Expert Cloud DevOps Consulting for Scalable Growth
 By opsmoon
By opsmoonBoost your business with our cloud devops consulting services. Streamline CI/CD, optimize infrastructure, and accelerate delivery today!
Let's cut through the jargon. Cloud DevOps consulting isn't about buzzwords; it's a strategic partnership to re-engineer how you deliver software. The objective is to merge your development and operations teams into a single, high-velocity engine by applying DevOps principles—automation, tight collaboration, and rapid feedback loops—within a cloud environment like AWS, Azure, or GCP.
It’s about implementing technical practices that make these principles a reality. This guide details the specific technical pillars, engagement models, and implementation roadmaps involved in a successful cloud DevOps transformation.
What Cloud DevOps Consulting Actually Delivers

In a traditional IT model, development and operations function in silos. Developers commit code and "throw it over the wall" to an operations team for deployment. This handoff is a primary source of friction, causing deployment delays, configuration drift, and operational incidents. It's a model that inherently limits velocity and reliability.
A cloud devops consulting engagement dismantles this siloed structure. It re-architects your software delivery lifecycle into an integrated, automated, and observable system. Every step—from a git push to production deployment and monitoring—becomes part of a single, cohesive, and version-controlled process. The goal is to solve business challenges by optimizing technical execution.
Bridging the Gap Between Code and Business Value
A consultant's primary function is to eliminate the latency between a code commit and the delivery of business value. This is achieved by implementing technical solutions that directly address common pain points in the software delivery lifecycle.
For example, a consultant replaces error-prone manual server provisioning with declarative Infrastructure as Code (IaC) templates. Risky, multi-step manual deployments are replaced with idempotent, automated CI/CD pipelines. These technical shifts are fundamental, freeing up engineering resources from low-value maintenance tasks to focus on innovation and feature development.
This is particularly critical for organizations migrating to the cloud. Many teams lift-and-shift their applications but fail to modernize their processes, effectively porting their legacy inefficiencies to a more expensive cloud environment. A cloud migration consultant can establish a DevOps-native operational model from the outset, preventing these anti-patterns before they become entrenched.
More Than Just an IT Upgrade
Ultimately, this is a business transformation enabled by technical excellence. By engineering a more resilient and efficient software delivery system, cloud DevOps consulting produces measurable improvements in key business metrics.
The real objective is to build a system where the "cost of change" is low. This means you can confidently experiment, pivot, and respond to market demands without the fear of breaking your entire production environment. It’s about building both technical and business agility.
This shift delivers distinct competitive advantages:
- Accelerated Time-to-Market: Automated CI/CD pipelines reduce the lead time for changes from weeks or months to hours or even minutes.
- Improved System Reliability: Integrating automated testing (unit, integration, E2E) and proactive monitoring reduces the Change Failure Rate (CFR) and Mean Time to Recovery (MTTR).
- Enhanced Team Collaboration: By adopting shared toolchains (e.g., Git, IaC repos) and processes, development and operations teams align on common goals, improving productivity.
- Scalable and Secure Operations: Using cloud-native architectures and IaC ensures infrastructure can be scaled, replicated, and secured programmatically as business demand grows.
This partnership provides the deep technical expertise and strategic guidance needed to turn your cloud infrastructure into a genuine competitive advantage.
The Technical Pillars of Cloud DevOps Transformation

Effective cloud DevOps is not based on abstract principles but on a set of interconnected technical disciplines. These pillars are the practical framework a cloud devops consulting expert uses to build a high-performance engineering organization. Mastering them is the difference between simply hosting applications on the cloud and leveraging it for strategic advantage.
The foundation rests on three core technical practices: CI/CD automation, Infrastructure as Code (IaC), and continuous monitoring. These elements function as an integrated system to create a self-sustaining feedback loop that accelerates software delivery while improving reliability.
This isn't just theory—it's driving huge market growth. The global DevOps market is expected to hit $15.06 billion, jumping up from $10.46 billion the year before. That's because around 80% of organizations are now using DevOps to ship better software and run more efficiently, proving these pillars are the new standard.
CI/CD Automation: The Engine of Delivery
The core of modern DevOps is a robust Continuous Integration and Continuous Deployment (CI/CD) pipeline. The objective is to replace slow, error-prone manual release processes with an automated workflow that validates and deploys code from a developer's local environment to production. A well-designed pipeline is a series of automated quality gates.
Consider this technical workflow: a developer pushes code to a feature branch in a Git repository. This triggers a webhook that initiates the pipeline:
- Build: The source code is compiled, dependencies are fetched, and the application is packaged into an immutable artifact, such as a Docker container image tagged with the Git commit SHA.
- Test: A suite of automated tests—unit, integration, and static code analysis (SAST)—are executed against the artifact. If any test fails, the pipeline halts, and the developer is notified immediately.
- Deploy: Upon successful testing, the artifact is deployed to a staging environment for further validation (e.g., E2E tests). With a final approval gate (or fully automated), it is then promoted to production using a strategy like blue/green or canary deployment.
Tools like GitLab CI, GitHub Actions, or Jenkins are used to define these workflows in declarative YAML files stored alongside the application code. By codifying the release process, teams eliminate manual errors, increase deployment frequency, and ensure every change is rigorously tested. In fact, providing frictionless, automated pipelines is one of the most effective strategies to improve developer experience.
Infrastructure as Code: Making Environments Reproducible
The second pillar, Infrastructure as Code (IaC), addresses a critical failure point in software development: "environment drift." This occurs when development, staging, and production environments diverge over time due to manual changes, leading to difficult-to-diagnose bugs.
IaC solves this by defining all cloud resources—VPCs, subnets, EC2 instances, security groups, IAM roles—in declarative code files.
Using tools like Terraform or AWS CloudFormation, infrastructure code is stored in a Git repository, making it the single source of truth. Changes are proposed via pull requests, enabling peer review and automated validation before being applied.
With IaC, provisioning an exact replica of the production environment for testing is reduced to running a single command:
terraform apply. This eliminates the "it worked on my machine" problem and makes disaster recovery a predictable, automated process.
The benefits are significant: manual configuration errors are eliminated, infrastructure changes are auditable and version-controlled, and the entire system becomes self-documenting.
Continuous Monitoring and Feedback: Seeing What's Really Happening
The final pillar is continuous monitoring and feedback. You cannot improve what you cannot measure. This practice moves beyond basic server health checks (CPU, memory) to achieve deep observability into system behavior, enabling teams to understand not just that a failure occurred, but why.
This is accomplished by implementing a toolchain to collect and analyze three key data types:
- Metrics: Time-series data from infrastructure and applications (e.g., latency, error rates, request counts), often collected using tools like Prometheus.
- Logs: Structured, timestamped records of events from every component of the system, aggregated into a centralized logging platform.
- Traces: End-to-end representations of a request as it flows through a distributed system, essential for debugging microservices architectures.
Platforms like Datadog or open-source stacks like Prometheus and Grafana are used to visualize this data in dashboards and configure intelligent alerts. This creates a data-driven feedback loop that informs developers about the real-world performance of their code, enabling proactive optimization and rapid incident response.
How to Choose Your Consulting Engagement Model
Engaging a cloud DevOps consultant is not a one-size-fits-all transaction. The engagement model dictates the scope, budget, and level of team integration. Selecting the correct model is critical and depends entirely on your organization's maturity, technical needs, and strategic objectives.
For instance, an early-stage startup needs rapid, hands-on implementation, while a large enterprise may require high-level strategic guidance to align disparate engineering teams. Understanding the differences between models like staff augmentation vs consulting is key to making an informed decision.
Project-Based Engagements
The project-based model is the most straightforward and is ideal for initiatives with a clearly defined scope and a finite endpoint. This is analogous to contracting a specialist for a specific task with a known outcome.
This model is optimal for deliverables such as:
- Implementing a production-grade CI/CD pipeline using GitLab CI or GitHub Actions.
- Migrating a legacy application's infrastructure to a modular Terraform codebase.
- Deploying an initial observability stack using Prometheus and Grafana with pre-configured dashboards and alerting rules.
The deliverables are tangible and contractually defined. The engagement is typically structured as a fixed-scope, fixed-price contract, providing budgetary predictability.
Managed Services
For organizations that require ongoing operational ownership, a managed services model is the appropriate choice. In this model, the consulting firm acts as an extension of your team, assuming responsibility for the day-to-day management, maintenance, and optimization of your cloud DevOps environment.
This is less of a one-time project and more of a long-term operational partnership. A cloud devops consulting firm operating as a managed service provider is responsible for maintaining system uptime, security posture, and cost efficiency.
A key benefit of managed services is proactive optimization. The partner doesn't just respond to alerts; they actively identify opportunities for performance tuning, cost reduction (e.g., through resource rightsizing or Reserved Instance analysis), and security hardening.
This model usually operates on a monthly retainer, making it a good fit for companies without a dedicated in-house SRE or platform engineering team but who require 24/7 operational assurance for their critical systems.
Strategic Advisory
The strategic advisory model is a high-level engagement designed for organizations that have capable engineering teams for execution but need expert guidance on architecture, strategy, and best practices.
The consultant functions as a senior technical advisor or fractional CTO, helping leadership navigate complex decisions:
- What is the optimal CI/CD tooling and workflow for our specific software delivery model?
- How should we structure our Terraform mono-repo to support multiple teams and environments without creating bottlenecks?
- What are the practical steps to foster a DevOps culture and shift security left (DevSecOps)?
Deliverables are strategic artifacts like technical roadmaps, architectural decision records (ADRs), and training for senior engineers. This engagement is almost always priced on an hourly or daily basis, focused on high-impact knowledge transfer.
Comparing Cloud DevOps Consulting Models
Choosing the right engagement model is critical. This table breaks down the common options to help you see which one aligns best with your technical needs, budget, and how much you want your internal team to be involved.
| Service Model | Best For | Typical Deliverables | Pricing Structure |
|---|---|---|---|
| Project-Based | Companies with a specific, time-bound goal like building a CI/CD pipeline or an IaC migration. | A fully functional system, a complete set of IaC modules, a deployed dashboard. | Fixed Scope, Fixed Price |
| Managed Services | Businesses needing ongoing operational support, 24/7 monitoring, and continuous optimization of their systems. | System uptime, performance reports, cost optimization analysis, security audits. | Monthly Retainer/Subscription |
| Strategic Advisory | Organizations that need high-level guidance on technology choices, architecture, and overall DevOps strategy. | Technical roadmaps, architectural diagrams, culture-building workshops, training. | Hourly or Daily Rate |
Each model serves a different purpose. Take a hard look at your immediate needs and long-term goals to decide whether you need a builder, a manager, or a guide.
Your Phased Roadmap to Cloud DevOps Implementation
A successful cloud DevOps transformation is not a single project but a structured, iterative journey. It requires a phased roadmap that delivers incremental value and manages technical complexity. A cloud devops consulting partner acts as the architect of this roadmap, ensuring each phase builds logically on the previous one.
The objective of a phased approach is to avoid a high-risk "big bang" implementation. Instead, you progress through distinct stages, each with specific technical milestones and deliverables. This minimizes disruption, builds organizational momentum, and allows for course correction based on feedback from each stage.
This infographic breaks down the core iterative loop of a DevOps implementation—from evaluation to automation and, finally, to monitoring.
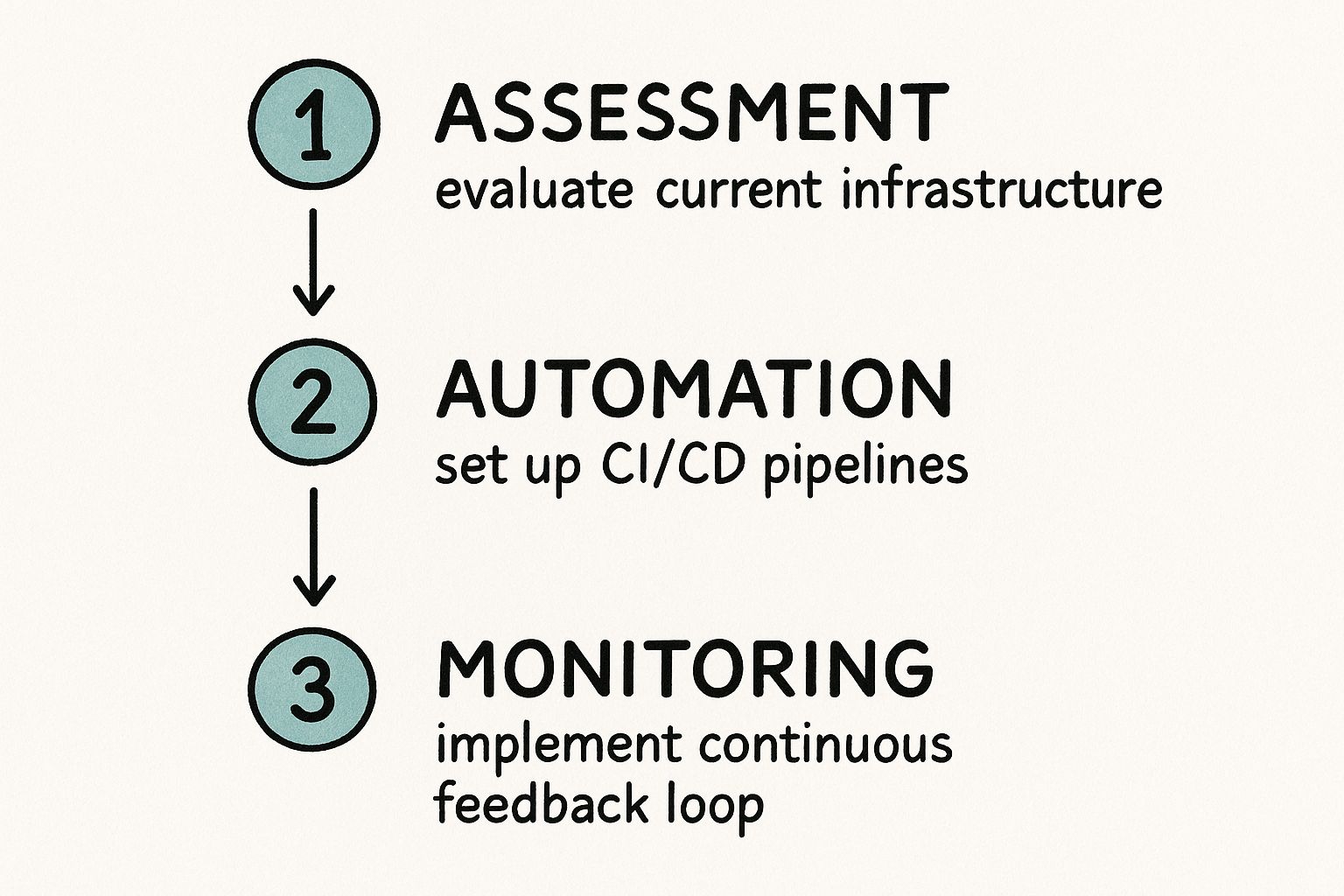
This illustrates that DevOps is a continuous improvement cycle: assess the current state, automate a process, measure the outcome, and repeat.
Phase 1: Assessment and Strategy
The first phase is a comprehensive technical audit of your existing software delivery lifecycle, toolchains, and cloud infrastructure. This is not a superficial review; it's a deep analysis to identify specific bottlenecks, security vulnerabilities, and process inefficiencies.
The primary goal is to establish a quantitative baseline. Key metrics (often referred to as DORA metrics) are measured: Deployment Frequency, Mean Time to Recovery (MTTR), Change Failure Rate, and Lead Time for Changes. This phase also involves mapping your organization against established DevOps maturity levels to identify the most critical areas for improvement and define a strategic roadmap with clear, achievable goals.
Phase 2: Foundational IaC Implementation
With a strategic roadmap in place, the next phase is to establish a solid foundation with Infrastructure as Code (IaC). This phase focuses on eliminating manual infrastructure management, which is a primary source of configuration drift and deployment failures. A consultant will guide the setup of a version control system (e.g., Git) for all infrastructure code.
The core technical work involves using tools like Terraform or AWS CloudFormation to define core infrastructure components—VPCs, subnets, security groups, IAM roles—in a modular and reusable codebase.
By treating your infrastructure as code, you gain the ability to create, destroy, and replicate entire environments with push-button simplicity. This makes your systems predictable, auditable, and version-controlled, forming the bedrock of all future automation efforts.
This foundational step ensures environmental parity between development, staging, and production, definitively solving the "it worked on my machine" problem.
Phase 3: Pilot CI/CD Pipeline Build
With a version-controlled infrastructure foundation, the focus shifts to process automation. This phase involves building the first CI/CD (Continuous Integration/Continuous Deployment) pipeline for a single, well-understood application. This pilot project serves as a proof-of-concept and creates a reusable pattern that can be scaled across the organization.
The technical milestones for this phase are concrete:
- Integrate with Version Control: The pipeline is triggered automatically via webhooks on every
git pushto a specific branch in a repository (e.g., GitHub, GitLab). - Automate Builds and Tests: The pipeline automates the compilation of code, the creation of immutable artifacts (e.g., Docker images), and the execution of a comprehensive test suite (unit, integration).
- Implement Security Scans: Static Application Security Testing (SAST) and software composition analysis (SCA) tools are integrated directly into the pipeline to identify vulnerabilities before deployment.
Phase 4: Observability and Optimization
Once an application is being deployed automatically, the fourth phase focuses on implementing robust monitoring and feedback mechanisms. You cannot manage what you don't measure. This stage involves deploying an observability stack using tools like Prometheus, Grafana, or Datadog to gain deep visibility into application performance and infrastructure health.
This goes beyond basic resource monitoring. A complete observability solution collects and correlates metrics, logs, and traces to provide a holistic view of system behavior. This data feeds back into the development process, enabling engineers to see the performance impact of their code and allowing operations teams to move from reactive firefighting to proactive optimization.
Phase 5: Scaling and DevSecOps
With a validated and successful pilot, the final phase is about scaling the established patterns across the organization. The proven IaC modules and CI/CD pipeline templates are adapted and rolled out to other applications and teams. This is a deliberate expansion, governed by internal standards to ensure consistency and maintain best practices.
A critical component of this phase is shifting security further left in the development lifecycle, a practice known as DevSecOps. As noted by 78% of IT professionals, DevSecOps is now a key strategic priority. This involves integrating more sophisticated security tooling (e.g., Dynamic Application Security Testing or DAST), automating compliance checks, and embedding security expertise within development teams to build a security-first engineering culture.
The Modern Cloud DevOps Technology Stack
A strong DevOps culture is only as good as the tools that support it. Think of your technology stack not as a random shopping list of popular software, but as a carefully integrated ecosystem where every piece has a purpose. A cloud DevOps consulting expert's job is to help you assemble this puzzle, making sure each component works together to create a smooth, automated path from code to customer.
This stack is the engine that brings your DevOps principles to life. It's what turns abstract ideas like "automation" and "feedback loops" into real, repeatable actions. Each layer builds on the last, from the raw cloud infrastructure at the bottom to the observability tools at the top that tell you exactly what’s going on.
Cloud Platforms and Native Services
The foundation of the stack is the cloud platform itself. The "big three"—Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP)—dominate the market. These platforms offer far more than just IaaS; they provide a rich ecosystem of managed services designed to accelerate DevOps adoption.
For example, an organization heavily invested in AWS can leverage native services like AWS CodePipeline for CI/CD, AWS CodeCommit for source control, and Amazon CloudWatch for observability. An Azure-centric enterprise might use Azure DevOps as a fully integrated suite. Leveraging these native services can reduce integration complexity and operational overhead.
Containerization and Orchestration
The next layer enables application portability and scalability: containerization. Docker has become the industry standard for packaging an application and its dependencies into a lightweight, immutable artifact. This ensures that an application runs identically across all environments.
Managing a large number of containers requires an orchestration platform. Kubernetes (K8s) has emerged as the de facto standard for container orchestration, automating the deployment, scaling, and lifecycle management of containerized applications. It provides a robust, API-driven platform for running distributed systems at scale.
This image from the official Kubernetes site captures its core promise: taking the manual pain out of managing containers at scale.

With Kubernetes, teams define the desired state of their applications declaratively using YAML manifests, and the Kubernetes control plane works to maintain that state, handling tasks like scheduling, health checking, and auto-scaling.
Infrastructure as Code Tools
Manually configuring cloud infrastructure via a web console is slow, error-prone, and not scalable. Infrastructure as Code (IaC) solves this by defining infrastructure in version-controlled code. This makes infrastructure provisioning a repeatable, predictable, and auditable process.
Terraform is the dominant tool in this space due to its cloud-agnostic nature, allowing teams to manage resources across AWS, Azure, and GCP using a consistent workflow. For single-cloud environments, native tools like AWS CloudFormation provide deep integration with platform-specific services. To learn more, explore this comparison of cloud infrastructure automation tools.
CI/CD and Observability Platforms
The CI/CD pipeline is the automation engine of DevOps. It orchestrates the process of building, testing, and deploying code changes. Leading tools in this category include GitLab, which offers a single application for the entire DevOps lifecycle; GitHub Actions, which is tightly integrated with the GitHub platform; and the highly extensible Jenkins.
Once deployed, applications must be monitored. An observability suite provides the necessary visibility into system health and performance.
Observability goes beyond traditional monitoring. It's about having a system so transparent that you can ask it any question about its state and get an answer, even if you didn't know you needed to ask it beforehand. It’s crucial for quick troubleshooting and constant improvement.
A typical observability stack includes:
- Prometheus: For collecting time-series metrics from applications and infrastructure.
- Grafana: For visualizing metrics and creating interactive dashboards.
- Datadog: A commercial, all-in-one platform for metrics, logs, and application performance monitoring (APM).
The business world is taking notice. The global DevOps platform market, currently valued around $16.97 billion, is projected to explode to $103.21 billion by 2034. This massive growth shows just how essential a well-oiled technology stack has become.
How to Select the Right Cloud DevOps Partner
Selecting the right consulting partner is one of the most critical decisions in a DevOps transformation. A poor choice can lead to failed projects and wasted budgets. This checklist provides a framework for evaluating potential partners to ensure they have the technical depth and strategic mindset to succeed.
An effective partner acts as a force multiplier, augmenting your team's capabilities and leaving them more self-sufficient. Your selection process must therefore be rigorous, focusing on proven expertise, a tool-agnostic philosophy, and a clear knowledge transfer strategy.
Evaluate Deep Technical Expertise
First, verify the partner's technical depth. A superficial understanding of cloud services is insufficient for designing and implementing resilient, scalable production systems. A strong indicator of expertise is advanced industry certifications, which validate a baseline of technical competency.
Look for key credentials such as:
- AWS Certified DevOps Engineer – Professional: Demonstrates expertise in provisioning, operating, and managing distributed application systems on the AWS platform.
- Certified Kubernetes Administrator (CKA): Validates the skills required to perform the responsibilities of a Kubernetes administrator in a production environment.
- HashiCorp Certified Terraform Associate: Confirms a practitioner's understanding of Infrastructure as Code (IaC) concepts and core skills with Terraform.
Certifications are a starting point. Request technical case studies relevant to your industry and specific challenges. Ask for concrete examples of CI/CD pipeline architectures, complex IaC modules they have authored, or observability dashboards they have designed.
Assess Their Approach to Tooling and Culture
This is a critical, often overlooked, evaluation criterion. A consultant's philosophy on technology is revealing. A tool-agnostic partner will recommend solutions based on your specific requirements, not on pre-existing vendor partnerships. This ensures their recommendations are unbiased and technically sound.
The right cloud DevOps consulting partner understands that tools are just a means to an end. Their primary focus should be on improving your processes and empowering your people, with technology serving those goals—not the other way around.
Equally important is their collaboration model. A consultant should integrate seamlessly with your team, acting as a mentor and guide. Ask direct questions about their knowledge transfer process. A strong partner will have a formal plan that includes detailed documentation, pair programming sessions, and hands-on training workshops to ensure your team can operate and evolve the systems they build long after the engagement ends.
Frequently Asked Questions About Cloud DevOps
Even with a solid plan, a few questions always pop up when people start thinking about bringing in a cloud devops consulting partner. Let's tackle some of the most common ones head-on.
How Is The ROI of a DevOps Engagement Measured?
This is a great question, and the answer goes way beyond just looking at cost savings. The real return on investment (ROI) from DevOps comes from tracking specific technical improvements and seeing how they impact the business. A good consultant will help you benchmark these metrics—often called DORA metrics—before any work begins.
Here are the four big ones to watch:
- Deployment Frequency: How often are you pushing code to production? More frequent deployments mean you're delivering value to customers faster.
- Mean Time to Recovery (MTTR): When something breaks in production, how long does it take to fix it? A lower MTTR means your system is more resilient.
- Change Failure Rate: What percentage of your deployments cause problems? A lower rate is a clear sign of higher quality and stability.
- Lead Time for Changes: How long does it take for a code change to go from a developer's keyboard to running in production?
When you see these numbers moving in the right direction, it directly translates to real business value, like lower operating costs and a much quicker time-to-market.
What Is The Difference Between DevOps and SRE?
This one causes a lot of confusion. The easiest way to think about it is that DevOps is the philosophy, and Site Reliability Engineering (SRE) is a specific way to implement it.
DevOps is the broad cultural framework. It's all about breaking down the walls between development and operations teams to improve collaboration and speed. It gives you the "what" and the "why."
SRE, on the other hand, is a very prescriptive engineering discipline that grew out of Google. It's how they do DevOps. SRE takes those philosophical ideas and applies them with a heavy emphasis on data, using tools like Service Level Objectives (SLOs) and error budgets to make concrete, data-driven decisions about reliability.
In short, DevOps is the overarching philosophy of collaboration and automation. SRE is a specific engineering discipline that applies that philosophy with a heavy focus on data, reliability, and scalability.
Is It Possible To Implement DevOps Without The Cloud?
Technically? Yes, you can. The core principles of DevOps—automation, collaboration, fast feedback loops—aren't tied to any specific platform. You can absolutely set up CI/CD pipelines and foster a collaborative culture inside your own on-premise data center.
However, the cloud is a massive accelerator for DevOps.
Public cloud providers give you elasticity on demand, powerful automation APIs, and a huge ecosystem of managed services that just make implementing DevOps infinitely easier and more effective. For most companies, trying to do DevOps without the cloud is like choosing to run a marathon with weights on your ankles. You're leaving the most powerful advantages on the table.
Ready to measure your DevOps ROI and accelerate your cloud journey? OpsMoon provides the expert guidance and top-tier engineering talent to make it happen. Start with a free work planning session to map out your technical roadmap.