A Technical Guide to Legacy Systems Modernization
 By opsmoon
By opsmoonA practical guide to legacy systems modernization: assess your stack, choose a migration strategy, and execute a seamless DevOps-driven transition.
Wrestling with a brittle, monolithic architecture that stifles innovation and accumulates technical debt? Legacy systems modernization is the strategic, technical overhaul required to transform these outdated systems into resilient, cloud-native assets. This guide provides a developer-first, actionable roadmap for converting a critical business liability into a tangible competitive advantage.
Why Modernizing Legacy Systems Is an Engineering Imperative
Technical inertia is no longer a viable strategy. Legacy systems inevitably become a massive drain on engineering resources, characterized by exorbitant maintenance costs, a dwindling talent pool proficient in obsolete languages, and a fundamental inability to integrate with modern APIs and toolchains.
This technical debt does more than just decelerate development cycles; it actively constrains business growth. New feature deployments stretch from weeks to months. Applying a CVE patch becomes a high-risk, resource-intensive project. The system behaves like an opaque black box, where any modification carries the risk of cascading failures.
The Technical and Financial Costs of Inaction
Postponing modernization incurs tangible and severe consequences. Beyond operational friction, the financial and security repercussions directly impact the bottom line. These outdated systems are almost universally plagued by:
- Exploitable Security Vulnerabilities: Unpatched frameworks and unsupported runtimes (e.g., outdated Java versions, legacy PHP) create a large attack surface. The probability of a breach becomes a near certainty over time.
- Spiraling Maintenance Costs: A significant portion of the IT budget is consumed by maintaining systems that deliver diminishing returns, from expensive proprietary licenses to the high cost of specialist developers.
- Innovation Paralysis: Engineering talent is misallocated to maintaining legacy code and mitigating operational fires instead of developing new, value-generating features that drive business outcomes.
A proactive modernization initiative is not just an IT project. It is a core engineering decision that directly impacts your organization's agility, security posture, and long-term viability. It is a technical investment in future-proofing your entire operation.
Industry data confirms this trend. A staggering 78% of US enterprises are planning to modernize at least 40% of their legacy applications by 2026. This highlights the urgency to decommission resource-draining systems. Companies that delay face escalating maintenance overhead and the constant threat of catastrophic failures.
Understanding the business drivers is foundational, as covered in articles like this one on how Canadian businesses can thrive by modernizing outdated IT systems. However, this guide moves beyond the "why" to provide a technical execution plan for the "how."
Step 1: Auditing Your Legacy Systems and Defining Scope
Every successful modernization project begins with a deep, quantitative audit of the existing technology stack. This is a technical discovery phase focused on mapping the terrain, identifying anti-patterns, and uncovering hidden dependencies before defining a strategy.
Skipping this step introduces unacceptable risk. Projects that underestimate complexity, select an inappropriate modernization pattern, and fail to secure stakeholder buy-in inevitably see their budgets and timelines spiral out of control. A thorough audit provides the empirical data needed to construct a realistic roadmap and prioritize work that delivers maximum business value with minimal technical risk.
Performing a Comprehensive Code Analysis
First, dissect the codebase. Legacy applications are notorious for accumulating years of technical debt, rendering them brittle, non-deterministic, and difficult to modify. The objective here is to quantify this debt and establish a baseline for the application's health.
Static and dynamic analysis tools are indispensable. A tool like SonarQube is ideal for this, scanning repositories to generate concrete metrics on critical indicators:
- Cyclomatic Complexity: Identify methods and classes with high complexity scores. These are hotspots for bugs and primary candidates for refactoring into smaller, single-responsibility functions.
- Code Smells and Duplication: Programmatically detect duplicated logic and architectural anti-patterns. Refactoring duplicated code blocks can significantly reduce the surface area of the codebase that needs to be migrated.
- Test Coverage: This is a critical risk indicator. A component with less than 30% unit test coverage is a high-risk liability. Lacking a test harness means there is no automated way to verify that changes have not introduced regressions.
- Dead Code: Identify and eliminate unused functions, classes, and variables. This is a low-effort, high-impact action that immediately reduces the scope of the migration.
This data-driven analysis replaces anecdotal evidence with an objective, quantitative map of the codebase's most problematic areas.
Mapping Your Infrastructure and Dependencies
With a clear understanding of the code, the next step is to map its operating environment. Legacy systems are often supported by undocumented physical servers, arcane network configurations, and implicit dependencies that are not captured in any documentation.
Your infrastructure map must document:
- Hardware and Virtualization: Enumerate every on-premise server and VM, capturing specifications for CPU, memory, and storage. This data is crucial for right-sizing cloud instances (e.g., AWS EC2, Azure VMs) to optimize cost.
- Network Topology: Diagram firewalls, load balancers, and network segments. Pay close attention to inter-tier connections sensitive to latency, as these can become performance bottlenecks in a hybrid-cloud architecture.
- Undocumented Dependencies: Use network monitoring (e.g., tcpdump, Wireshark) and service mapping tools to trace every API call, database connection, and message queue interaction. This process will invariably uncover critical dependencies that are not formally documented.
Assume all existing documentation is outdated. The running system is the only source of truth. Utilize discovery tools and validate every dependency programmatically.
Reviewing Data Architecture and Creating a Readiness Score
Finally, analyze the data layer. Outdated schemas, denormalized data, and inefficient queries can severely impede a modernization project. A comprehensive data architecture review is essential for understanding "data gravity"—the tendency for data to attract applications and services.
Identify data silos where information is duplicated across disparate databases, creating data consistency issues. Analyze database schemas for normalization issues or data types incompatible with modern cloud databases (e.g., migrating from Oracle to PostgreSQL).
Synthesize the findings from your code, infrastructure, and data audits into a "modernization readiness score" for each application component. This enables objective prioritization. A high-risk, low-value component with extensive dependencies and no test coverage should be deprioritized. A high-value, loosely coupled service represents a quick win and should be tackled first. This scoring system transforms an overwhelming project into a sequence of manageable, strategic phases.
Step 2: Choosing Your Modernization Pattern
With the discovery phase complete, you are now armed with empirical data about your technical landscape. This clarity is essential for selecting the appropriate modernization pattern—a decision that dictates the project's scope, budget, and technical outcome. There is no one-size-fits-all solution; the optimal path is determined by an application's business value, technical health, and strategic importance.
The prevailing framework for this decision is the "5 Rs": Rehost, Replatform, Refactor, Rearchitect, and Replace. Each represents a distinct level of effort and transformation.
This decision tree illustrates how the audit findings from your code, infrastructure, and data analyses inform the selection of the most logical modernization pattern.
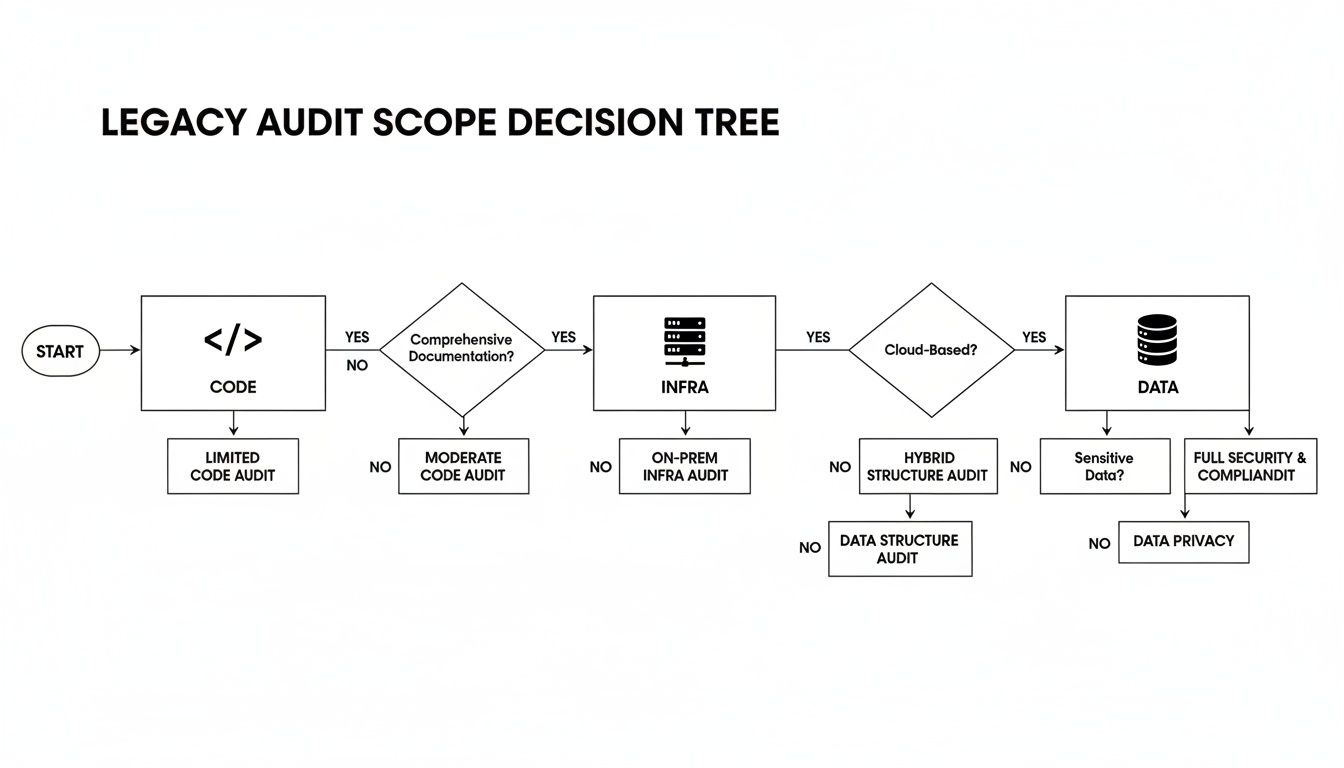
As shown, the insights gathered directly constrain the set of viable patterns for any given application.
Understanding the Core Modernization Strategies
Let's deconstruct these patterns from a technical perspective. Each addresses a specific problem domain and involves distinct trade-offs.
-
Rehost (Lift-and-Shift): The fastest, least disruptive option. You migrate an application from an on-premise server to a cloud-based virtual machine (IaaS) with minimal to no code modification. This is a sound strategy for low-risk, monolithic applications where the primary objective is rapid data center egress. You gain infrastructure elasticity without unlocking cloud-native benefits.
-
Replatform (Lift-and-Tinker): An incremental improvement over rehosting, this pattern involves minor application modifications to leverage managed cloud services. A common example is migrating a monolithic Java application to a managed platform like Azure App Service or containerizing it to run on a serverless container platform like AWS Fargate. This approach provides a faster path to some cloud benefits without the cost of a full rewrite.
-
Refactor: This involves restructuring existing code to improve its internal design and maintainability without altering its external behavior. In a modernization context, this often means decomposing a monolith by extracting modules into separate libraries to reduce technical debt. Refactoring is a prudent preparatory step before a more significant re-architecture.
Pattern selection is a strategic decision that must align with business priorities, timelines, and budgets. A low-impact internal application is a prime candidate for Rehosting, whereas a core, customer-facing platform may necessitate a full Rearchitect.
Rearchitect and Replace: The Most Transformative Options
While the first three "Rs" focus on evolving existing assets, the final two involve fundamental transformation. They represent larger investments but yield the most significant long-term technical and business value.
-
Rearchitect: The most complex and rewarding approach. This involves a complete redesign of the application's architecture to be cloud-native. The canonical example is decomposing a monolith into a set of independent microservices, orchestrated with a platform like Kubernetes. This pattern maximizes scalability, resilience, and deployment velocity but requires deep expertise in distributed systems and a significant investment.
-
Replace: In some cases, the optimal strategy is to decommission the legacy system entirely and substitute it with a new solution. This could involve building a new application from scratch but more commonly entails adopting a SaaS product. When migrating to a platform like Microsoft 365, a detailed technical playbook for SharePoint migrations from legacy platforms is invaluable, providing guidance on planning, data migration, and security configuration.
Comparing the 5 Core Modernization Strategies
Selecting the right path requires a careful analysis of the trade-offs of each approach against your specific technical goals, team capabilities, and risk tolerance.
The table below provides a comparative analysis of the five strategies, breaking down the cost, timeline, risk profile, and required technical expertise for each.
| Strategy | Description | Typical Use Case | Cost & Timeline | Risk Level | Required Expertise |
|---|---|---|---|---|---|
| Rehost | Migrating servers or VMs "as-is" to an IaaS provider like AWS EC2 or Azure VMs. | Non-critical, self-contained apps; quick data center exits. | Low & Short (Weeks) |
Low | Cloud infrastructure fundamentals, basic networking. |
| Replatform | Minor application changes to leverage PaaS; containerization. | Monoliths that need some cloud benefits without a full rewrite. | Medium & Short (Months) |
Medium | Containerization (Docker), PaaS (e.g., Azure App Service, Elastic Beanstalk). |
| Refactor | Restructuring code to reduce technical debt and improve modularity. | A critical monolith that's too complex or risky to rearchitect immediately. | Medium & Ongoing | Medium | Strong software design principles, automated testing. |
| Rearchitect | Decomposing a monolith into microservices; adopting cloud-native patterns. | Core business applications demanding high scalability and agility. | High & Long (Months-Years) |
High | Microservices architecture, Kubernetes, distributed systems design. |
| Replace | Decommissioning the old app and moving to a SaaS or custom-built solution. | Systems where functionality is already available off-the-shelf. | Varies & Medium | Varies | Vendor management, data migration, API integration. |
The decision ultimately balances short-term tactical wins against long-term strategic value. A rapid Rehost may resolve an immediate infrastructure problem, but a methodically executed Rearchitect can deliver a sustainable competitive advantage.
Step 3: Executing the Migration with Modern DevOps Practices
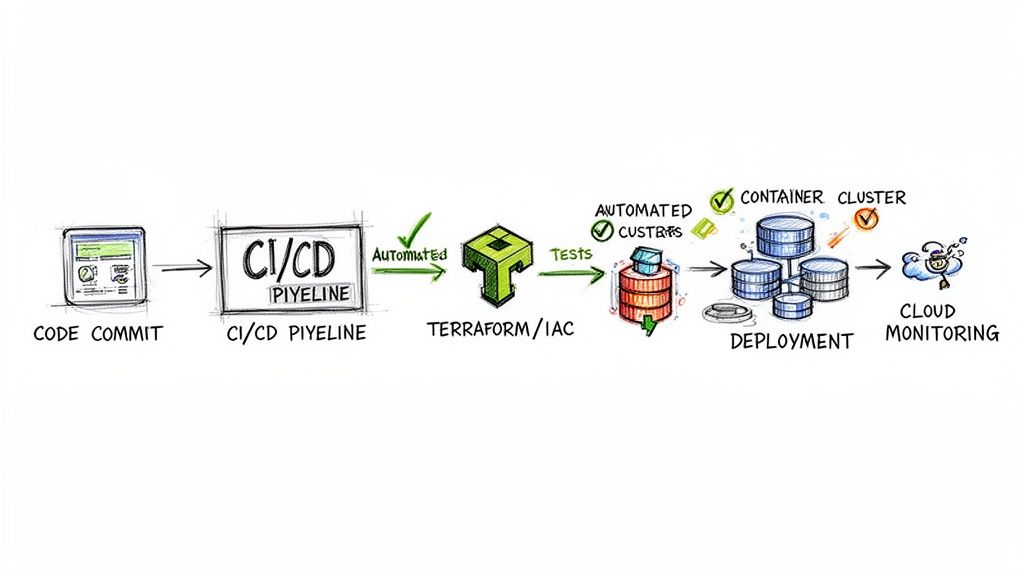
With a modernization pattern selected, the project transitions from planning to execution. This is where modern DevOps practices are not just beneficial but essential. The goal is to transform a high-risk, manual migration into a predictable, automated, and repeatable process. Automation is the core of a robust execution strategy, enabling confident deployment, testing, and rollback while eliminating the error-prone nature of manual server configuration and deployments.
Infrastructure as Code: The Foundation of Your New Environment
The first step is to provision your cloud environment in a version-controlled and fully reproducible manner using Infrastructure as Code (IaC). Tools like Terraform allow you to define all cloud resources—VPCs, subnets, Kubernetes clusters, IAM roles—in declarative configuration files.
Manual configuration via a cloud console inevitably leads to "configuration drift," creating inconsistencies between environments that are impossible to replicate or debug. IaC solves this by treating infrastructure as a first-class citizen of your codebase.
For example, instead of manually configuring a VPC in the AWS console, you define it in a Terraform module:
# main.tf for a simple VPC module
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
tags = {
Name = "modernized-app-vpc"
}
}
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
map_public_ip_on_launch = true
tags = {
Name = "public-subnet"
}
}
This declarative code defines a VPC and a public subnet. It is versionable in Git, peer-reviewed, and reusable across development, staging, and production environments, guaranteeing consistency.
Automating Delivery with Robust CI/CD Pipelines
With infrastructure defined as code, the next step is automating application deployment. A Continuous Integration/Continuous Deployment (CI/CD) pipeline automates the entire release process, from code commit to production deployment.
Using tools like GitHub Actions or GitLab CI, you can construct a pipeline that automates critical tasks:
- Builds and Containerizes: Compiles source code and packages it into a Docker container.
- Runs Automated Tests: Executes unit, integration, and end-to-end test suites to detect regressions early.
- Scans for Vulnerabilities: Integrates security scanning tools (e.g., Snyk, Trivy) to identify known vulnerabilities in application code and third-party dependencies.
- Deploys Incrementally: Pushes new container images to your Kubernetes cluster using safe deployment strategies like blue-green or canary deployments to minimize the blast radius of a faulty release.
To build a resilient pipeline, it is crucial to adhere to established CI/CD pipeline best practices.
Your CI/CD pipeline functions as both a quality gate and a deployment engine. Investing in a robust, automated pipeline yields significant returns by reducing manual errors and accelerating feedback loops.
Market data supports this approach. The Legacy Modernization market is projected to reach USD 56.87 billion by 2030, driven by cloud adoption. For engineering leaders, this highlights the criticality of skills in Kubernetes, Terraform, and CI/CD, which have been shown to deliver a 228-304% ROI over three years.
Navigating the Data Migration Challenge
Data migration is often the most complex and high-risk phase of any modernization project. An error can lead to data loss, corruption, or extended downtime. The two primary strategies are "big-bang" and "trickle" migrations.
-
Big-Bang Migration: This approach involves taking the legacy system offline, migrating the entire dataset in a single operation, and then switching over to the new system. It is conceptually simple but carries high risk and requires significant downtime, making it suitable only for non-critical systems with small datasets.
-
Trickle Migration: This is a safer, phased approach that involves setting up a continuous data synchronization process between the old and new systems. Changes in the legacy database are replicated to the new database in near real-time. This allows for a gradual migration with zero downtime, although the implementation is more complex.
For most mission-critical applications, a trickle migration is the superior strategy. Tools like AWS Database Migration Service (DMS) or custom event-driven pipelines (e.g., using Kafka and Debezium) enable you to run both systems in parallel. This allows for continuous data integrity validation and a confident, low-risk final cutover.
Step 4: Post-Migration Validation and Observability
Deploying the modernized system is a major milestone, but the project is not complete. The focus now shifts from migration to stabilization. This post-launch phase is dedicated to verifying that the new system is not just operational but also performant, resilient, and delivering on its business objectives.
Simply confirming that the application is online is insufficient. Comprehensive validation involves subjecting the system to realistic stress to identify performance bottlenecks, security vulnerabilities, and functional defects before they impact end-users.
Building a Comprehensive Validation Strategy
A robust validation plan extends beyond basic smoke tests and encompasses three pillars of testing, each designed to answer a specific question about the new architecture.
- Performance and Load Testing: How does the system behave under load? Use tools like JMeter or k6 to simulate realistic user traffic, including peak loads and sustained high-volume scenarios. Monitor key performance indicators (KPIs) such as p95 and p99 API response times, database query latency, and resource utilization (CPU, memory) to ensure you are meeting your Service Level Objectives (SLOs).
- Security Vulnerability Scanning: Have any vulnerabilities been introduced? Execute both static application security testing (SAST) and dynamic application security testing (DAST) scans against the deployed application. This provides a critical layer of defense against common vulnerabilities like SQL injection or cross-site scripting (XSS).
- User Acceptance Testing (UAT): Does the system meet business requirements? Engage end-users to execute their standard workflows in the new system. Their feedback is invaluable for identifying functional gaps and usability issues that automated tests cannot detect.
An automated and well-rehearsed rollback plan is a non-negotiable safety net. This should be an automated script or a dedicated pipeline stage capable of reverting to the last known stable version—including application code, configuration, and database schemas. This plan must be tested repeatedly.
From Reactive Monitoring to Proactive Observability
Legacy system monitoring was typically reactive, focused on system-level metrics like CPU and memory utilization. Modern, distributed systems are far more complex and demand observability.
Observability is the ability to infer a system's internal state from its external outputs, allowing you to ask arbitrary questions about its behavior without needing to pre-define every potential failure mode. It's about understanding the "why" behind an issue.
This requires implementing a comprehensive observability stack. Moving beyond basic monitoring, a modern stack provides deep, actionable insights. For a deeper dive, review our guide on what is continuous monitoring. A standard, effective stack includes:
- Metrics (Prometheus): For collecting time-series data on application throughput, Kubernetes pod health, and infrastructure performance.
- Logs (Loki or the ELK Stack): For aggregating structured logs that provide context during incident analysis.
- Traces (Jaeger or OpenTelemetry): For tracing a single request's path across multiple microservices, which is essential for debugging performance issues in a distributed architecture.
By consolidating this data in a unified visualization platform like Grafana, engineers can correlate metrics, logs, and traces to identify the root cause of an issue in minutes rather than hours. You transition from "the server is slow" to "this specific database query, initiated by this microservice, is causing a 300ms latency spike for 5% of users."
The ROI for successful modernization is substantial. Organizations often report 25-35% reductions in infrastructure costs, 40-60% faster release cycles, and a 50% reduction in security breach risks. These are tangible engineering and business outcomes, as detailed in the business case for these impressive outcomes.
Knowing When to Bring in Expert Help
Even highly skilled engineering teams can encounter significant challenges during a complex legacy systems modernization. Initial momentum can stall as the unforeseen complexities of legacy codebases and undocumented dependencies emerge, leading to schedule delays and cost overruns.
Reaching this point is not a sign of failure; it is an indicator that an external perspective is needed. Engaging an expert partner is a strategic move to de-risk the project and regain momentum. A fresh set of eyes can validate your architectural decisions or, more critically, identify design flaws before they become costly production failures.
Key Signals to Engage an Expert
If your team is facing any of the following scenarios, engaging a specialist partner can be transformative:
- Stalled Progress: The project has lost momentum. The same technical roadblocks recur, milestones are consistently missed, and there is no clear path forward.
- Emergent Skill Gaps: Your team lacks deep, hands-on experience with critical technologies required for the project, such as advanced Kubernetes orchestration, complex Terraform modules, or specific data migration tools.
- Team Burnout: Engineers are stretched thin between maintaining legacy systems and tackling the high cognitive load of the modernization initiative. Constant context-switching is degrading productivity and morale.
An expert partner provides more than just additional engineering capacity; they bring a battle-tested playbook derived from numerous similar engagements. They can anticipate and solve problems that your team is encountering for the first time.
Access to seasoned DevOps engineers offers a flexible and cost-effective way to inject specialized skills exactly when needed. They can assist with high-level architectural strategy, provide hands-on implementation support, or manage the entire project delivery. The right partner ensures your modernization project achieves its technical and business goals on time and within budget.
When you are ready to explore how external expertise can accelerate your project, learning about the engagement models of a DevOps consulting company is a logical next step.
Got Questions? We've Got Answers
Executing a legacy systems modernization project inevitably raises numerous technical questions. Here are answers to some of the most common queries from CTOs and engineering leaders.
What's the Real Difference Between Lift-and-Shift and Re-architecting?
These terms are often used interchangeably, but they represent fundamentally different strategies.
Lift-and-shift (Rehosting) is the simplest approach. It involves migrating an application "as-is" from an on-premise server to a cloud VM. Code modifications are minimal to non-existent. This is the optimal strategy for rapid data center exit strategies.
Re-architecting, in contrast, is a complete redesign and rebuild. This typically involves decomposing a monolithic application into cloud-native microservices, often running on a container orchestration platform like Kubernetes. It is a significant engineering effort that yields substantial long-term benefits in scalability, resilience, and agility.
How Do You Pick the Right Modernization Strategy?
There is no single correct answer. The optimal strategy is a function of your technical objectives, budget, and the current state of the legacy application.
A useful heuristic: A critical, high-revenue application that is central to your business strategy likely justifies the investment of a full Rearchitect. You need it to be scalable and adaptable for the future. Conversely, a low-impact internal tool that simply needs to remain operational is an ideal candidate for a quick Rehost or Replatform to reduce infrastructure overhead.
An initial audit is non-negotiable. Analyze code complexity, map dependencies, and quantify the application's business value. This data-driven approach is what elevates the decision from a guess to a sound technical strategy.
So, How Long Does This Actually Take?
The timeline for a modernization project varies significantly based on its scope and complexity.
A simple lift-and-shift migration can often be completed in a few weeks. However, a full re-architecture of a core business system can take several months to over a year for highly complex applications.
The recommended approach is to avoid a "big bang" rewrite. A phased, iterative strategy is less risky, allows for continuous feedback, and begins delivering business value much earlier in the project lifecycle.
Feeling like you're in over your head? That's what OpsMoon is for. We'll connect you with elite DevOps engineers who live and breathe this stuff. They can assess your entire setup, map out a clear, actionable plan, and execute your migration flawlessly. Get in touch for a free work planning session and let's figure it out together.