A Technical Guide to Cloud Infrastructure Management Services
 By opsmoon
By opsmoonExplore expert cloud infrastructure management services to optimize cost, security, and performance. Learn to build and scale a resilient cloud strategy.

Think of cloud infrastructure management services as the centralized command-and-control system for your digital architecture. It’s the technical discipline of provisioning, configuring, monitoring, and optimizing all your cloud resources—compute instances, storage volumes, network configurations, and security policies—across platforms like AWS, Azure, or Google Cloud. This management layer is what transforms a disparate collection of virtual components into a high-performing, resilient, and cost-efficient strategic asset.
What Are Cloud Infrastructure Management Services?
At its core, cloud infrastructure management is the ongoing technical practice of administering the fundamental building blocks of your cloud environment. This is not a passive "keep the lights on" function. It's an active, hands-on discipline focused on orchestrating compute, storage, networking, and security components to work in concert, delivering performance, reliability, and cost-efficiency.
Without disciplined management, a cloud environment can quickly devolve into a chaotic, insecure, and expensive liability. Imagine an unmanaged Kubernetes cluster where developers deploy oversized pods without resource limits, leading to node saturation, cascading failures, and a bill that’s 3x the forecast. Effective cloud management implements the governance and automation to prevent such scenarios.
The Growing Demand for Expert Management
The enterprise-wide shift to cloud-native architectures has ignited this sector. The global market for cloud infrastructure services hit about $142.35 billion in 2024 and is projected to expand to $396.01 billion by 2032.
With an estimated 85% of organizations planning to operate on a cloud-first basis by 2025, the need for expert management to govern these increasingly complex, distributed systems has become a critical business requirement. You can analyze more data on this market expansion and its key drivers.
A well-managed cloud infrastructure is the difference between a strategic asset that accelerates business velocity and a reactive liability that drains financial resources, consumes engineering cycles, and stifles innovation.
Core Functions of Cloud Infrastructure Management
So, what does this management practice entail at a technical level? It comprises a set of continuous, automated activities that ensure your cloud resources are healthy, secure, and performing at peak efficiency. For any organization leveraging the cloud, these functions are non-negotiable.
Here’s a breakdown of the primary responsibilities and the tooling involved.
| Management Function | Core Tasks & Technical Implementation | Business Outcome |
|---|---|---|
| Resource Provisioning | Define infrastructure as code (IaC) using tools like Terraform or CloudFormation. Automate deployments via CI/CD pipelines (e.g., Jenkins, GitLab CI). | Rapid, repeatable, and version-controlled infrastructure deployments, eliminating configuration drift. |
| Performance Monitoring | Instrument applications with APM agents. Collect and analyze metrics like CPU utilization, p99 latency, and error rates using observability platforms. | Proactive anomaly detection and root-cause analysis, minimizing Mean Time to Resolution (MTTR). |
| Security & Compliance | Implement fine-grained IAM policies following the principle of least privilege. Configure security groups/NACLs to enforce network segmentation. Run automated compliance scans. | Hardened security posture, reduced attack surface, and continuous readiness for audits (e.g., SOC 2, ISO 27001). |
| Cost Optimization | Implement a mandatory resource tagging policy. Continuously analyze cost and usage reports to right-size instances. Automate shutdown of non-production environments. | Reduced Total Cost of Ownership (TCO) and improved ROI on cloud spend. |
Ultimately, these functions ensure your cloud environment is not just operational, but architected to actively support and accelerate your business objectives. They form the foundation of a stable, secure, and cost-effective digital operation.
Deconstructing Your Modern Cloud Infrastructure
To effectively manage your cloud infrastructure, you must first understand its constituent components at a technical level. The best analogy is a high-performance vehicle. You don't need to machine the engine block yourself, but you must understand the function of the fuel injection system, ECU, and drivetrain to diagnose issues and optimize performance.
The same principle applies to the technical services that constitute any modern cloud architecture.
These aren't just abstract concepts; they are the specific, billable services you will use to build, deploy, and scale your applications. Enterprise spending on these services reached a staggering $94 billion in Q1 2025 alone, a 23% year-over-year increase driven by core infrastructure and AI-specific services. You can analyze the details of this rapid market expansion and its causes on CRN.com.
Core Compute Services
Compute is the "engine" of your cloud infrastructure. It’s the raw processing power that executes your application code. It manifests in several forms, each optimized for different use cases and architectural patterns.
- Virtual Machines (VMs): The foundational IaaS offering (e.g., AWS EC2, Azure VMs). A VM emulates a complete physical server, including its own OS kernel. VMs are ideal for lift-and-shift migrations of legacy applications or workloads requiring specific OS-level configurations.
- Containers (e.g., Docker, Kubernetes): Containers virtualize the operating system, packaging an application with its dependencies into a lightweight, portable unit. Orchestrated by platforms like Kubernetes, they are the de facto standard for building scalable, resilient microservices-based applications.
- Serverless Functions (e.g., AWS Lambda, Azure Functions): These are event-driven, stateless compute services. Code is executed in response to a trigger (e.g., an API call, a file upload to S3). You manage no underlying infrastructure. This model is highly effective for asynchronous tasks, data processing pipelines, and API backends with variable traffic.
Storage and Database Solutions
Data is the lifeblood of your applications. Selecting the appropriate storage or database service is a critical architectural decision that directly impacts performance, scalability, and cost. Each service is purpose-built for a specific data access pattern.
The essence of superior cloud architecture is not merely selecting powerful services, but selecting the right service for the specific workload. Using a high-performance transactional database like Amazon Aurora to store terabytes of static log files is an act of gross inefficiency—it’s like using a Formula 1 car to haul lumber. You will pay a premium for capabilities you don't need.
To gain proficiency, you must understand the landscape. For example, a guide to top Azure cloud services details the specific offerings for object storage, block storage, and various managed databases. This foundational knowledge is a prerequisite for effective management.
Networking and Connectivity
If compute is the engine and data is the fuel, networking is the nervous system that interconnects all components, routes traffic, and enforces security boundaries.
- Virtual Private Clouds (VPCs): A logically isolated section of the public cloud. It grants you complete control over your virtual network, including defining private IP address ranges (e.g.,
10.0.0.0/16), creating subnets, configuring route tables, and setting up network gateways. - Load Balancers: Distribute incoming application traffic across multiple targets, such as EC2 instances or containers. This enhances availability and fault tolerance. Application Load Balancers (ALBs) operate at Layer 7, enabling path-based routing, while Network Load Balancers (NLBs) operate at Layer 4 for ultra-high performance.
- DNS (Domain Name System): A globally distributed service that translates human-readable domain names (e.g.,
opsmoon.com) into machine-readable IP addresses. Services like AWS Route 53 or Azure DNS also provide advanced features like health checks and latency-based routing.
Mastering these individual components is the first step toward effective cloud infrastructure management services. At OpsMoon, our expert teams architect, build, and manage these components daily.
Explore our DevOps services to see how we build resilient, high-performance systems.
The Four Pillars of Effective Cloud Management
When wrestling with the complexities of cloud infrastructure management services, the key is to focus efforts on four foundational domains. Think of these as the load-bearing columns that support any stable, efficient, and scalable cloud architecture: Cost Optimization, Security and Compliance, Performance Monitoring, and Automation.
Neglecting any one of these pillars compromises the entire structure. A high-performance application with weak security is a data breach waiting to happen. An automated system that hemorrhages cash due to unoptimized resources is a technical failure. By focusing your technical efforts on these four domains, you can build a balanced and robust cloud strategy that accelerates business objectives, rather than creating technical debt.
Pillar 1: Cost Optimization
Cloud expenditure can escalate uncontrollably without a deliberate, technical strategy. The pay-as-you-go model is a double-edged sword; its flexibility can lead to astronomical bills if not governed by rigorous controls. Effective cost optimization is an active, continuous process of financial engineering (FinOps).
To gain control over cloud spend, you must approach it systematically. It begins with granular visibility and ends with automated enforcement of cost-saving policies.
- Implement a Granular Tagging Strategy: This is non-negotiable. Enforce a mandatory tagging policy for all provisionable resources using identifiers like
project,environment,owner, andcost-center. This data is crucial for allocating costs and identifying waste. Use tools like AWS Cost Explorer to filter and analyze spend by these tags. - Aggressively Right-size Instances: Utilize monitoring data from tools like CloudWatch or Datadog to analyze CPU, memory, and network utilization over a meaningful period (e.g., 2-4 weeks). If a
t3.xlargeinstance consistently shows CPU utilization below 20%, it is a prime candidate for downsizing to at3.mediumort3.large. Automate this analysis where possible. - Leverage Commitment-Based Discounts: For predictable, baseline workloads (e.g., core production servers), shift from on-demand pricing to Reserved Instances (RIs) or Savings Plans. These can reduce compute costs by up to 72% in exchange for a one- or three-year term commitment, significantly lowering your TCO.
For a deeper technical dive, review our guide on effective cloud cost optimization strategies.
Pillar 2: Security and Compliance
In the cloud's shared responsibility model, the security in the cloud is your direct responsibility. A single misconfigured S3 bucket or an overly permissive IAM role can expose your entire infrastructure. Robust security requires a defense-in-depth strategy, embedding controls at every layer of your architecture.
Security cannot be a bolted-on afterthought. It must be codified and integrated into the infrastructure lifecycle, from the initial Terraform plan to daily operations. The objective is to make the secure configuration the default and easiest path for engineers.
Here are critical technical practices for hardening your cloud environment:
- Harden Identity and Access Management (IAM): Adhere strictly to the principle of least privilege. Grant IAM users and roles only the specific permissions required to perform their intended function. For example, a service that only needs to read from an S3 bucket should have a policy allowing
s3:GetObject, nots3:*. Regularly audit permissions with tools like AWS IAM Access Analyzer. - Configure Network Security Groups and Firewalls: Treat your VPC as a zero-trust network. Use security groups (stateful) and network access control lists (NACLs, stateless) to define explicit allow-rules for ingress and egress traffic. By default, deny all traffic and only open specific ports (e.g., 443) from trusted IP sources.
- Automate Compliance Checks: Leverage policy-as-code tools like AWS Config or Azure Policy to translate your compliance requirements into enforceable rules (e.g., "all EBS volumes must be encrypted," "MFA must be enabled for all IAM users with console access"). These tools provide continuous monitoring and can be configured for auto-remediation.
Pillar 3: Performance Monitoring
You cannot optimize what you do not measure. Performance monitoring provides the critical feedback loop required to ensure your applications meet their Service Level Objectives (SLOs) for latency, availability, and user experience. This goes beyond simple uptime checks to tracking granular metrics that reveal the health of your distributed system.
Application Performance Monitoring (APM) tools like Datadog or New Relic are essential. They enable distributed tracing, allowing you to follow a single request as it propagates through microservices, identify slow database queries, and pinpoint performance bottlenecks. Key metrics to monitor (the "Four Golden Signals") include:
- Latency: The time it takes to service a request (e.g., p95, p99).
- Error Rate: The rate of requests that fail.
- Saturation: How "full" a resource is (e.g., CPU utilization, memory pressure).
- Throughput: The number of requests per second (RPS) the system is handling.
Pillar 4: Automation
Automation is the force multiplier that underpins the other three pillars. Manual management of a cloud environment at scale is not just inefficient; it is impossible. It is slow, prone to human error, and unscalable. The solution is comprehensive automation, primarily through Infrastructure as Code (IaC).
Tools like Terraform and AWS CloudFormation allow you to define your entire infrastructure—VPCs, subnets, EC2 instances, IAM policies, security groups—in declarative configuration files. This code becomes the single source of truth for your environment's state, eliminating configuration drift and enabling repeatable, error-free deployments. Automation is what ensures your cost, security, and performance policies are applied consistently with every change.
Choosing Your Cloud Management Solution
Selecting the right management model for your cloud infrastructure is a critical strategic decision that impacts budget, engineering velocity, and scalability. The choice represents a trade-off between control, convenience, and total cost of ownership (TCO). The three primary paths are using native cloud provider tools, implementing a third-party platform, or engaging a managed service provider (MSP).
Each model is suited for different organizational profiles. A small startup might leverage native tools for agility, while a large, regulated enterprise with a multi-cloud footprint will likely require the unified governance provided by a dedicated platform or MSP.
Comparing Your Management Options
To make an informed decision, you must evaluate these options on both technical and business merits. The optimal choice depends on your team's existing skill set, the complexity of your cloud architecture, and your budget for both licensing and operational overhead.
-
Native Cloud Tools (e.g., AWS CloudWatch, Azure Monitor): These are the default services built into each cloud platform. Their primary advantage is deep, seamless integration with other services within that same ecosystem. Their critical weakness is that they operate in a silo, making unified cross-cloud management a significant technical challenge.
-
Third-Party Platforms (e.g., OpsMoon): These platforms are engineered to provide a single pane of glass across multiple cloud environments. They excel at normalizing data and applying consistent policies for monitoring, security, and cost optimization across AWS, Azure, and GCP.
-
Managed Service Providers (MSPs): An MSP acts as an extension of your team, taking on the day-to-day operational burden of managing your infrastructure. This is an effective model for organizations that lack deep in-house cloud expertise or prefer to have their engineering teams focus exclusively on application development.
This infographic breaks down key metrics when comparing an in-house management model with outsourced cloud infrastructure management services.
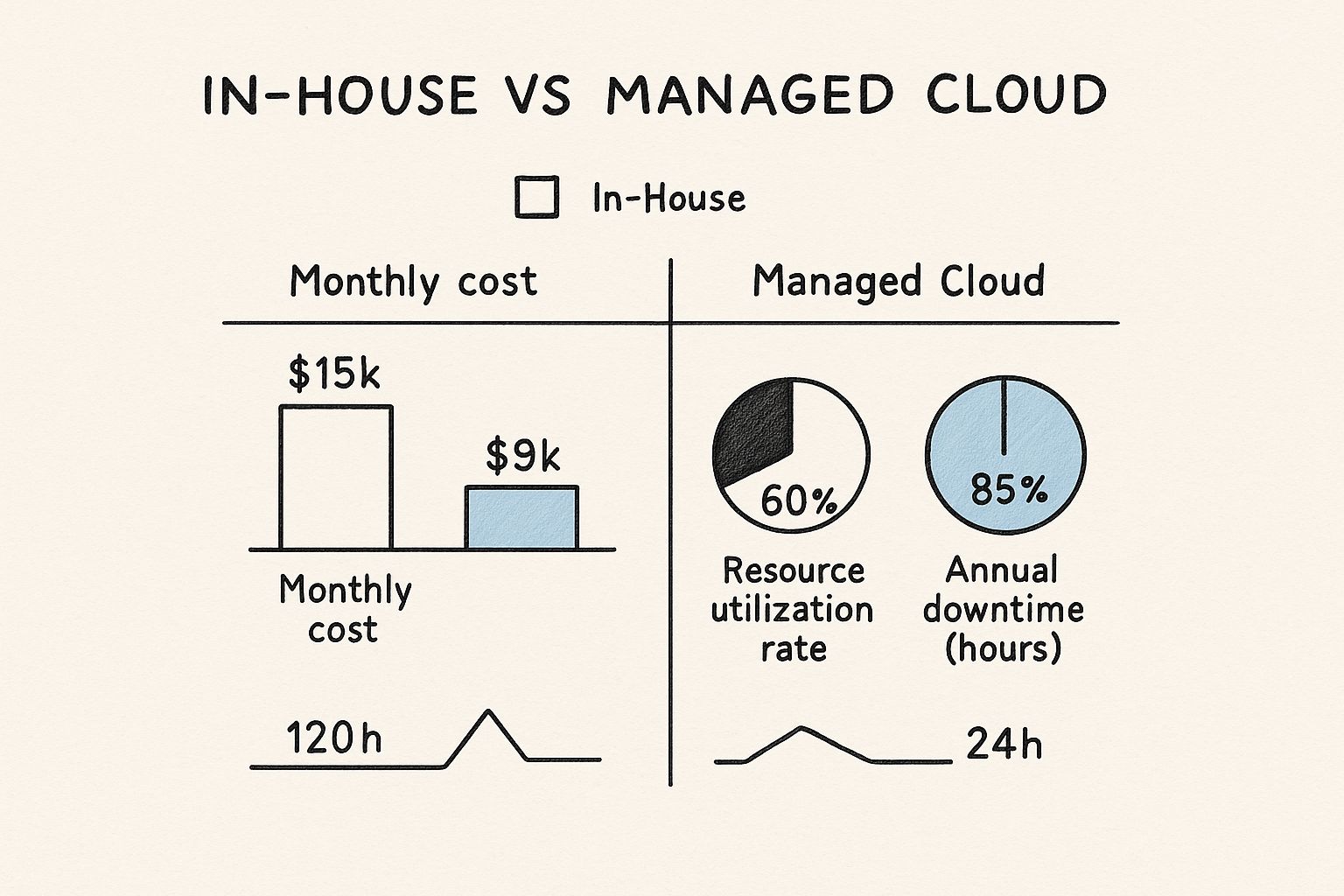
The data highlights a crucial point: while an in-house approach appears direct, it often carries a higher monthly cost due to engineering salaries and tool licensing. Managed services can deliver significant efficiencies, such as a 25% improvement in resource utilization and drastic reductions in downtime through expert 24/7 monitoring and incident response.
Matching the Solution to Your Needs
The final step is to map your specific technical and business requirements to one of these models. There is no universally "best" answer, only the optimal fit for your context.
The most expensive cloud management solution is the one that creates friction for your engineering team or fails to meet your business objectives. A tool with a low subscription fee that requires extensive engineering overhead to operate effectively represents a false economy.
If you’re evaluating your options, use this decision framework:
- For single-cloud startups: Native tools offer the lowest barrier to entry. You can start building immediately without adding another vendor or subscription cost.
- For multi-cloud enterprises: A third-party platform like OpsMoon is a near necessity. It is the only pragmatic way to enforce unified governance, security posture, and cost visibility across disparate cloud providers.
- For teams without deep DevOps/SRE talent: An MSP provides immediate access to the specialized skills required to run a secure, reliable, and cost-effective cloud environment from day one.
To get even more granular, let's evaluate these options against key technical criteria.
Comparison of Cloud Management Approaches
This table evaluates the three main approaches based on the technical criteria that should drive your decision-making process.
| Criteria | Native Cloud Tools (e.g., AWS CloudWatch) | Third-Party Platforms (e.g., OpsMoon) | Managed Service Providers (MSPs) |
|---|---|---|---|
| Multi-Cloud Support | Poor. Results in disparate, inconsistent toolsets and operational silos for each cloud. | Excellent. Purpose-built for unified, cross-cloud visibility and policy enforcement. | Excellent. The provider abstracts away all the cross-cloud complexity and integration challenges. |
| Feature Depth | Variable. Often powerful for the native ecosystem but may lack specialized features for cost or security. | Specialized and deep, with a focus on core management pillars like FinOps, security posture management, and observability. | Depends on the MSP's toolchain, but this is a core competency they have already solved for. |
| Required Expertise | High. Your team needs deep, platform-specific knowledge of each cloud's intricate toolset. | Moderate. Requires learning one platform's interface, not the unique nuances of every cloud provider's tool. | Low. You are purchasing the provider's expertise, freeing your team from needing to acquire it. |
| TCO | Deceptively high. Low direct costs are often overshadowed by significant hidden costs in engineering labor. | Predictable. A clear subscription cost with substantially lower operational overhead. | Highest direct cost, but can lower overall TCO by eliminating the need for specialized hires and reducing waste. |
Ultimately, the best choice is context-dependent. A small team operating solely on AWS has fundamentally different requirements than a global enterprise managing a hybrid, multi-cloud estate. Use this technical breakdown to conduct an honest assessment of your team's capabilities, budget, and strategic priorities.
Using Cloud Management to Accelerate DevOps

Effective cloud infrastructure management services are not just about operational stability; they are a direct catalyst for DevOps maturity. When robust management practices are integrated with agile engineering workflows, your cloud infrastructure transforms from a cost center into a strategic enabler of business velocity.
This represents a shift from a reactive operational posture (firefighting incidents) to a proactive, engineering-driven approach. The goal is to build an infrastructure platform that not only supports but actively accelerates the software development lifecycle, breaking down the traditional silos between development and operations.
From Manual Toil to Automated Pipelines
At its technical core, accelerating DevOps is about eliminating manual work through automation. By defining your entire infrastructure stack using Infrastructure as Code (IaC) tools like Terraform, you eradicate manual provisioning and prevent configuration drift. This ensures that every environment—from local development to production—is an identical, version-controlled entity, which dramatically reduces "it works on my machine" deployment failures.
The real power is unleashed when IaC is integrated into a CI/CD pipeline. A developer commits code, which automatically triggers a pipeline that builds an artifact, provisions a clean, identical test environment using Terraform, runs a suite of automated tests, and, upon success, promotes the change to production. This tight feedback loop between application code and infrastructure code is the hallmark of high-performing engineering organizations.
In a well-managed cloud with automated pipelines, engineers are liberated from the toil of infrastructure firefighting. They no longer spend their sprints manually provisioning servers or troubleshooting environment inconsistencies. Instead, they focus on their primary value-add: writing and shipping code that delivers business value.
The Impact of DevOps Acceleration
The results of this transformation are quantifiable and directly impact key business metrics. Organizations that successfully merge cloud management with DevOps principles see dramatic improvements in DORA metrics.
- Shrinking Deployment Cycles: Fully automated CI/CD pipelines reduce the lead time for changes from weeks to hours, or even minutes.
- Slashing Error Rates: Automated testing in consistent, IaC-defined environments catches bugs earlier in the lifecycle, driving the change failure rate toward zero.
- Boosting System Resilience: Proactive observability provides deep insights into system health, enabling teams to detect and remediate potential issues before they escalate into user-facing outages, thus lowering Mean Time to Recovery (MTTR).
To further streamline development, it's valuable to explore key Agile development best practices, as they align perfectly with this model. If you are new to the methodology, our technical guide on what the DevOps methodology is provides a great foundation.
This level of integration is fueling market growth. The global cloud computing market is projected to expand from $912.77 billion in 2025 to $1.614 trillion by 2030. With 94% of enterprises already using the cloud, elite management and DevOps practices are the key differentiators.
Frequently Asked Questions About Cloud Management
As engineering teams adopt cloud infrastructure, several common technical questions consistently arise. Clear, actionable answers are crucial for making sound architectural and operational decisions.
This section provides direct, technical answers to the most frequent queries we encounter, building on the core principles outlined in this guide.
What Is the Biggest Mistake Companies Make with Cloud Infrastructure?
The single most impactful and costly mistake is treating cost management as an afterthought. Teams, driven by the need for velocity, often provision resources without financial governance, only to be confronted with "bill shock" at the end of the month. This occurs when the cloud is treated like a limitless resource pool instead of a metered service that requires rigorous financial engineering (FinOps).
A proactive cost optimization strategy must be implemented from day one. It is a foundational requirement, not an optional extra. This involves several key technical practices:
- Granular Resource Tagging: Enforce a strict, automated policy (e.g., using SCPs in AWS) that requires every resource to be tagged with its owner, project, and environment. This is the only way to achieve accurate cost attribution.
- Rightsizing Instances: Continuously monitor utilization metrics (CPU, RAM, Network I/O). If an m5.2xlarge instance averages 15% CPU utilization over 14 days, it must be downsized. Automate this analysis and alerting.
- Budget Alerts: Configure programmatic budget alerts (e.g., using AWS Budgets or Azure Cost Management) that trigger notifications or even automated actions (like invoking a Lambda function to shut down dev environments) when spend forecasts exceed a threshold.
Can I Manage a Multi-Cloud Environment with Just Native Tools?
Technically, it is possible. However, from an operational and security standpoint, it is highly inadvisable. It creates immense technical debt and operational risk.
Attempting to manage a multi-cloud estate by duct-taping together native tools like AWS CloudWatch and Azure Monitor forces your operations team to become experts in multiple, disparate ecosystems. Each platform has its own API, data schema, and alerting mechanism. This fragmentation creates observability gaps, hinders root-cause analysis, and makes it impossible to enforce consistent security and governance policies.
For any serious multi-cloud strategy, a dedicated third-party platform or a managed service provider is the superior technical choice. You require a single, unified control plane for observability, security posture management, and cost optimization.
Attempting to manage a multi-cloud setup with native tools is like trying to conduct an orchestra where every musician is reading from different sheet music in a different language. You will produce noise, not a symphony. It will be chaos.
How Does Infrastructure as Code Improve Management?
Infrastructure as Code (IaC) is a paradigm shift in infrastructure management. By using declarative tools like Terraform or AWS CloudFormation, you treat your infrastructure configuration as software. This fundamental change provides three transformative benefits that solve long-standing operational challenges.
- Automation: IaC eliminates manual, error-prone configuration through a CLI or console. Deployments become deterministic, repeatable, and fast, executed through automated CI/CD pipelines.
- Version Control: Storing your Terraform or CloudFormation files in a Git repository provides a full audit trail of every change to your infrastructure. You can use pull requests to review and approve changes, and you can instantly roll back to a previous known-good state if a deployment causes an issue.
- Consistency: IaC is the definitive solution to configuration drift and the "it works on my machine" problem. It guarantees that development, staging, and production environments are provisioned identically, which drastically reduces environment-specific bugs and accelerates troubleshooting.
Ready to accelerate your DevOps maturity and gain full control over your cloud environment? The expert engineers at OpsMoon can build the tailored roadmap you need. Book your free work planning session today and see how our top-tier talent can optimize your infrastructure for speed, security, and cost-efficiency.