A Technical Guide to Cloud Native Application Development
 By opsmoon
By opsmoonA practical guide to cloud native application development. Learn to build scalable, resilient applications using microservices, containers, and Kubernetes.
When you hear the term cloud native, it’s easy to think it's just about running your apps in the cloud. But that's only part of the story. It’s a complete shift in how you design, build, and deploy software to take full advantage of the cloud's elastic, distributed, and automated nature. It's about building applications that are born for the cloud environment.
This approach isn't just a technical detail—it's what allows engineering teams to achieve high-velocity CI/CD, improve system resilience, and ship better software faster and more reliably than ever before.
More Than a Buzzword, It's a Strategic Shift
Moving to cloud native is less about picking a new tool and more about adopting a whole new engineering mindset. Let's break it down with a technical analogy.
Think of a traditional, monolithic application as a single, tightly-coupled binary deployed on a fleet of virtual machines. Its architecture is rigid. To update a single feature, you must re-compile, re-test, and re-deploy the entire application. A fault in one module can cascade, bringing the entire system down. Scaling is coarse-grained—you scale the entire monolith, even if only one small component is under load.
Now, imagine a cloud native application. It's not one monolithic binary but a distributed system composed of small, specialized, independent services. Each service is a microservice with a well-defined API boundary. If one service needs a security patch or a performance upgrade, it can be deployed independently without affecting the others. This modular, decoupled architecture makes the entire system more resilient, highly scalable, and dramatically faster to iterate on.
To truly understand what makes a system "cloud native," it's helpful to look at the foundational technologies and methodologies that make it all work. These aren't just trendy add-ons; they are the core pillars that support the entire structure.
Core Pillars of Cloud Native Development
| Pillar | Technical Function | Primary Business Benefit |
|---|---|---|
| Microservices | Decomposing large applications into small, independently deployable services that communicate via lightweight protocols like gRPC or HTTP/REST APIs. | Faster innovation, as teams can update individual services without redeploying the entire app. |
| Containerization | Packaging application code and its runtime dependencies into a portable, immutable artifact, most often with Docker. | Consistent deployments across any environment (dev, staging, prod), eliminating the classic "it works on my machine" problem. |
| DevOps & CI/CD | Automating the software delivery pipeline for continuous integration and continuous delivery (CI/CD), managed as code (e.g., Jenkinsfile, GitLab CI YAML). | Increased release velocity and improved stability, as code changes are automatically built, tested, and deployed. |
Each of these pillars builds on the others, creating a powerful, interconnected system for modern software engineering.
This diagram shows how concepts like containerization and microservices are the bedrock of cloud native development, with orchestration managing all the moving parts.
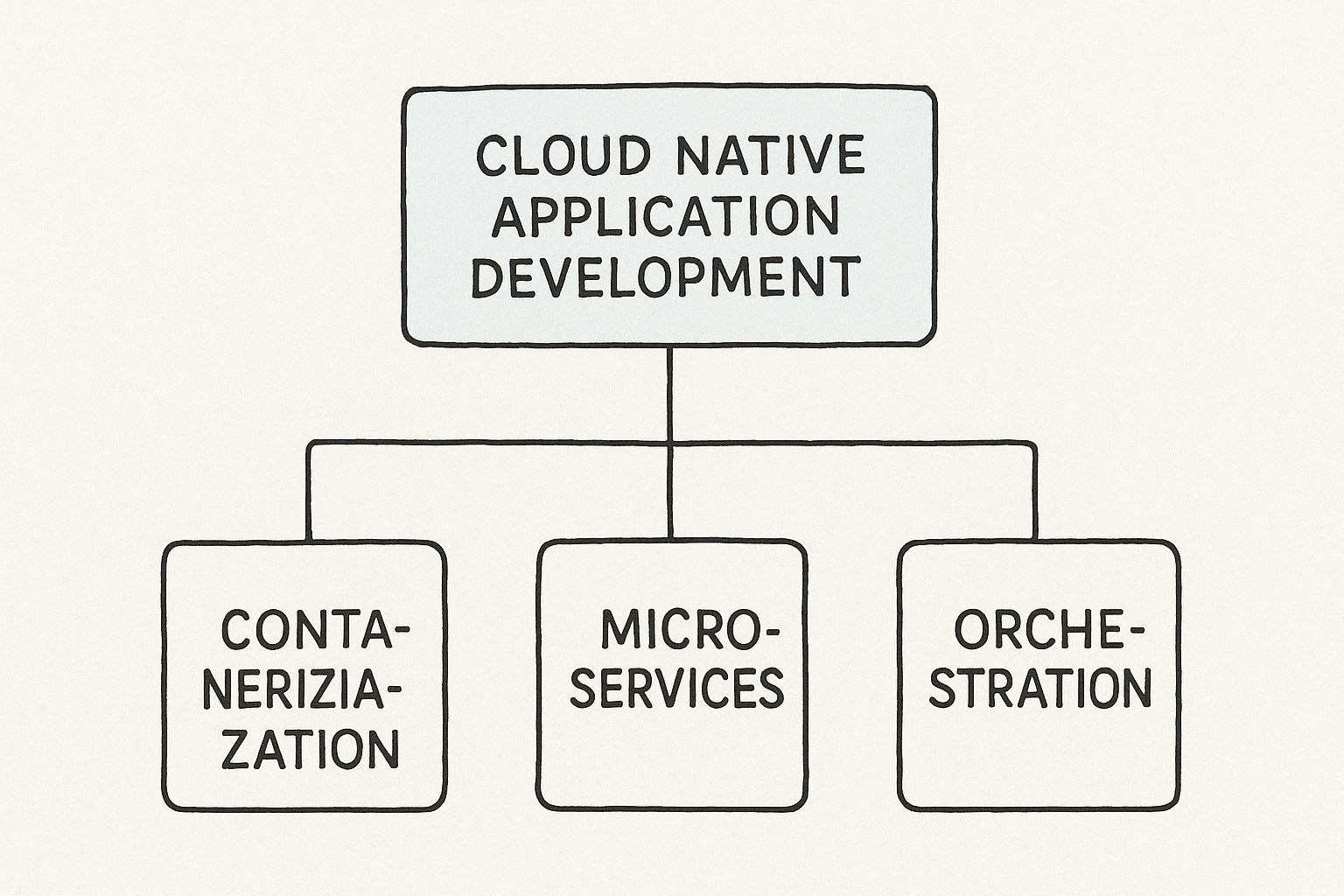
As you can see, orchestration is the critical layer that coordinates all these independent services, allowing them to work together seamlessly at scale. This combination of technology and process is why the market is exploding.
The global cloud native applications market was valued at USD 7.06 billion in 2023 and is projected to hit USD 30.24 billion by 2030. That’s not just hype; it’s a reflection of a massive industry-wide shift toward more agile and responsive systems.
The cultural element here, especially DevOps, is what ties everything together. It tears down the old walls between development and operations teams. If you want to dig deeper, our guide on what the DevOps methodology truly entails explains how this collaboration is the engine for speed.
Ultimately, this collaborative approach is what allows teams to build, test, and release software faster and more frequently, which is the entire point of going cloud native.
Building Your Foundation with Microservices

At the heart of any solid cloud-native application lies the microservices architecture. This isn't just a fancy way of saying "break up a big application into smaller ones." It's a fundamental architectural pattern for building complex, distributed systems.
Imagine an e-commerce platform built as a monolith. The user authentication, product catalog, inventory management, and payment processing logic are all compiled into a single deployable unit. Now, picture that same platform built with microservices. You'd have discrete, independently deployable services: auth-service, product-service, inventory-service, and payment-service.
Each service is a standalone application. It has its own database schema and can be developed, tested, and deployed in isolation. This means the inventory team can deploy a critical database migration without coordinating with—or blocking—the payments team. This architectural decoupling is a game-changer for velocity and system resilience. If one service experiences a failure, it doesn't cascade and bring the entire platform down with it.
Core Principles for Designing Microservices
To prevent your microservices from degrading into a "distributed monolith," you must adhere to several key design principles. These are the guardrails that ensure your architecture remains clean, scalable, and maintainable.
- Single Responsibility Principle: This is a core tenet of software design, applied at the service level. Every microservice should have one, and only one, reason to change. Your
auth-serviceshould only handle user identity and access control. It should have no knowledge of shopping carts; that's the domain of another service. This principle ensures services are small, focused, and easy to understand. - Decentralized Data Management: Each service is the sole owner and authority for its data. The
product-servicemanages the product database, and no other service is allowed to query its tables directly. All data access must happen through its public API. This "database-per-service" pattern prevents hidden data coupling and allows each service to choose the best persistence technology for its needs (e.g., SQL for transactions, NoSQL for documents). - Design for Failure: In any distributed system, failures are inevitable. Networks partition, services crash, and latency spikes. Your application must be architected to handle these transient faults gracefully. This means implementing patterns like exponential backoff for retries, request timeouts, and circuit breakers to isolate failures and prevent them from cascading across the system.
Synchronous vs. Asynchronous Communication
So you've got all these independent services. How do they communicate? The communication pattern you choose has a massive impact on your system's performance, coupling, and reliability. The two main approaches are synchronous and asynchronous.
Synchronous communication is a blocking, request-response pattern. One service sends a request and blocks until it receives a response. This is typically implemented with REST APIs over HTTP or with gRPC. For instance, when a customer adds an item to their cart, the cart-service might make a synchronous gRPC call to the inventory-service to check stock levels.
It's straightforward but creates tight temporal coupling between services. If the inventory-service is slow or offline, the cart-service is stuck waiting, leading to increased latency and reduced availability for the end-user.
Asynchronous communication, on the other hand, is a non-blocking, event-based model. A service sends a message and immediately moves on, without waiting for a reply. It simply publishes an event to a message broker, and any interested services can subscribe to that event and process it on their own time.
This is where tools like Apache Kafka or RabbitMQ are essential. When an order is placed, the order-service publishes an OrderCreated event to a Kafka topic. The shipping-service, billing-service, and notification-service can all subscribe to this topic, acting on the event independently and asynchronously. This decouples your services, making the entire system far more resilient and scalable.
Want to go deeper on this? We break down these strategies and more in our guide to microservices architecture design patterns.
The Role of an API Gateway
When you have tens or even hundreds of services running, you can't just expose them all directly to external clients (like your web or mobile app). That would be a security and management nightmare. You need a single, controlled entry point—and that's the job of an API Gateway.
Think of it as the reverse proxy for your entire microservices ecosystem. The gateway receives all incoming client requests, handles cross-cutting concerns like authentication (e.g., validating JWTs), and then routes each request to the correct downstream service.
This approach dramatically simplifies your client-side code, as it only needs to know the address of the gateway. It also provides a centralized point for implementing security policies, rate limiting, and collecting metrics, keeping that logic out of your individual business-focused microservices. Building on concepts like these is how you can create powerful, scalable applications, including interesting Micro SaaS ideas. Getting these architectural pieces right is the key to winning with modern software.
Using Containers and Kubernetes to Orchestrate Apps
Once you've decomposed your application into a collection of microservices, you face the next challenge: how do you package, deploy, and run them consistently across different environments? This is where containerization, specifically with Docker, provides the definitive solution. It’s the answer to that chronic developer headache, "but it works on my machine!"
A container is a lightweight, standalone, executable package that includes everything needed to run a piece of software: the compiled code, a runtime, system tools, and libraries. It achieves OS-level virtualization by leveraging Linux kernel features like cgroups and namespaces. Just as a physical shipping container allows goods to be moved by truck, train, or ship without repackaging, a software container ensures your application runs identically everywhere.
This immutability and portability are foundational to cloud native application development. By bundling an application and its dependencies into a single artifact, containers guarantee that what you test on a developer's laptop is exactly what gets deployed to a production server. If you're looking to put these skills to work, you might want to check out some remote Docker jobs.
From One Container to an Orchestra
Running a single container is simple: docker run my-app. But what happens when you’re managing hundreds of microservice instances? They all need service discovery, load balancing, health checks, and a way to recover from host failures. Managing this distributed system manually is operationally untenable.
You need a container orchestrator. And in the cloud native ecosystem, the de facto standard is Kubernetes.
Kubernetes automates the deployment, scaling, and management of containerized applications. It’s the distributed operating system for your cluster, making sure every microservice runs in its desired state. It handles the complex operational tasks—like load balancing traffic, managing persistent storage, and executing automated rollouts and rollbacks—so your teams can focus on writing code.
Understanding Core Kubernetes Objects
To work with Kubernetes, you define your application's desired state using declarative configuration files, typically in YAML format. These files describe objects, which are the primitive building blocks of a Kubernetes cluster.
Here are the essential objects you’ll work with constantly:
- Pods: The smallest deployable unit of computing in Kubernetes. A Pod encapsulates one or more containers, storage resources, and a unique network IP. While a Pod can run multiple containers, the single-container-per-Pod model is most common.
- Services: Pods are ephemeral and have dynamic IP addresses. A Kubernetes Service provides a stable network endpoint (a single DNS name and IP address) for a set of Pods. This allows your microservices to discover and communicate with each other reliably using a fixed address.
- Deployments: A Deployment is a higher-level object that manages Pods. It lets you declaratively specify the number of replicas (instances) of a Pod you want running, and it automates the process of updating them via rolling updates. It ensures your application remains available during deployments.
- Ingress: Services are designed for internal, cluster-to-cluster communication. To expose an application to the outside world, you use an Ingress. It acts as an application-layer (L7) load balancer, routing external HTTP and HTTPS requests to the correct services based on hostnames or URL paths.
Putting It All Together: A Practical Example
Let's walk through a typical deployment workflow for a user-service microservice.
-
Define the Deployment: First, you'd create a
deployment.yamlfile. In it, you'd specify the container image (my-registry/user-service:v1.2.0), the number of replicas (replicas: 3), and resource requests/limits (CPU and memory). Applying this manifest withkubectl apply -f deployment.yamltells the Kubernetes control plane to schedule three Pods, each running an instance of your service, across the nodes in the cluster. -
Expose with a Service: Next, you'd create a
service.yamlmanifest that uses a label selector to target the Pods created by your Deployment. Kubernetes then assigns a stable internal IP and DNS name (e.g.,user-service.default.svc.cluster.local) to this Service. Now, any other microservice inside the cluster can communicate with theuser-serviceusing this DNS name, and Kubernetes will load-balance the requests across the three running Pods. -
Allow External Access: Finally, to allow external traffic, you create an
ingress.yaml. You'd define a rule that maps the public hostapi.yourcompany.comand path/usersto theuser-serviceService on its designated port. An Ingress controller (like NGINX or Traefik) running in the cluster will then configure itself to route all incoming traffic for that URL to your Service, which in turn distributes it to your Pods.
This declarative, desired-state model is what makes Kubernetes so powerful. You simply tell it what you want, and Kubernetes handles the complex orchestration to make it happen and maintain that state, even in the face of node failures or other disruptions. It's the operational engine that makes cloud native truly scale.
Automating Delivery with DevOps and CI/CD Pipelines
Having a brilliant microservices architecture and a robust Kubernetes cluster is only half the battle. To realize the full potential of cloud native development, you must automate the process of getting code from a developer's commit into that cluster.
This is where a DevOps culture and CI/CD pipelines become the critical enablers. They are the automated assembly line that turns your well-designed architecture into a high-velocity delivery machine.
More Than Just Tools: It's a Cultural Shift
Going cloud native is as much about how your teams work as it is about the technology they use. It means tearing down the organizational silos between development (Dev) and operations (Ops) teams.
The goal is to create a single, unified workflow where teams take end-to-end ownership of their services, from code to production. This "you build it, you run it" mindset is what truly powers the whole cloud native ecosystem.
This isn’t just some niche trend; it’s now the standard for high-performing tech organizations. Recent industry analysis shows nearly 75% of companies have adopted DevOps practices. That's a huge leap from just 47% five years ago, a shift driven by the rise of hybrid and multi-cloud strategies. You can dig into the specifics in the latest cloud native market analysis.
Anatomy of a Cloud Native CI/CD Pipeline
So, what does this automation look like in practice? It's all orchestrated by a CI/CD (Continuous Integration/Continuous Delivery) pipeline—an automated workflow defined as code.
For a containerized application deploying to Kubernetes, a typical pipeline consists of these stages:
-
Code Commit: The pipeline is triggered automatically when a developer pushes code changes to a specific branch in a Git repository like GitHub or GitLab.
-
Automated Build: A CI server—like Jenkins, GitLab CI, or GitHub Actions—fetches the latest code. It compiles the application, runs static code analysis, and builds a new Docker container image.
-
Testing and Scanning: This new image is subjected to a suite of automated tests: unit tests, integration tests, and contract tests. Concurrently, the image is scanned for known security vulnerabilities (CVEs) using tools like Trivy or Clair. A failure at this stage stops the pipeline immediately.
-
Push to Registry: Once the image passes all quality and security gates, it is tagged with a unique identifier (e.g., the Git commit SHA) and pushed to a container registry, such as Docker Hub, Amazon ECR, or Google Artifact Registry. This registry serves as the single source of truth for your deployable artifacts.
-
Automated Deployment: In the final stage, the pipeline tool updates the Kubernetes deployment manifest, changing the image tag to the newly built version. It then applies this change to the cluster, often using a GitOps tool like Argo CD or Flux. Kubernetes then executes a zero-downtime rolling update to bring the new version live.
The entire process is automated, version-controlled, and auditable.
The shift from a manual, step-by-step release process to an automated, pipeline-driven one is fundamental to cloud native. Here's a quick comparison of how the development lifecycle changes:
Monolithic vs Cloud Native Development Lifecycle
| Lifecycle Stage | Monolithic Approach | Cloud Native Approach |
|---|---|---|
| Planning | Long-term, feature-heavy release cycles planned months in advance. | Short, iterative sprints focused on small, incremental features. |
| Development | All developers work on a single, large codebase, leading to merge conflicts. | Small, autonomous teams work on independent microservices, reducing coordination overhead. |
| Build & Test | A slow, complex build process for the entire application. Testing is a separate, lengthy QA phase. | Fast, parallelized builds for individual services. Testing is continuous and integrated into the pipeline. |
| Deployment | Infrequent, high-risk "release day" events requiring significant coordination and downtime. | Frequent, low-risk, automated deployments (e.g., Canary or Blue/Green) with zero downtime. |
| Operations | Operations team manages a large, static application server with manual scaling. | Ops team manages a dynamic platform (like Kubernetes) that provides self-healing and auto-scaling. |
| Monitoring | Monitoring focuses on server health (CPU, memory) and overall application performance. | Observability focuses on distributed tracing, metrics, and logs across many services to debug complex issues. |
As you can see, the cloud native approach builds speed and reliability into every stage, from the first line of code to production monitoring.
The Real-World Impact of Automation
This level of automation isn't just about developer convenience; it delivers measurable business value.
By eliminating manual hand-offs and error-prone human intervention, teams can deploy changes far more frequently and with much higher confidence. A solid pipeline is the bedrock of operational excellence. If you're looking to level up your own setup, we’ve put together a guide on CI/CD pipeline best practices to help you sidestep common issues.
The ultimate goal of a CI/CD pipeline is to make deployments a non-event. It transforms a risky, all-hands-on-deck process into a routine, automated workflow that happens multiple times a day.
This directly reduces your lead time for changes. Instead of batching hundreds of changes into a quarterly release, you can ship small updates the moment they’re ready and validated. This not only delivers value to customers faster but also dramatically lowers the risk of each deployment, making your entire system more stable and predictable.
Advanced Cloud Native Implementation Strategies
Once you've mastered the fundamentals of microservices, containers, and CI/CD, it's time to implement the patterns that define a production-grade system. A mature cloud native application development strategy is about building systems that are observable, secure, and resilient by design.
This is where you move beyond simply deploying features and start engineering for operational excellence. These strategies are what enable you to diagnose issues, withstand attacks, and automatically recover from failures at scale.
And the market reflects this shift. The entire cloud native development market is on a rocket ship, expected to hit USD 1.08 trillion in 2025—up from USD 881.98 billion in 2024. Projections show it nearly tripling to USD 2.56 trillion by 2029. This boom is directly tied to teams going all-in on agile, microservices, and DevOps. You can get the full scoop by checking out the cloud native development market report.
Implementing the Three Pillars of Observability
In a complex distributed system, traditional monitoring (checking CPU and memory) is insufficient. You need Observability—the ability to ask arbitrary questions about your system's behavior without having to ship new code. It is built on three key data types.
- Metrics: These are time-series numerical data, such as request latency, error rates, or queue depth. A tool like Prometheus scrapes these metrics from your services, allowing you to build dashboards (e.g., in Grafana) and configure alerts to detect known failure modes in real time.
- Logs: These are immutable, timestamped records of discrete events. Using a log aggregator like Fluentd, you can collect logs from all your services, parse them, and ship them to a centralized platform like Elasticsearch. This allows you to perform complex queries to debug specific issues after they occur.
- Traces: A trace represents the end-to-end journey of a single request as it propagates through your microservices. By instrumenting your code with a distributed tracing system like Jaeger or OpenTelemetry, you can visualize the entire request path, identifying performance bottlenecks and sources of error with precision.
Combining metrics, logs, and traces provides a comprehensive view of system health. You go from basic monitoring of known-unknowns to being able to explore and debug the unknown-unknowns that inevitably arise in complex systems.
Critical Security Patterns for Containerized Environments
The distributed and dynamic nature of cloud native architectures requires a shift from perimeter-based security to a zero-trust model. You must secure your application from the inside out.
First, eliminate hardcoded secrets like API keys and database credentials from your code and configuration files. Instead, use a dedicated secrets management tool like HashiCorp Vault. It provides a central, encrypted store for secrets, with features like dynamic secret generation, leasing, and revocation.
Next, implement least-privilege networking between your services. Kubernetes Network Policies act as a distributed firewall for your pods. You can define explicit ingress and egress rules, specifying exactly which services are allowed to communicate with each other over which ports. For example, you can create a policy that allows the order-service to connect to the payment-service but denies all other inbound traffic.
Finally, enforce security best practices at the pod level using Pod Security Policies (or their successor, Pod Security Admission). These policies can enforce constraints like preventing containers from running as the root user, disallowing host filesystem mounts, and restricting the use of privileged containers.
Building Self-Healing Applications with Resilience Patterns
In a cloud native system, failures are not exceptional events; they are expected. The goal is to build applications that can tolerate failures and recover automatically, without human intervention. This is achieved by implementing resilience patterns directly in your services.
Here are two essential patterns for building self-healing applications:
- Circuit Breakers: A service repeatedly calling a failing downstream dependency can cause cascading failures. A circuit breaker, often implemented with a library like Resilience4j (Java) or Polly (.NET), monitors for failures. After a configured threshold of failures, the circuit "trips" and subsequent calls fail fast without even making a network request. This isolates the failing service and gives it time to recover.
- Rate Limiting: This pattern protects your services from being overwhelmed by excessive requests, whether from a misbehaving client or a denial-of-service attack. By implementing a rate limiter (e.g., using a token bucket algorithm), you can control the number of requests a service will accept in a given time window, ensuring fair resource allocation and preventing overload.
When you weave these strategies into your development process, you're not just building apps that are scalable and agile. You're building systems that are fundamentally robust, secure, and ready for the demands of production.
Frequently Asked Questions About Cloud Native
As your team starts digging into cloud native application development, you're bound to run into some common questions and technical roadblocks. It happens to everyone. This section tackles some of the most frequent challenges head-on, giving you direct, practical answers to help you move forward with confidence.
Cloud Native vs. Cloud Ready
One of the first points of confusion is the distinction between "cloud ready" and "cloud native." The difference is fundamental and impacts everything from cost to agility.
Cloud-ready applications are typically monolithic systems that have been re-platformed to run on cloud infrastructure. This is often called a "lift and shift" migration. For example, taking a legacy Java application and running it on an EC2 virtual machine. The application works, but it's not designed to leverage core cloud capabilities like auto-scaling, self-healing, or managed services.
Cloud-native applications are architected specifically to exploit the cloud's capabilities. They are composed of microservices, packaged as containers, and managed by an orchestrator like Kubernetes. This design allows them to scale horizontally on demand, survive infrastructure failures gracefully, and be deployed frequently and independently.
Managing Data Consistency Across Microservices
Maintaining data consistency is a significant challenge in a distributed microservices architecture. Since each microservice owns its own database, you cannot use traditional ACID transactions that span multiple services. Such distributed transactions create tight coupling and are a performance bottleneck.
The cloud native approach is to embrace eventual consistency using an event-driven architecture. When one microservice completes a business operation (e.g., a customer places an order), it publishes an event. Other services subscribe to this event and update their own local data stores accordingly. There's a brief period where the system is in an inconsistent state, but it eventually converges.
A popular implementation for this is the Saga pattern. A Saga is a sequence of local transactions. Each transaction updates the database of one service and publishes an event that triggers the next transaction in the sequence. If a transaction fails, the Saga executes a series of compensating transactions to roll back the preceding changes, ensuring the system returns to a consistent state.
Is Kubernetes Always Necessary?
Kubernetes is the dominant container orchestrator, but its power comes with significant operational complexity. For many use cases, it can be overkill.
For simpler applications or teams without dedicated platform engineers, other options can provide a faster path to production:
- Serverless Platforms: Services like AWS Lambda or Azure Functions abstract away all infrastructure management. You provide the code, and the platform handles scaling, availability, and execution. This is ideal for event-driven or stateless workloads.
- Managed Container Services: Platforms like AWS Fargate or Google Cloud Run provide a middle ground. They allow you to run containers without managing the underlying Kubernetes nodes or control plane. You get the benefits of containerization without the full operational burden of Kubernetes.
The choice depends on your requirements for scale, control, and operational capacity. Kubernetes excels at managing complex, large-scale distributed systems, but don't overlook simpler, higher-level abstractions that can deliver value more quickly for smaller projects.
Biggest Cloud Native Security Challenges
Security in a cloud native environment is a multi-layered problem. The attack surface expands significantly with distributed services, ephemeral containers, and complex network configurations.
Here are the primary technical challenges you must address:
- Container Security: Your CI/CD pipeline must include automated image scanning for known vulnerabilities (CVEs) in both your application code and its third-party dependencies. You should also enforce policies to build from trusted base images.
- Runtime Security: Once deployed, you need to monitor container behavior for anomalies. This includes enforcing least-privilege (e.g., read-only root filesystems), using network policies to segment traffic, and employing runtime security tools to detect suspicious activity like unexpected process execution or network connections.
- Secrets Management: Hardcoding secrets is a critical vulnerability. Integrating a dedicated secrets management solution like HashiCorp Vault is essential for securely storing and dynamically injecting credentials into your running containers.
- Misconfigurations: The declarative nature of cloud and Kubernetes configurations means a simple typo in a YAML file can expose a major security hole. Use infrastructure-as-code (IaC) scanners and Cloud Security Posture Management (CSPM) tools to automatically audit your configurations against security best practices.
Despite these hurdles, companies all over the world are making this model work. Businesses in finance, healthcare, and retail are using cloud native software to slash infrastructure costs and innovate faster, with major growth happening across North America, Europe, and Asia-Pacific. You can discover more insights about the cloud native software market and see the trends for yourself.
Making the jump to cloud native application development is a serious undertaking that requires real expertise. At OpsMoon, we connect you with the top 0.7% of DevOps engineers who can build, secure, and scale your infrastructure the right way. Let's map out your path to success with a free work planning session. Get started with OpsMoon.