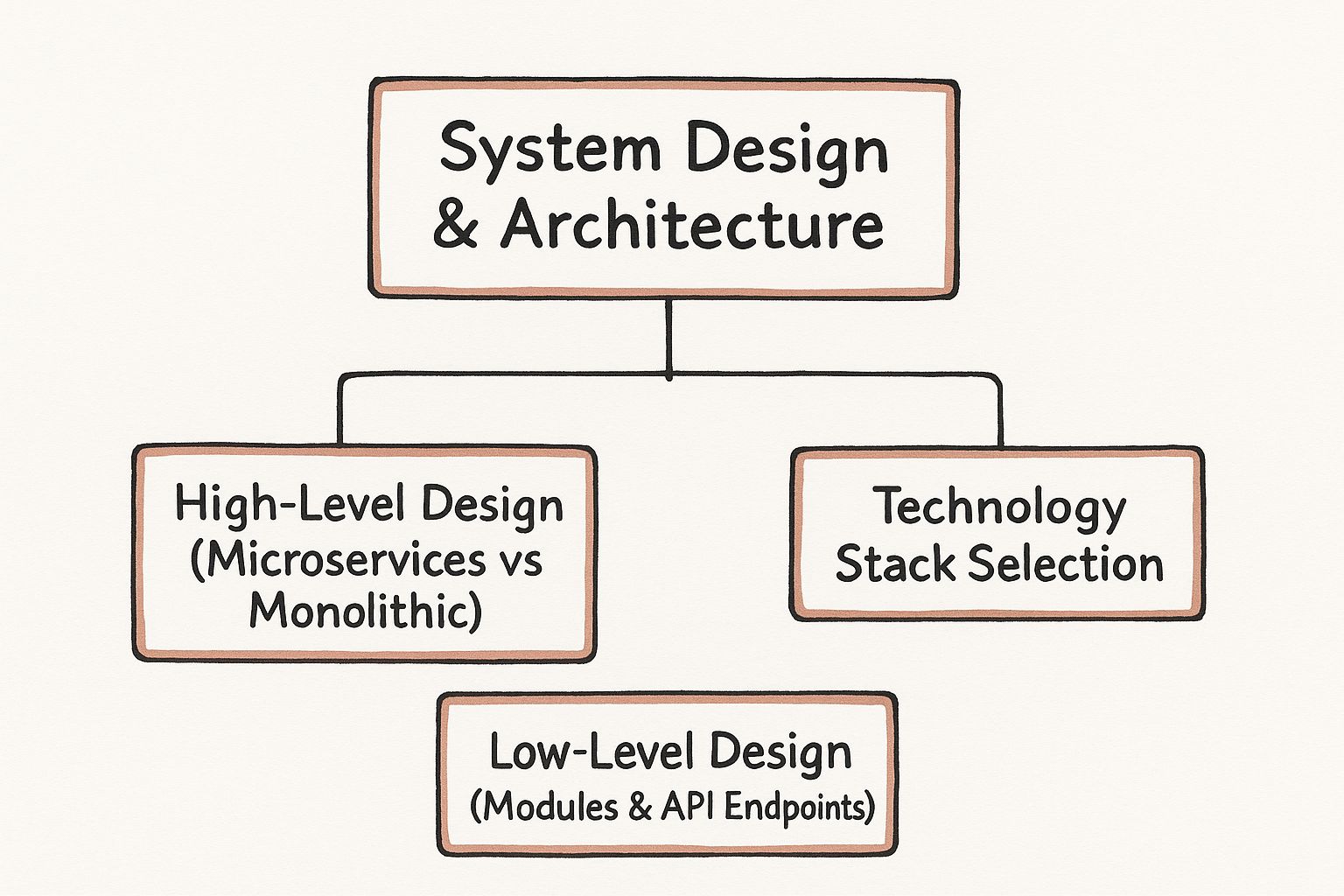
The process flows from strategic architectural decisions down to granular component design and technology selection.
Comparison of Architectural Patterns
| Attribute | Monolithic Architecture | Microservices Architecture |
|---|---|---|
| Development Complexity | Lower initial complexity; single codebase and IDE setup. | Higher upfront complexity; requires service discovery, distributed tracing, and resilient communication patterns (e.g., circuit breakers). |
| Scalability | Horizontal scaling requires duplicating the entire application stack. | Granular scaling; services can be scaled independently based on their specific resource needs. |
| Deployment | Simple, atomic deployment of a single unit. | Complex; requires robust CI/CD pipelines, container orchestration (e.g., Kubernetes), and infrastructure as code (IaC). |
| Technology Stack | Homogeneous; constrained to a single technology stack. | Polyglot; allows each service to use the optimal technology for its specific function. |
| Fault Isolation | Low; an unhandled exception can crash the entire application. | High; failure in one service is isolated and does not cascade, assuming proper resilience patterns are implemented. |
| Team Structure | Conducive to large, centralized teams. | Aligns with Conway's Law, enabling small, autonomous teams to own services end-to-end. |
The decision must align with the project's non-functional requirements and the organization's long-term technical strategy.
Low-Level Design: Getting Into The Weeds
Following HLD approval, the Low-Level Design (LLD) phase details the internal logic of each component. This involves producing artifacts like class diagrams (UML), database schemas, API contracts (e.g., OpenAPI/Swagger specifications), and state diagrams. The LLD serves as a direct implementation guide for developers.
Adherence to engineering principles like SOLID and DRY (Don't Repeat Yourself) during the LLD is non-negotiable for building maintainable systems. It is the primary mechanism for managing complexity and reducing the likelihood of future bugs.
The LLD specifies function signatures, data structures, and algorithms, ensuring that independently developed modules integrate seamlessly. A strong understanding of core system design principles is what separates a fragile system from a robust one.
Selecting The Right Technology Stack
Concurrent with design, the technology stack—the collection of programming languages, frameworks, libraries, and databases—is selected. This is a critical decision driven by NFRs like performance benchmarks, scalability targets, security requirements, and existing team expertise. Key considerations include:
- Programming Languages: (e.g., Go for high-concurrency services, Python for data science applications).
- Frameworks: (e.g., Spring Boot for enterprise Java, Django for rapid web development).
- Databases: (e.g., PostgreSQL for relational integrity, MongoDB for unstructured data, Redis for caching).
- Cloud Providers & Services: (e.g., AWS, Azure, GCP and their respective managed services).
Despite Agile's prevalence, 31% of large-scale system deployments still leverage waterfall-style phase-gate reviews for this stage. This rigorous approach ensures that all technical and architectural decisions are validated against business objectives before significant implementation investment begins.
Phase 3: Implementation and Coding
This is the phase where architectural blueprints and design documents are translated into executable code. As the core of the software development process, this phase involves more than just writing functional logic; it is an engineering discipline focused on producing clean, maintainable, and scalable software. This requires a standardized development environment, rigorous version control, adherence to coding standards, and a culture of peer review.
Setting Up for Success: The Development Environment
To eliminate "it works on my machine" syndrome—a notorious source of non-reproducible bugs—a consistent, reproducible development environment is essential. Modern engineering teams achieve this using containerization technologies like Docker. By codifying the entire environment (OS, dependencies, configurations) in a Dockerfile, developers can instantiate identical, isolated workspaces. This ensures behavioral consistency of the code across all development, testing, and production environments.
From Code to Collaboration: Version Control with Git
Every code change must be tracked within a version control system (VCS), for which Git is the de facto industry standard. A VCS serves as a complete historical ledger of the codebase, enabling parallel development streams, atomic commits, and the ability to revert to any previous state.
Git is not merely a backup utility; it is the foundational technology for modern collaborative software engineering. It facilitates branching strategies, enforces quality gates via pull requests, and provides a complete, auditable history of the project's evolution.
To manage concurrent development, teams adopt structured branching strategies like GitFlow. This workflow defines specific branches for features (feature/*), releases (release/*), and emergency production fixes (hotfix/*), ensuring the main branch remains stable and deployable at all times. This model provides a robust framework for managing complex projects and coordinating team contributions.
Writing Code That Lasts: Standards and Reviews
Producing functional code is the baseline expectation; professional engineering demands code that is clean, documented, and performant. This is enforced through two primary practices: coding standards and peer code reviews.
Coding standards define a consistent style, naming conventions, and architectural patterns for the codebase. These standards are often enforced automatically by static analysis tools (linters), which integrate into the CI pipeline to ensure compliance. A comprehensive coding standard includes:
- Naming Conventions: (e.g., camelCase for variables, PascalCase for classes).
- Formatting Rules: Enforced style for indentation, line length, and spacing to improve readability.
- Architectural Patterns: Guidelines for module structure, dependency injection, and error handling to maintain design integrity.
The second critical practice is the peer code review, typically managed through a pull request (PR) or merge request (MR). Before code is merged into a shared branch, it is formally submitted for inspection by other team members.
Code reviews serve multiple critical functions:
- Defect Detection: Identifies logical errors, performance bottlenecks, and security vulnerabilities that the original author may have overlooked.
- Knowledge Dissemination: Exposes team members to different parts of the codebase, mitigating knowledge silos and creating shared ownership.
- Mentorship: Provides a practical mechanism for senior engineers to mentor junior developers on best practices and design patterns.
- Standards Enforcement: Acts as a manual quality gate to ensure adherence to coding standards and architectural principles.
By combining a containerized development environment, a disciplined Git workflow, and a rigorous review process, the implementation phase yields a high-quality, maintainable software asset, not just functional code.
Phase 4: Testing and Quality Assurance
Unverified code is a liability. The testing and quality assurance (QA) phase is a systematic engineering process designed to validate the software against its requirements, identify defects, and ensure the final product is robust, secure, and performant. This is not an adversarial process but a collaborative effort to mitigate risk and protect the user experience and business reputation. Neglecting this phase is akin to building an aircraft engine without performing stress tests—the consequences of failure in a live environment can be catastrophic.
Navigating the Testing Pyramid
A structured approach to testing is often visualized as the "testing pyramid," a model that stratifies test types by their scope, execution speed, and cost. It advocates for a "shift-left" testing culture, where testing is performed as early and as frequently as possible in the development cycle.
-
Unit Testing (The Base): This is the foundation, comprising the largest volume of tests. Unit tests verify the smallest testable parts of an application—individual functions or methods—in isolation from their dependencies, using mocks and stubs. A framework like JUnit for Java would be used to assert that a
calculateTax()function returns the correct value for a given set of inputs. These tests are fast, cheap to write, and provide rapid feedback to developers. -
Integration Testing (The Middle): This layer verifies the interaction between different modules or services. For example, an integration test would confirm that the authentication service can successfully validate credentials against the user database. These tests identify defects in the interfaces and communication protocols between components.
-
End-to-End Testing (The Peak): At the apex, E2E tests validate the entire application workflow from a user's perspective. An automation framework like Selenium would be used to script a user journey, such as logging in, adding an item to a cart, and completing a purchase. These tests provide the highest confidence but are slow, brittle, and expensive to maintain, and thus should be used judiciously for critical business flows.
Manual and Non-Functional Testing
While automation provides efficiency and repeatability, manual testing remains indispensable for exploratory testing. This is where a human tester uses their domain knowledge and intuition to interact with the application in unscripted ways, discovering edge cases and usability issues that automated scripts would miss.
Furthermore, QA extends beyond functional correctness to non-functional requirements (NFRs).
Quality assurance is not merely a bug hunt; it is a holistic verification process that confirms the software is not only functionally correct but also resilient, secure, and performant under real-world conditions. It elevates code from a fragile asset to a production-ready product.
Key non-functional tests include:
- Performance Testing: Measures system responsiveness and latency under expected load (e.g., using Apache JMeter to verify API response times).
- Load Testing: Pushes the system beyond its expected capacity to identify performance bottlenecks and determine its upper scaling limits.
- Security Testing: Involves static (SAST) and dynamic (DAST) application security testing, as well as penetration testing, to identify vulnerabilities like SQL injection, cross-site scripting (XSS), and insecure direct object references.
The modern goal is to integrate QA into the CI/CD pipeline, automating as much of the testing process as possible. A deep technical understanding of how to automate software testing is crucial for shortening feedback loops and achieving high deployment velocity without sacrificing quality.
Phase 5: Deployment and Maintenance
With the code built and rigorously tested, this phase focuses on releasing the software to users and ensuring its continued operation and evolution. This is not simply a matter of transferring files to a server; it involves a controlled release process and a strategic plan for ongoing maintenance. Modern DevOps practices leverage CI/CD (Continuous Integration/Continuous Delivery) pipelines, using tools like Jenkins or GitLab CI, to automate the build, test, and deployment process. This automation minimizes human error, increases release velocity, and improves the reliability of deployments.
Advanced Deployment Strategies
Deploying new code to a live production environment carries inherent risk. A single bug can cause downtime, data corruption, or reputational damage. To mitigate this "blast radius," engineering teams employ advanced deployment strategies:
- Blue-Green Deployments: This strategy involves maintaining two identical production environments: "Blue" (live) and "Green" (idle). The new version is deployed to the Green environment. After verification, a load balancer or router redirects all traffic from Blue to Green. This enables near-instantaneous rollback by simply redirecting traffic back to the Blue environment if issues are detected.
- Canary Releases: With this technique, the new version is incrementally rolled out to a small subset of users (the "canaries"). The system's health is closely monitored for this cohort. If performance metrics and error rates remain stable, the release is gradually rolled out to the entire user base. This strategy limits the impact of a faulty release to a small, controlled group.
These continuous delivery practices are becoming standard. In 2022, approximately 50% of Agile teams reported adopting continuous deployment. This trend reflects the industry's shift towards smaller, more frequent, and lower-risk releases. You can see the Agile development trends and CI adoption stats for yourself on Statista.
Proactive Post-Launch Maintenance
Deployment is the beginning of the software's operational life, not the end of the project. Effective maintenance is a proactive, ongoing engineering effort to ensure the system remains secure, performant, and aligned with evolving business needs.
Maintenance is not just reactive bug fixing. It is a continuous cycle of monitoring, optimization, and adaptation that preserves and enhances the software's value over its entire operational lifespan.
Maintenance activities are typically categorized into three types:
- Corrective Maintenance: Reacting to defects discovered in production. This involves diagnosing, prioritizing (based on severity and impact), and patching bugs reported by users or detected by monitoring and alerting systems.
- Adaptive Maintenance: Modifying the software to remain compatible with its changing operational environment. This includes updates for new operating system versions, changes in third-party API dependencies, or evolving security protocols.
- Perfective Maintenance: Improving the software's functionality and performance. This involves implementing new features based on user feedback, optimizing database queries, refactoring code to reduce technical debt, and enhancing scalability.
Frequently Asked Questions
Navigating the technical nuances of the software development process often raises specific questions. A clear understanding of these concepts is essential for any high-performing engineering team.
What Is the Most Critical Phase
From an engineering perspective, the Requirement Analysis and Planning phase is the most critical. Errors, ambiguities, or omissions introduced at this stage have a compounding effect, becoming exponentially more difficult and costly to remediate in later phases. A meticulously detailed and unambiguous Software Requirement Specification (SRS) serves as the foundational contract for the project, ensuring that all subsequent engineering efforts—design, implementation, and testing—are aligned with the intended business outcomes, thereby preventing expensive rework.
How Agile Methodology Impacts These Phases
Agile does not eliminate the core phases but reframes their execution. It compresses analysis, design, implementation, and testing into short, iterative cycles known as "sprints" (typically 1-4 weeks). Within a single sprint, a cross-functional team delivers a small, vertical slice of a potentially shippable product increment.
The core engineering disciplines remain, but their application shifts from a linear, sequential model (Waterfall) to a cyclical, incremental one. Agile's key technical advantage lies in its tight feedback loops, enabling continuous adaptation to changing requirements and technical discoveries.
Differentiating the SDLC from the Process
While often used interchangeably in casual conversation, these terms have distinct technical meanings:
- SDLC (Software Development Life Cycle): This is the high-level, conceptual framework that outlines the fundamental stages of software creation. Models like Waterfall, Agile, Spiral, and V-Model are all types of SDLCs.
- Software Development Process: This is the specific, tactical implementation of an SDLC model within an organization. It encompasses the chosen tools (e.g., Git, Jenkins, Jira), workflows (e.g., GitFlow, code review policies), engineering practices (e.g., TDD, CI/CD), and team structure (e.g., Scrum teams, feature crews).
In essence, the SDLC is the "what" (the abstract model), while the process is the "how" (the concrete implementation of that model). This distinction explains how two organizations can both claim to be "Agile" yet have vastly different day-to-day engineering practices. If you're curious about related topics, you can explore more FAQs for deeper insights.
Navigating the complexities of the software development life cycle requires deep expertise. OpsMoon connects you with top-tier DevOps engineers to accelerate your releases, improve reliability, and scale your infrastructure. Start with a free work planning session to build your strategic roadmap. Get started with OpsMoon today.