A Technical Guide to DevOps Resource Allocation Optimization
 By opsmoon
By opsmoonA technical guide to resource allocation optimization in DevOps. Learn strategies for rightsizing, autoscaling, and cost control with actionable examples.
Resource allocation optimization is the engineering discipline of assigning and managing computational assets—CPU, memory, storage, and network I/O—to achieve specific performance targets with maximum cost efficiency. The objective is to leverage data-driven strategies, algorithms, and automation to dynamically adjust resource provisioning, ensuring applications receive the precise resources required at any given moment, eliminating both performance bottlenecks and financial waste.
The Technical Challenge of DevOps Resource Allocation
In a high-velocity DevOps environment, managing infrastructure resources is a complex orchestration problem. Applications are ephemeral workloads, each with unique resource consumption profiles, dependencies, and performance SLOs. The core challenge is to allocate finite infrastructure capacity to meet these demands without creating contention or leaving expensive resources idle.
Misallocation results in two critical failure modes:
- Under-provisioning: Insufficient resource allocation leads to CPU throttling,
OOMKilledevents, high application latency, and potential cascading failures as services fail to meet their SLOs. - Over-provisioning: Allocating excess resources "just in case" results in significant financial waste, with idle CPU cycles and unutilized memory directly translating to a higher cloud bill. This is a direct hit to gross margins.
This continuous optimization problem is the central focus of resource allocation optimization.
The Failure of Static Allocation Models
Legacy static allocation models—assigning a fixed block of CPU and memory to an application at deployment—are fundamentally incompatible with modern CI/CD pipelines and microservices architectures. Workloads are dynamic and unpredictable, subject to fluctuating user traffic, asynchronous job processing, and A/B testing rollouts.
A static model cannot adapt to this volatility. It forces a constant, untenable trade-off: risk performance degradation and SLO breaches or accept significant and unnecessary operational expenditure.
This isn't just an engineering problem; it's a strategic liability. According to one study, 83% of executives view resource allocation as a primary lever for strategic growth. You can analyze the business impact in more detail via McKinsey's research on resource allocation and operational intelligence at akooda.co.
Effective resource management is not a cost-saving tactic; it is a strategic imperative for engineering resilient, high-performance, and scalable distributed systems.
A New Framework for Efficiency
To escape this cycle, engineers require a framework grounded in observability, automation, and a continuous feedback loop. This guide provides actionable, technical strategies for moving beyond theoretical concepts. We will cover the implementation details of predictive autoscaling, granular cost attribution using observability data, and the cultural shifts required to master resource allocation and transform it from an operational burden into a competitive advantage.
Understanding Core Optimization Concepts
To effectively implement resource allocation optimization, you must master the technical mechanisms that control system performance and cost. These are not just abstract terms; they are the fundamental building blocks for engineering an efficient, cost-effective infrastructure that remains resilient under load. The primary goal is to optimize for throughput, utilization, and cost simultaneously.
This diagram illustrates the primary objectives that should guide all technical optimization efforts.
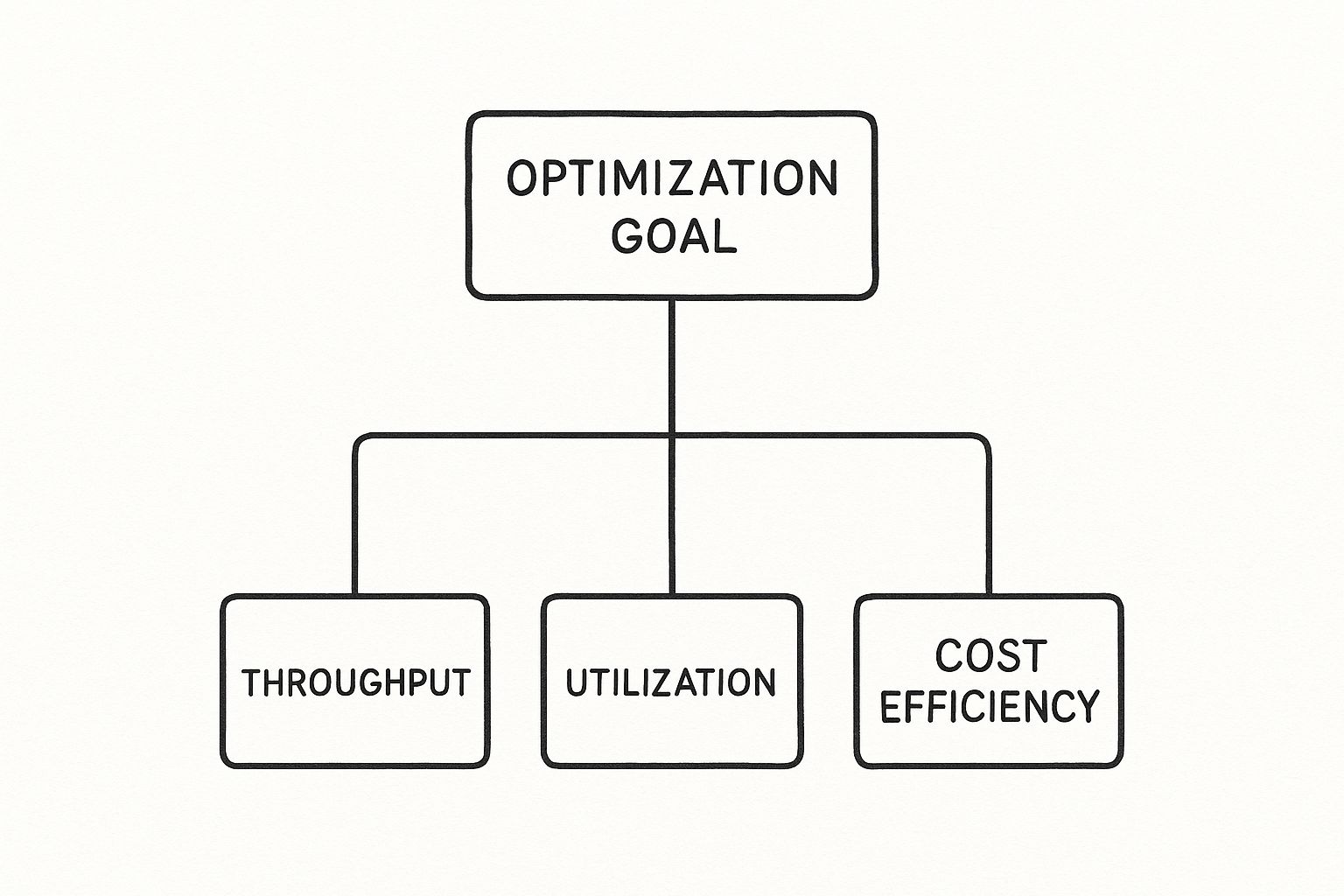
Every implemented strategy is an attempt to improve one of these metrics without negatively impacting the others. It's a multi-objective optimization problem.
To provide a clear technical comparison, let's analyze how these concepts interrelate. Each plays a distinct role in constructing a highly efficient system.
Key Resource Allocation Concepts Compared
| Concept | Primary Goal | Mechanism | Technical Implementation |
|---|---|---|---|
| Rightsizing | Cost Efficiency | Match instance/container specs to actual workload demand by analyzing historical utilization metrics. | Adjusting resource.requests and resource.limits in Kubernetes or changing cloud instance types (e.g., m5.xlarge to t3.large). |
| Autoscaling | Elasticity & Availability | Automatically add/remove compute resources based on real-time metrics (CPU, memory, custom metrics like queue depth). | Implementing Kubernetes Horizontal Pod Autoscaler (HPA) or cloud-native autoscaling groups. |
| Bin Packing | Utilization & Density | Optimize scheduling of workloads onto existing nodes to maximize resource usage and minimize idle capacity. | Leveraging the Kubernetes scheduler's algorithm or custom schedulers to place pods on nodes with the least available resources that still fit. |
This table provides a high-level technical summary. Now, let's examine their practical application.
Rightsizing Your Workloads
The most fundamental optimization technique is rightsizing: aligning resource allocations with the observed needs of a workload. This practice directly combats over-provisioning by eliminating payment for unused CPU cycles and memory.
Effective rightsizing is a continuous process requiring persistent monitoring and analysis of key performance indicators.
- CPU/Memory Utilization: Track P95 and P99 utilization over a meaningful time window (e.g., 7-14 days) to identify the true peak requirements, ignoring transient spikes.
- Request vs. Limit Settings: In Kubernetes, analyze the delta between
resources.requestsandresources.limits. A large, consistently unused gap indicates a prime candidate for rightsizing. - Throttling Metrics: Monitor CPU throttling (
container_cpu_cfs_throttled_seconds_totalin cAdvisor) to ensure rightsizing efforts are not negatively impacting performance.
By systematically adjusting resource configurations based on this telemetry, you ensure you pay only for the capacity your application genuinely consumes.
Autoscaling for Dynamic Demand
While rightsizing establishes an efficient baseline, autoscaling addresses the dynamic nature of real-world demand. It automates the addition and removal of compute resources in response to load, ensuring SLOs are met during traffic spikes while minimizing costs during lulls.
Autoscaling transforms resource management from a static, manual configuration task into a dynamic, closed-loop control system that adapts to real-time application load.
There are two primary scaling dimensions:
-
Horizontal Scaling (Scaling Out): Adding more instances (replicas) of an application. This is the standard for stateless services, distributing load across multiple compute units. It is the foundation of resilient, highly available architectures.
-
Vertical Scaling (Scaling Up): Increasing the resources (CPU, memory) of existing instances. This is typically used for stateful applications like databases or monolithic systems that cannot be easily distributed.
For containerized workloads, mastering these techniques is essential. For a deeper technical implementation guide, see our article on autoscaling in Kubernetes.
Efficiently Packing Your Nodes
Scheduling and bin packing are algorithmic approaches to maximizing workload density. If your nodes are containers and your pods are packages, bin packing is the process of fitting as many packages as possible into each container. The objective is to maximize the utilization of provisioned hardware, thereby reducing the total number of nodes required.
An intelligent scheduler evaluates the resource requests of pending pods and selects the node with the most constrained resources that can still accommodate the pod. This strategy, known as "most-allocated," prevents the common scenario of numerous nodes operating at low (10-20%) utilization. Effective bin packing directly reduces infrastructure costs by minimizing the overall node count.
Actionable Strategies to Optimize Resources
Let's transition from conceptual understanding to technical execution. Implementing specific, data-driven strategies will yield direct improvements in both system performance and cloud expenditure.
We will deconstruct three powerful, hands-on techniques for immediate implementation within a DevOps workflow. These are not high-level concepts but specific methodologies supported by automation and quantitative analysis, addressing optimization from predictive scaling to granular cost attribution.
Predictive Autoscaling Ahead of Demand
Standard autoscaling is reactive, triggering a scaling event only after a performance metric (e.g., CPU utilization) has already crossed a predefined threshold. Predictive autoscaling inverts this model, provisioning resources before an anticipated demand increase. It employs time-series forecasting models (like ARIMA or LSTM) on historical metrics to predict future load and preemptively scale the infrastructure.
Reactive scaling often introduces latency—the time between metric breach and new resource availability. Predictive scaling eliminates this lag. By analyzing historical telemetry from a monitoring system like Prometheus, you can identify cyclical patterns (e.g., daily traffic peaks, seasonal sales events) and programmatically trigger scaling events in advance.
Technical Implementation Example:
A monitoring tool with forecasting capabilities, such as a custom operator using Facebook Prophet or a commercial platform, analyzes Prometheus data. It learns that http_requests_total for a service consistently increases by 300% every weekday at 9:00 AM. Based on this model, an automated workflow can be configured to increase the replica count of the corresponding Kubernetes Deployment from 5 to 15 at 8:55 AM, ensuring capacity is available before the first user hits the spike.
Granular Cost Visibility Through Tagging
Effective optimization is impossible without precise measurement. Granular cost visibility involves meticulously tracking cloud expenditure and attributing every dollar to a specific business context—a team, a project, a feature, or an individual microservice. This transforms an opaque, monolithic cloud bill into a detailed, queryable dataset.
The foundational technology for this is a disciplined tagging and labeling strategy. These are key-value metadata attached to every cloud resource (EC2 instances, S3 buckets) and Kubernetes object (Deployments, Pods).
A robust tagging policy is the technical prerequisite for FinOps. It converts infrastructure from an unmanageable cost center into a transparent system where engineering teams are accountable for the financial impact of their software.
Implement this mandatory tagging policy for all provisioned resources:
team: The owning engineering squad (e.g.,team: backend-auth).project: The specific initiative or service (e.g.,project: user-profile-api).environment: The deployment stage (prod,staging,dev).cost-center: The business unit for financial allocation.
With these tags consistently enforced (e.g., via OPA Gatekeeper policies), you can leverage cost management platforms to generate detailed reports, enabling you to precisely answer questions like, "What is the month-over-month infrastructure cost of the q4-recommendation-engine project?" For deeper insights, review our guide on effective cloud cost optimization strategies.
Automated Rightsizing for Continuous Efficiency
Automated rightsizing operationalizes the process of matching resource allocation to workload demand. It utilizes tools that continuously analyze performance telemetry and either recommend or automatically apply optimized resource configurations, eliminating manual toil and guesswork.
These tools monitor application metrics over time to establish an accurate resource utilization profile, then generate precise recommendations for requests and limits. To accelerate validation during development, integrating parallel testing strategies can help quickly assess the performance impact of new configurations under load.
Consider this technical example using a Kubernetes Vertical Pod Autoscale (VPA) manifest. The VPA controller monitors pod resource consumption and automatically adjusts their resource requests to align with observed usage.
apiVersion: "autoscaling.k8s.ioio/v1"
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: '*'
minAllowed:
cpu: 100m
memory: 256Mi
maxAllowed:
cpu: 2
memory: 4Gi
Here, the VPA's updateMode: "Auto" instructs it to automatically apply its recommendations by evicting and recreating pods with optimized resource requests. This creates a self-tuning system where applications are continuously rightsized for maximum efficiency without human intervention.
Choosing Your Optimization Toolchain
A robust resource allocation strategy requires a carefully selected toolchain to automate and enforce optimization policies. The market offers a wide range of tools, which can be categorized into three primary types, each addressing a different layer of the optimization stack.
The optimal tool mix depends on your infrastructure stack (e.g., VMs vs. Kubernetes), team expertise, and the required depth of analysis.
Cloud-Native Solutions
Major cloud providers (AWS, Azure, GCP) offer built-in tools for foundational resource optimization. Services like AWS Compute Optimizer, Azure Advisor, and GCP Recommender serve as a first-pass optimization layer. They analyze usage patterns and provide straightforward recommendations, such as rightsizing instances, identifying idle resources, or adopting cost-saving purchasing models (e.g., Spot Instances).
Their primary advantage is seamless integration and zero-cost entry. For example, AWS Compute Optimizer might analyze a memory-intensive workload running on a general-purpose m5.2xlarge instance and recommend a switch to a memory-optimized r6g.xlarge, potentially reducing the instance cost by up to 40%.
However, these tools typically provide a high-level, infrastructure-centric view and often lack the application-specific context required for deep optimization, particularly within complex containerized environments.
Container Orchestration Platforms
For workloads running on Kubernetes, the platform itself is a powerful optimization engine. Kubernetes provides a rich set of native controllers and scheduling mechanisms designed for efficient resource management.
Key native components include:
- Horizontal Pod Autoscaler (HPA): Dynamically scales the number of pod replicas based on observed metrics like CPU utilization or custom metrics from Prometheus (e.g., requests per second). When CPU usage exceeds a target like 70%, the HPA controller increases the replica count.
- Vertical Pod Autoscaler (VPA): Analyzes the historical CPU and memory consumption of pods and adjusts their
resource.requeststo match actual usage, preventing waste andOOMKillederrors. - Custom Schedulers: For advanced use cases, you can implement custom schedulers to enforce complex placement logic, such as ensuring high-availability by spreading pods across failure domains or co-locating data-intensive pods with specific hardware.
Mastering these native Kubernetes capabilities is fundamental for any container-based resource optimization strategy.
Third-Party Observability and FinOps Platforms
While cloud-native and Kubernetes tools are powerful, they often operate in silos. Third-party platforms like Kubecost, Datadog, and Densify integrate disparate data sources into a single, unified view, correlating performance metrics with granular cost data.
These platforms address complex challenges that native tools cannot:
For instance, they can aggregate cost and usage data from multiple cloud providers (AWS, Azure, GCP) and on-premises environments into a single dashboard, providing essential visibility for hybrid and multi-cloud architectures.
They also offer advanced AI-driven analytics and "what-if" scenario modeling for capacity planning and budget forecasting. For a detailed comparison of available solutions, see our guide on the best cloud cost optimization tools.
This screenshot from Kubecost illustrates a cost breakdown by Kubernetes primitives like namespaces and deployments.
This level of granularity—attributing cloud spend directly to an application, team, or feature—is the cornerstone of a functional FinOps culture. It empowers engineers with direct financial feedback on their architectural decisions, a capability not available in standard cloud billing reports.
Building a Culture of Continuous Optimization
Advanced tooling and automated strategies are necessary but insufficient for achieving sustained resource efficiency. Lasting optimization is the result of a cultural transformation—one that establishes resource management as a continuous, automated, and shared responsibility across the entire engineering organization.
Technology alone cannot solve systemic over-provisioning. Sustainable efficiency requires a culture where every engineer is accountable for the cost and performance implications of the code they ship. This is the essence of a FinOps culture.
Fostering a FinOps Culture
FinOps is an operational framework and cultural practice that brings financial accountability to the variable spending model of the cloud. It establishes a collaborative feedback loop between engineering, finance, and business units to collectively manage the trade-offs between delivery speed, cost, and quality.
In a FinOps model, engineering teams are provided with the data, tools, and autonomy to own their cloud expenditure. This direct ownership incentivizes the design of more efficient and cost-aware architectures from the outset.
A mature FinOps culture reframes the discussion from "How much was the cloud bill?" to "What business value did we generate per dollar of cloud spend?" Cost becomes a key efficiency metric, not merely an expense.
This shift is critical at scale. A fragmented, multi-national organization can easily waste millions in unoptimized cloud resources due to a lack of centralized visibility and accountability. Data fragmentation can lead to $50 million in missed optimization opportunities annually, as detailed in this analysis of resource allocation for startups at brex.com.
Integrating Optimization into Your CI/CD Pipeline
To operationalize this culture, you must embed optimization checks directly into the software development lifecycle. The CI/CD pipeline is the ideal enforcement point for resource efficiency standards, providing immediate feedback to developers.
Implement these automated checks in your pipeline:
- Enforce Resource Request Ceilings: Configure pipeline gates to fail any build that defines Kubernetes resource requests exceeding a predefined, reasonable maximum (e.g.,
cpu: 4,memory: 16Gi). This forces developers to justify exceptionally large allocations. - Identify Idle Development Resources: Run scheduled jobs that query cloud APIs or Kubernetes clusters to identify and flag resources in non-production environments (
dev,staging) that have been idle (e.g., <5% CPU utilization) for an extended period (e.g., >48 hours). - Integrate "Cost-of-Change" Reporting: Use tools that integrate with your VCS (e.g., GitHub) to post the estimated cost impact of infrastructure changes as a comment on pull requests. This makes the financial implications of a merge explicit to both the author and reviewers.
Creating a Unified Multi-Cloud Strategy
In multi-cloud and hybrid environments, optimization complexity increases exponentially. Each cloud has distinct services, pricing models, and APIs, making a unified governance and visibility strategy essential.
Establish a central "Cloud Center of Excellence" (CCoE) or platform engineering team. This team is responsible for defining and enforcing cross-platform standards for tagging, security policies, and resource allocation best practices. Their role is to ensure that workloads adhere to the same principles of efficiency and accountability, regardless of whether they run on AWS, Azure, GCP, or on-premises infrastructure.
Your Technical Go-Forward Plan
It is time to transition from theory to execution.
Sustained resource optimization is not achieved through reactive, ad-hoc cost-cutting measures. It is the result of engineering a more intelligent, efficient, and resilient system that accelerates innovation. This is your technical blueprint.
Effective optimization is built on three pillars: visibility, automation, and culture. Visibility provides the data to identify waste. Automation implements the necessary changes at scale. A robust FinOps culture ensures these practices become ingrained in your engineering DNA. The end goal is to make efficiency an intrinsic property of your software delivery process.
The competitive advantage lies in treating resource management as a core performance engineering discipline. An optimized system is not just cheaper to operate—it is faster, more reliable, and delivers a superior end-user experience.
This checklist provides concrete, actionable first steps to build immediate momentum.
Your Initial Checklist
- Conduct a Resource Audit on a High-Spend Service: Select a single, high-cost application. Over a 7-day period, collect and analyze its P95 and P99 CPU and memory utilization data. Compare these observations to its currently configured
resource.requeststo identify the precise magnitude of over-provisioning. - Implement a Mandatory Tagging Policy: Define a minimal, mandatory tagging policy (
team,project,environment) and use a policy-as-code tool (e.g., OPA Gatekeeper) to enforce its application on all new resource deployments. This is the first step to cost attribution. - Deploy HPA on a Pilot Application: Select a stateless, non-critical service and implement a Horizontal Pod Autoscaler (HPA). Configure it with a conservative CPU utilization target (e.g., 75%) and observe its behavior under varying load. This builds operational confidence in automated scaling.
Executing these technical steps will transform optimization from an abstract concept into a measurable engineering practice that improves both your bottom line and your development velocity.
Technical FAQ on Resource Optimization
This section addresses common technical questions encountered during the implementation of resource allocation optimization strategies.
How Do I Choose Between Vertical and Horizontal Scaling?
The decision between horizontal and vertical scaling is primarily dictated by application architecture and statefulness.
Horizontal scaling (scaling out) increases the replica count of an application. It is the standard for stateless services (e.g., web frontends, APIs) that can be easily load-balanced. It is the architectural foundation for building resilient, highly available systems that can tolerate individual instance failures.
Vertical scaling (scaling up) increases the resources (CPU, memory) allocated to a single instance. This method is typically required for stateful applications that are difficult to distribute, such as traditional relational databases (e.g., PostgreSQL) or legacy monolithic systems.
In modern Kubernetes environments, a hybrid approach is common: use a Horizontal Pod Autoscaler (HPA) for reactive scaling of replicas and a Vertical Pod Autoscaler (VPA) to continuously rightsize the resource requests of individual pods.
What Are the Biggest Mistakes When Setting Kubernetes Limits?
Three common and critical errors in configuring Kubernetes resource requests and limits lead to significant instability and performance degradation.
- Omitting limits entirely: This is the most dangerous practice. A single pod with a memory leak or a runaway process can consume all available resources on a node, triggering a cascade of pod evictions and causing a node-level outage.
- Setting
limitsequal torequests: This assigns the pod aGuaranteedQuality of Service (QoS) class but prevents it from using any temporarily idle CPU on the node (burstable capacity). This can lead to unnecessary CPU throttling and reduced performance even when node resources are available. - Setting
limitstoo low: This results in persistent performance issues. For memory, it causes frequentOOMKilledevents. For CPU, it leads to severe application throttling, manifesting as high latency and poor responsiveness.
The correct methodology is to set
requestsbased on observed typical utilization (e.g., P95) andlimitsbased on an acceptable peak (e.g., P99 or a hard ceiling). This provides a performance buffer while protecting cluster stability. These values should be determined through rigorous performance testing, not guesswork.
Can Optimization Negatively Impact Performance?
Yes, improperly executed resource allocation optimization can severely degrade performance.
Aggressive or data-ignorant rightsizing leads to resource starvation (under-provisioning), which manifests as increased application latency, higher error rates, and system instability. Forcing a workload to operate with insufficient CPU or memory is a direct path to violating its Service Level Objectives (SLOs).
To mitigate this risk, every optimization decision must be data-driven.
- Establish a performance baseline using observability tools before making any changes.
- Introduce changes incrementally, beginning in non-production environments.
- Continuously monitor key performance indicators (latency, saturation, errors) after each adjustment.
True optimization finds the equilibrium point where sufficient resources are allocated for excellent performance without wasteful over-provisioning. It is a performance engineering discipline, not merely a cost-cutting exercise.
At OpsMoon, we specialize in implementing the advanced DevOps strategies that turn resource management into a competitive advantage. Our top-tier engineers can help you build a cost-effective, high-performance infrastructure tailored to your needs. Start with a free work planning session to map out your optimization roadmap. Find your expert at opsmoon.com.