What Is Blue Green Deployment Explained
 By opsmoon
By opsmoonLearn what is blue green deployment and how this powerful release strategy eliminates downtime. Our guide covers architecture, tools, and implementation steps.
At its core, blue-green deployment is a release strategy designed for zero-downtime deployments and instant rollbacks. It relies on maintaining two identical production environments—conventionally named "blue" and "green"—that are completely isolated from each other.
While the "blue" environment handles live production traffic, the new version of the application is deployed to the "green" environment. This green environment is then subjected to a full suite of integration, performance, and smoke tests. Once validated, a simple configuration change at the router or load balancer level instantly redirects all incoming traffic from the blue to the green environment. For end-users, the transition is atomic and seamless.
Demystifying Blue Green Deployment
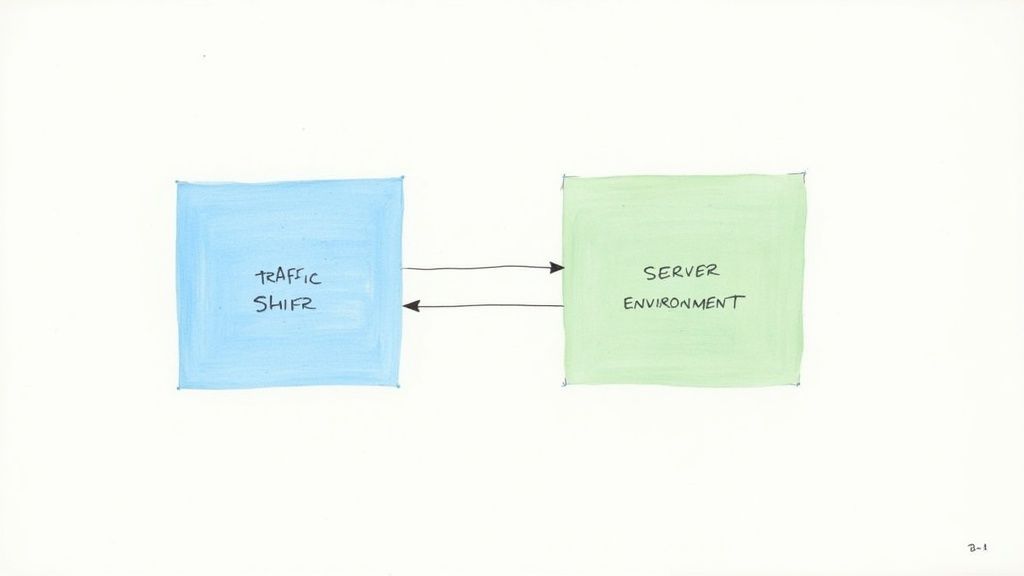
Let's use a technical analogy. Imagine two identical server clusters, Blue and Green, behind an Application Load Balancer (ALB). The ALB's listener rule is currently configured to forward 100% of traffic to the Blue target group.
While Blue serves live traffic, a CI/CD pipeline deploys the new application version to the Green cluster. Automated tests run against Green's private endpoint, verifying its functionality and performance under simulated load. When the new version is confirmed stable, a single API call is made to the ALB to update the listener rule, atomically switching the forward action from the Blue target group to the Green one. The transition is instantaneous, with no in-flight requests dropped.
The Core Mechanics of the Switch
This strategy replaces high-risk, in-place upgrades. Instead of modifying the live infrastructure, which often leads to downtime and complex rollback procedures, you deploy to a clean, isolated environment.
The blue-green model provides a critical safety net. You have two distinct, identical environments: one (blue) running the stable, current version and the other (green) containing the new release candidate. You can find more great insights in LaunchDarkly's introductory guide.
Once the green environment passes all automated and manual validation checks, the traffic switch occurs at the routing layer—typically a load balancer, API gateway, or service mesh. If post-release monitoring detects anomalies (e.g., a spike in HTTP 5xx errors or increased latency), recovery is equally fast. The routing rule is simply reverted, redirecting all traffic back to the original blue environment, which remains on standby as an immediate rollback target.
Key Takeaway: The efficacy of blue-green deployment hinges on identical, isolated production environments. This allows the new version to be fully vetted under production-like conditions before user traffic is introduced, drastically mitigating the risk of a failed release.
Core Concepts of Blue Green Deployment at a Glance
For this strategy to function correctly, several infrastructure components must be orchestrated. This table breaks down the essential components and their technical roles.
| Component | Role and Function |
|---|---|
| Blue Environment | The current live production environment serving 100% of user traffic. It represents the known stable state of the application. |
| Green Environment | An ephemeral, identical clone of the blue environment where the new application version is deployed and validated. It is idle from a user perspective but fully operational. |
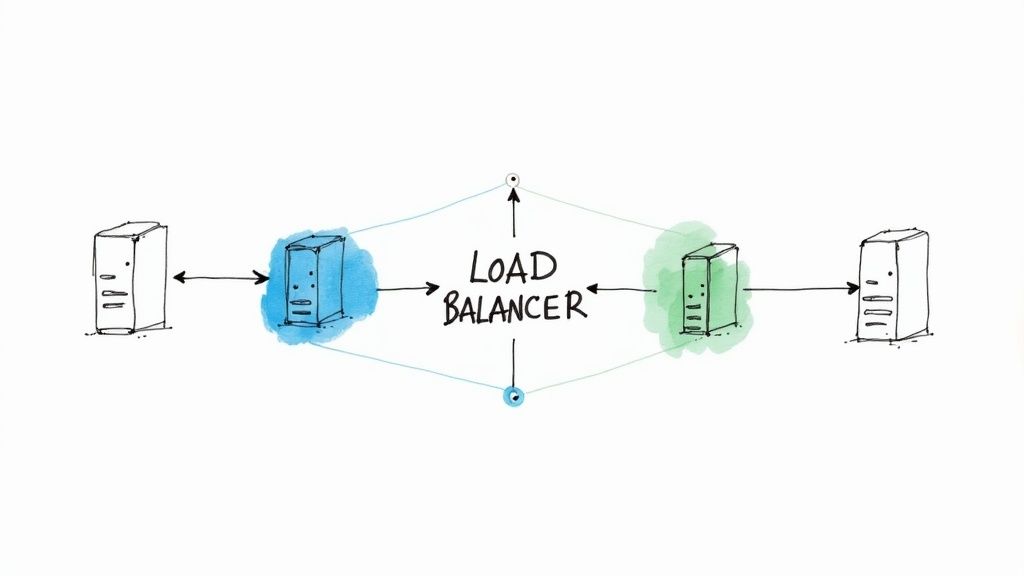
| Router/Load Balancer | The traffic control plane. This component—an ALB, Nginx, API Gateway, or Service Mesh—is responsible for directing all incoming user requests to either the blue or the green environment. The switch is executed here. |
Grasping how these pieces interact is fundamental to understanding the technical side of a blue-green deployment. Let's dig a little deeper into each one.
The Moving Parts Explained
- The Blue Environment: Your current, battle-tested production environment. It’s what all your users are interacting with right now. It is the definition of "stable."
- The Green Environment: This is a production-grade staging environment, a perfect mirror of production. Here, the new version of your application is deployed and subjected to rigorous testing, completely isolated from live traffic but ready to take over instantly.
- The Router/Load Balancer: This is the linchpin of the operation. It's the reverse proxy or traffic-directing component that sits in front of your environments. The ability to atomically update its routing rules is what enables the instantaneous, zero-downtime switch.
Designing a Resilient Deployment Architecture
To successfully implement blue-green deployment, your architecture must be designed for it. The strategy relies on an intelligent control plane that can direct network traffic with precision. Your load balancers, DNS configurations, and API gateways are the nervous system of this process.
These components act as the single point of control for shifting traffic from the blue to the green environment. The choice of tool and its configuration directly impacts the speed, reliability, and end-user experience of the deployment.
Choosing Your Traffic Routing Mechanism
The method for directing traffic is a critical architectural decision. A simple DNS CNAME or A record update might seem straightforward, but it is often a poor choice due to DNS caching. Clients and resolvers can cache old DNS records for their TTL (Time To Live), leading to a slow, unpredictable transition where some users hit the old environment while others hit the new one. This violates the principle of an atomic switch.
For a reliable and immediate cutover, modern architectures leverage more sophisticated tools:
- Load Balancers: An Application Load Balancer (ALB) or a similar Layer 7 load balancer is ideal. You configure it with two target groups—one for blue, one for green. The switch is a single API call that updates the listener rule, atomically redirecting 100% of the traffic from the blue target group to the green one.
- API Gateways: In a microservices architecture, an API gateway can manage this routing. A configuration update to the backend service definition is all that's required to seamlessly redirect API calls to the new version of a service.
- Service Mesh (for Kubernetes): In containerized environments, a service mesh like Istio or Linkerd provides fine-grained traffic control. You can use their traffic-splitting capabilities to instantly shift 100% of traffic from the blue service to the green one with a declarative configuration update.
The Non-Negotiable Role of Infrastructure as Code
A core tenet of blue-green deployment is that the blue and green environments must be identical. Any drift—a different patch level, a missing environment variable, or a mismatched security group—introduces risk and can cause the new version to fail under production load, even if it passed all tests.
This is why Infrastructure as Code (IaC) is a foundational requirement, not a best practice.
With tools like Terraform or AWS CloudFormation, you define your entire environment—VPCs, subnets, instances, security groups, IAM roles—in version-controlled code. This guarantees that when a new green environment is provisioned, it is a bit-for-bit replica of the blue one, eliminating configuration drift.
By codifying your infrastructure, you create a repeatable, auditable, and automated process, turning a complex manual task into a reliable workflow. This is essential for achieving the speed and safety goals of blue-green deployments.
Tackling the Challenge of State Management
The most significant architectural challenge in blue-green deployments is managing state. For stateless applications, the switch is trivial. However, databases, user sessions, and distributed caches introduce complexity. You cannot simply have two independent databases, as this would result in data loss and inconsistency.
Several strategies can be employed to handle state:
- Shared Database: The most common approach. Both blue and green environments connect to the same production database. This requires strict discipline around schema changes. All database migrations must be backward-compatible, ensuring the old (blue) application continues to function correctly even after the new (green) version has updated the schema.
- Read-Only Mode: During the cutover, the application can be programmatically put into a read-only mode for a brief period. This prevents writes during the transition, minimizing the risk of data corruption, but introduces a short window of reduced functionality.
- Data Replication: For complex scenarios, you can configure database replication from the blue database to a new green database. Once the green environment is live, the replication direction can be reversed. This is a complex operation that requires robust tooling and careful planning to ensure data consistency.
Properly handling state is often the defining factor in the success of a blue-green strategy, requiring careful architectural planning to ensure data integrity and a seamless user experience.
Weighing the Technical Advantages and Trade-Offs
Adopting a blue-green deployment strategy offers significant operational advantages, but it requires an investment in infrastructure and architectural rigor. A clear-eyed analysis of the benefits versus the costs is essential.
The primary benefit is the near-elimination of deployment-related downtime. For services with strict Service Level Objectives (SLOs), this is paramount. An outage during a traditional deployment consumes your error budget and erodes user trust. With a blue-green approach, the cutover is atomic, making the concept of a "deployment window" obsolete.
The Superpower of Instant Rollbacks
The true operational superpower of blue-green deployment is the instant, zero-risk rollback. If post-release monitoring detects a surge in errors or a performance degradation, recovery is not a frantic, multi-step procedure. It is a single action: reverting the router configuration to direct traffic back to the blue environment.
This capability fundamentally changes the team's risk posture towards releases. The fear of deployment is replaced by confidence, knowing a robust safety net is always in place.
A rollback restores the exact same environment that was previously running. This includes the immutable configuration of the task definition, load balancer settings, and service discovery, ensuring a predictable and stable state.
The High Cost of Duplication
The main trade-off is resource overhead. For the duration of the deployment process, you are effectively running double the production infrastructure. This means twice the compute instances, container tasks, and potentially double the software licensing fees.
This cost can be a significant factor. However, modern cloud infrastructure provides mechanisms to mitigate this:
- Cloud Auto-Scaling: The green environment can be provisioned with a minimal instance count and scaled up only for performance testing and the cutover phase.
- Serverless and Containers: Using orchestration like Amazon ECS or Kubernetes allows for more dynamic resource allocation. You pay only for the compute required to run the green environment's containers for the duration of the deployment.
- On-Demand Pricing: Leveraging the on-demand pricing models of cloud providers avoids long-term commitments for the temporary green infrastructure.
The Complexity of Stateful Applications
While stateless services are a natural fit, managing state is the Achilles' heel of blue-green deployments. If your application relies on a database, ensuring data consistency and handling schema migrations during a switch requires careful architectural planning.
The primary challenge is the database. A common pattern is for both blue and green environments to share a single database, which imposes a critical constraint: all database schema changes must be backward-compatible. The old blue application code must continue to function correctly with the new schema deployed by the green environment.
This often requires breaking down a single, complex database change into multiple, smaller, incremental releases. This process is a key element of a mature release pipeline and is closely related to the principles found in our guide to continuous deployment vs continuous delivery. Essentially, you must decouple database migrations from your application deployments to execute this strategy safely.
Blue Green Deployment vs Canary Deployment vs Rolling Update
To put blue-green into context, it's helpful to compare it against other common deployment strategies. Each has its own strengths and is suited for different scenarios.
| Attribute | Blue Green Deployment | Canary Deployment | Rolling Update |
|---|---|---|---|
| Downtime | Near-zero downtime | Near-zero downtime | No downtime |
| Resource Cost | High (double the infra) | Moderate (small subset of new infra) | Low (minimal overhead) |
| Rollback Speed | Instant | Fast, but requires redeployment | Slow and complex |
| Risk Exposure | Low (isolated environment) | Low (limited user impact) | Moderate (gradual rollout) |
| Complexity | Moderate to high (state management) | High (traffic shaping, monitoring) | Low to moderate |
| Ideal Use Case | Critical applications needing fast, reliable rollbacks and zero-downtime releases. | Feature testing with real users, performance monitoring for new versions. | Simple, stateless applications where temporary inconsistencies are acceptable. |
Choosing the right strategy is not about finding the "best" one, but the one that aligns with your application's architecture, risk tolerance, and operational budget.
Putting Your First Blue-Green Deployment into Action
Moving from theory to practice, this section serves as a technical playbook for executing a safe and predictable blue-green deployment. The entire process is methodical and designed for control.
The non-negotiable prerequisite is environmental parity: your two environments must be identical. Any configuration drift introduces risk. This is why automation, particularly Infrastructure as Code (IaC), is essential.
Step 1: Spin Up a Squeaky-Clean Green Environment
First, you must provision the Green environment. This should be a fully automated process driven by version-controlled scripts to guarantee it is a perfect mirror of the live Blue environment.
Using tools like Terraform or AWS CloudFormation, your scripts should define every component of the infrastructure:
- Compute Resources: Identical instance types, container definitions (e.g., an Amazon ECS Task Definition or Kubernetes Deployment manifest), and resource limits.
- Networking Rules: Identical VPCs, subnets, security groups, and network ACLs to precisely mimic the production traffic flow and security posture.
- Configuration: All environment variables, secrets (retrieved from a secret manager), and application settings must match the Blue environment exactly.
This scripted approach eliminates "configuration drift," a common cause of deployment failures, resulting in a sterile, predictable environment for the new application code.
Step 2: Deploy and Kick the Tires on the New Version
With the Green environment provisioned, your CI/CD pipeline deploys the new application version to it. This new version should be a container image tagged with a unique identifier, such as the Git commit SHA.
Once deployed, Green is fully operational but isolated from production traffic. This provides a perfect sandbox for running a comprehensive test suite against a production-like stack:
- Integration Tests: Verify that all microservices and external dependencies (APIs, databases) are communicating correctly.
- Performance Tests: Use load testing tools to ensure the new version meets performance SLOs under realistic traffic patterns. A 1-second delay in page load can cause a 7% drop in conversions, making this a critical validation step.
- Security Scans: Execute dynamic application security testing (DAST) and vulnerability scans against the isolated new code.
Finally, conduct smoke testing by routing internal or synthetic traffic to the Green environment's endpoint for final manual verification.
Step 3: Flip the Switch
The traffic switch from Blue to Green must be an atomic operation. This is typically managed by a load balancer or an ingress controller in a Kubernetes environment.
Consider a Kubernetes Service manifest as a concrete example. Before the switch, the service's selector targets the Blue pods:
# A Kubernetes Service definition before the switch
apiVersion: v1
kind: Service
metadata:
name: my-application-service
spec:
selector:
app: my-app
version: blue # <-- Currently points to the blue deployment
ports:
- protocol: TCP
port: 80
targetPort: 8080
To execute the cutover, you update the selector in the manifest to point to the Green deployment's pods:
# The service definition is updated to point to green
apiVersion: v1
kind: Service
metadata:
name: my-application-service
spec:
selector:
app: my-app
version: green # <-- The selector is now pointing to green
ports:
- protocol: TCP
port: 80
targetPort: 8080
Applying this updated manifest via kubectl apply instantly redirects 100% of user traffic to the new version. The change is immediate and seamless, achieving the zero-downtime objective. Using a solid deployment checklist can prevent common errors during this critical step.
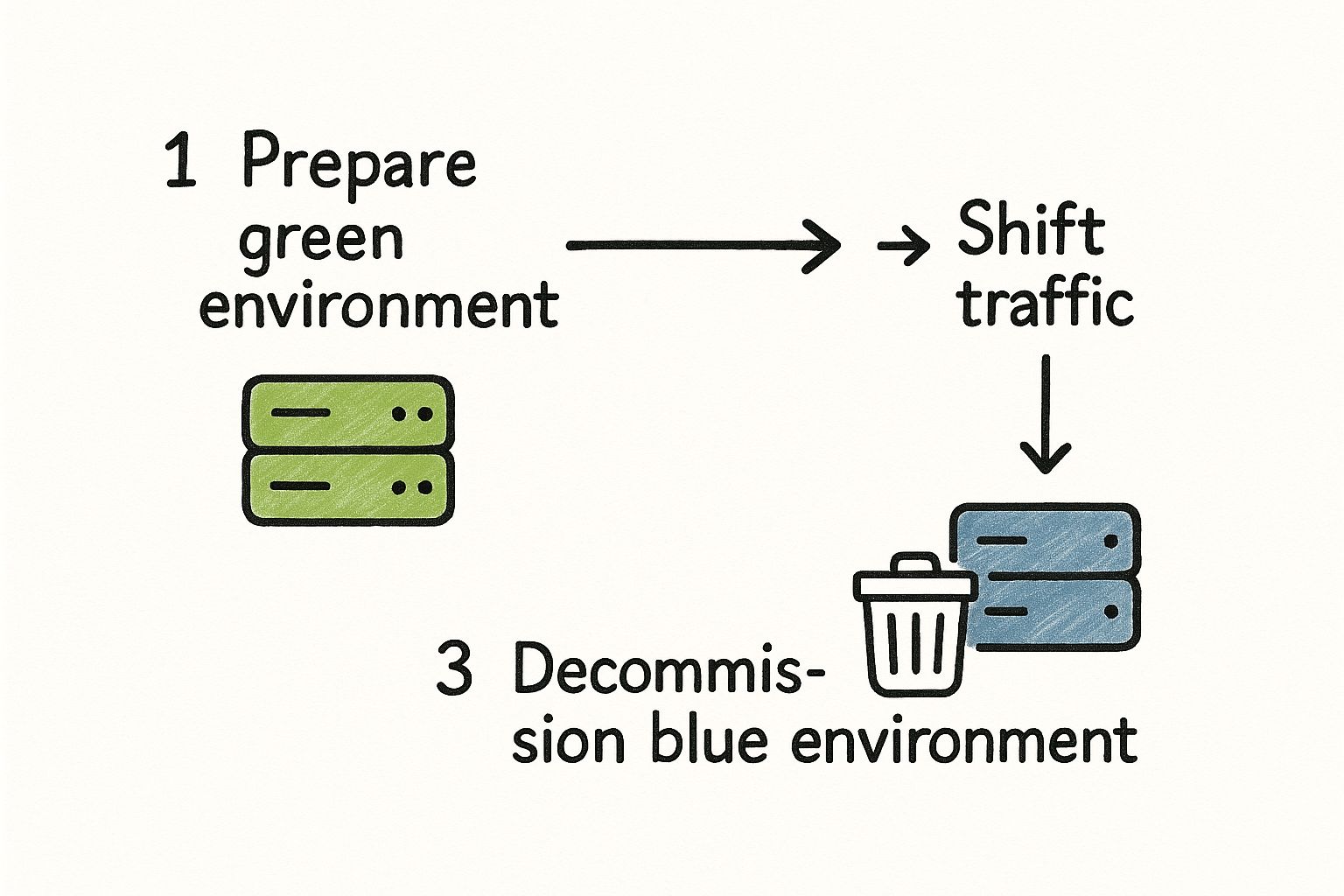
The workflow is straightforward: prepare the new environment in isolation, execute an atomic traffic switch, monitor, and then decommission the old environment.
Step 4: Watch Closely, Then Decommission
After the switch, the job is not complete. A critical monitoring phase begins. The old Blue environment should be kept on standby, ready for an immediate rollback.
Crucial Insight: Keeping the Blue environment running is your get-out-of-jail-free card. If observability tools (like Prometheus, Grafana, or Datadog) show a spike in the error rate or a breach of latency SLOs, you execute the same cutover in reverse, pointing traffic back to the known-good Blue environment.
After a predetermined period of stability—ranging from minutes to hours, depending on your risk tolerance—you gain sufficient confidence in the release. Only then is it safe to decommission the Blue environment, freeing up its resources. This final cleanup step should also be automated to ensure consistency and prevent orphaned infrastructure.
Building an Automated Blue-Green Pipeline

Manual blue-green deployments are prone to human error. The full benefits are realized through a robust, automated CI/CD pipeline that orchestrates the entire process.
This involves a toolchain where each component performs a specific function, managed by a central CI/CD platform.
Tools like GitHub Actions or GitLab CI act as the brain of the operation. They define and execute the workflow for every step: compiling code, building a container image, provisioning infrastructure, running tests, and triggering the final traffic switch. For deeper insights, review our guide on CI/CD pipeline best practices.
Ensuring Environmental Parity with IaC
The golden rule of blue-green is identical environments. Infrastructure as Code (IaC) is the mechanism to enforce this rule.
Tools like Terraform or Ansible serve as the single source of truth for your infrastructure. By defining every server, network rule, and configuration setting in code, you guarantee the Green environment is an exact clone of Blue. This eradicates "configuration drift," where subtle environmental differences cause production failures.
Key Takeaway: An automated pipeline transforms blue-green deployment from a complex manual process into a reliable, push-button operation. Automation isn't a luxury; it's the foundation for achieving both speed and safety in your releases.
Orchestrating Containerized Workloads
For containerized applications, an orchestrator like Kubernetes is standard. It provides the primitives for managing deployments, services, and networking.
However, for the sophisticated traffic routing required for a clean switch, most teams use a service mesh. Tools like Istio or Linkerd run on top of Kubernetes, offering fine-grained traffic control. They can shift traffic from Blue to Green via a simple configuration update.
- Kubernetes: Manages the lifecycle of your Blue and Green
Deployments, ensuring the correct number of pods for each version are running and healthy. - Service Mesh: Controls the routing rules via custom resources (e.g., Istio's
VirtualService), directing 100% of user traffic to either the Blue or Green pods with a single, atomic update.
The Critical Role of Automated Validation
A fully automated pipeline must make its own go/no-go decisions. This requires integrating with observability tools. Platforms like Prometheus for metrics and Grafana for dashboards provide the real-time data needed to automatically validate the health of the Green environment.
Before the traffic switch, the pipeline should execute automated tests and then query your monitoring system for key SLIs (Service Level Indicators) like error rates and latency. If all SLIs are within their SLOs, the pipeline proceeds. If not, it automatically aborts the deployment and alerts the team, preventing a faulty release from impacting users.
Driving Business Value with Blue-Green Deployment
Beyond the technical benefits, blue-green deployment delivers direct, measurable business value. It is a competitive advantage that translates to increased revenue, customer satisfaction, and market agility.
In high-stakes industries, this strategy is a necessity. E-commerce platforms leverage this model to deploy updates during peak traffic events like Black Friday. The ability to release new features or security patches with zero downtime ensures an uninterrupted customer experience and protects revenue streams.
Achieving Elite Reliability and Uptime
The core business value of blue-green deployment is exceptional reliability. By eliminating the traditional "deployment window," services can approach 100% uptime.
This is a game-changer in sectors like finance and healthcare. Financial firms using blue-green strategies have achieved 99.99% uptime during major system updates, avoiding downtime that can cost millions per minute. In healthcare, it enables seamless updates to patient management systems without disrupting clinical workflows. For more data, see how blue-green deployment is used in critical industries. This intense focus on uptime is a cornerstone of SRE, a topic covered in our guide on site reliability engineering principles.
De-Risking Innovation with Data
Blue-green deployment also provides a low-risk environment for data-driven product decisions. The isolated green environment serves as a perfect laboratory for experimentation.
By directing a small, controlled segment of internal or beta traffic to the green environment, teams can gather real-world performance data and user feedback without impacting the general user base. This turns deployments into opportunities for learning.
This setup is ideal for:
- A/B Testing: Validate new features or UI changes with a subset of users to gather quantitative data for a go/no-go decision.
- Feature Flagging: Test major new capabilities in the green environment under production load before enabling the feature for all users.
This approach transforms high-stress releases into controlled, strategic business moves, empowering teams to innovate faster and with greater confidence.
Frequently Asked Questions
Even with a solid understanding, blue-green deployment presents practical challenges. Here are answers to common implementation questions.
How Does Blue Green Deployment Handle Long-Running User Sessions?
This is a critical consideration for applications with user authentication or shopping carts. A deployment should not terminate active sessions.
The solution is to externalize session state. Instead of storing session data in application memory, use a shared, centralized data store like Redis or Memcached.
With this architecture, both the blue and green environments read and write to the same session store. When the traffic switch occurs, the user's session remains intact and accessible to the new application version, ensuring a seamless experience with no data loss or forced logouts.
Key Insight: The trick is to decouple user sessions from the application instances themselves. A shared session store makes your app effectively stateless from a session perspective, which makes the whole blue-green transition a walk in the park.
What Happens if a Database Schema Change Is Not Backward-Compatible?
A breaking database change is the kryptonite of a simple blue-green deployment. If the new green version requires a schema change that the old blue version cannot handle, applying that change to a shared database will cause the live blue application to fail.
To handle this without downtime, you must break the deployment into multiple phases, often using a pattern known as "expand and contract."
- Expand (Phase 1): Deploy an intermediate version of the application (let's call it "blue-plus"). This version is designed to be compatible with both the old and the new database schemas. It can read from the old schema and write in the new format, or handle both formats gracefully.
- Migrate: With "blue-plus" live, safely apply the breaking schema change to the database. The running application is already prepared to handle it.
- Expand (Phase 2): Deploy the new green application. This version only needs to understand the new schema.
- Contract: Safely switch traffic from "blue-plus" to green. Once the new version is stable, you can decommission "blue-plus" and any old code paths related to the old schema in a future release.
This multi-step process is more complex but is the only way to guarantee that the live application can always communicate with the database, preserving the zero-downtime promise.
Ready to build a flawless blue-green pipeline but don't have the bandwidth in-house? The experts at OpsMoon can help. We connect you with elite DevOps engineers who can design and automate a resilient deployment strategy that fits your exact needs. Start with a free work planning session today and let's map out your path to safer, faster releases.