A Technical Guide to Cloud Computing Cost Reduction
 By opsmoon
By opsmoonA practical guide to cloud computing cost reduction. Implement proven strategies with FinOps, automation, and AI to cut waste and maximize your cloud ROI.
Slashing cloud costs isn't about hitting a budget number; it's about maximizing the value of every dollar spent. This requires engineering teams to own the financial impact of their architectural decisions, embedding cost as a core, non-functional requirement.
This is a cultural shift away from reactive financial reviews. We are moving to a model of proactive cost intelligence built directly into the software development lifecycle (SDLC), where cost implications are evaluated at the pull request stage, not on the monthly invoice.
Moving Beyond Budgets to Cloud Cost Intelligence
Your cloud bill is a direct reflection of your operational efficiency. For many organizations, a rising AWS or GCP invoice isn't a sign of healthy growth but a symptom of technical debt and architectural inefficiencies.
Consider this common scenario: a fast-growing SaaS company's monthly AWS spend jumps 40% with no corresponding user growth. The root cause? A poorly designed microservice for image processing was creating and orphaning multi-gigabyte temporary storage volumes with every transaction. The charges compounded silently, a direct result of an architectural oversight.
This pattern is endemic and points to a critical gap: the absence of cost intelligence. Without granular visibility and engineering accountability, minor technical oversights snowball into significant financial liabilities.
The Power Couple: FinOps and DevOps
To effectively manage cloud expenditure, the organizational silos between finance and engineering must be dismantled. This is the core principle of FinOps, a cultural practice that injects financial accountability into the elastic, pay-as-you-go cloud model.
Integrating FinOps with a mature DevOps culture creates a powerful synergy:
- DevOps optimizes for velocity, automation, and reliability.
- FinOps integrates cost as a first-class metric, on par with latency, uptime, and security.
This fusion creates a culture where engineers are empowered to make cost-aware decisions as a standard part of their workflow. It's a proactive strategy of waste prevention, transforming cost management from a monthly financial audit into a continuous, shared engineering responsibility.
The objective is to shift the dialogue from "How much did we spend?" to "What is the unit cost of our business metrics, and are we optimizing our architecture for value?" This reframes the problem from simple cost-cutting to genuine value engineering.
The data is stark. The global cloud market is projected to reach $723.4 billion by 2025, yet an estimated 32% of this spend is wasted. The primary technical culprits are idle resources (66%) and overprovisioned compute capacity (59%).
These are precisely the issues that proactive cost intelligence is designed to eliminate. For a deeper dive into these statistics, explore resources on cloud cost optimization best practices.
This guide provides specific, technical solutions for the most common sources of cloud waste. The following table outlines the problems and the engineering-led solutions we will detail.
Common Cloud Waste vs. Strategic Solutions
The table below provides a quick overview of the most common sources of unnecessary cloud spend and the high-level strategic solutions that address them, which we'll detail throughout this article.
| Source of Waste | Technical Solution | Business Impact |
|---|---|---|
| Idle Resources | Automated Lambda/Cloud Functions triggered on a cron schedule to detect and terminate unattached EBS/EIPs, old snapshots, and unused load balancers. | Immediate opex reduction by eliminating payment for zero-value assets without impacting production workloads. |
| Overprovisioning | Implement rightsizing automation using performance metrics (e.g., CPU, memory, network I/O) from monitoring tools and execute changes via Infrastructure as Code (IaC). | Improved performance-to-cost ratio by aligning resource allocation with actual demand, eliminating payment for unused capacity. |
| Inefficient Architecture | Refactor monolithic services to serverless functions for event-driven tasks; leverage Spot/Preemptible instances with graceful shutdown handling for batch processing. | Drastically lower compute costs for specific workload patterns and improve architectural scalability and resilience. |
By addressing these core technical issues, you build a more efficient, resilient, and financially sustainable cloud infrastructure. Let's dive into the implementation details.
Weaving FinOps Into Your Engineering Culture
Effective cloud computing cost reduction is not achieved through tools alone; it requires a fundamental shift in engineering culture. The goal is to evolve from the reactive, end-of-month financial review to a proactive, continuous optimization mindset.
This means elevating cloud cost to a primary engineering metric, alongside latency, availability, and error rates. This is the essence of FinOps: empowering every engineer to become a stakeholder in the platform's financial efficiency. When this is achieved, the cost of a new feature is considered from the initial design phase, not as a financial post-mortem.
Fostering Cross-Functional Collaboration
Break down the silos between engineering, finance, and operations. High-performing organizations establish dedicated, cross-functional teams—often called "cost squads" or "FinOps guilds"—comprised of engineers, finance analysts, and product managers. Their mandate is not merely to cut costs but to optimize the business value derived from every dollar of cloud spend.
This approach yields tangible results. A SaaS company struggling with unpredictable billing formed a cost squad and replaced the monolithic monthly bill with value-driven KPIs that resonated across the business:
- Cost Per Active User (CPAU): Directly correlated infrastructure spend to user growth, providing a clear measure of scaling efficiency.
- Cost Per API Transaction: Pinpointed expensive API endpoints, enabling targeted optimization efforts for maximum impact.
- Cost Per Feature Deployment: Linked development velocity to its financial footprint, incentivizing the optimization of CI/CD pipelines and resource consumption.
Making Cost Tangible for Developers
An abstract, multi-million-dollar cloud bill is meaningless to a developer focused on a single microservice. To achieve buy-in, cost data must be contextualized and made actionable at the individual contributor level.
Conduct cost-awareness workshops that translate cloud services into real-world financial figures. Demonstrate the cost differential between t3.micro and m5.large instances, or the compounding expense of inter-AZ data transfer fees at scale. The objective is to illustrate how seemingly minor architectural decisions have significant, long-term financial consequences.
The real breakthrough occurs when cost feedback is integrated directly into the developer workflow. Imagine a CI/CD pipeline where a pull request triggers not only unit and integration tests but also an infrastructure cost estimation using tools like Infracost. The estimated cost delta becomes a required field for PR approval, making cost a tangible, immediate part of the engineering process.
This tight integration of financial governance and DevOps is highly effective. A 2024 Deloitte analysis projects that FinOps adoption could save companies a collective $21 billion in 2025, with some organizations reducing cloud costs by as much as 40%. You can learn more about how FinOps tools are lowering cloud spending and see the potential impact.
Driving Accountability with Alerts and Gamification
Once a baseline of awareness is established, implement accountability mechanisms. Configure actionable budget alerts that trigger automated responses, not just email notifications. A cost anomaly should automatically open a Jira ticket assigned to the responsible team or post a detailed alert to a specific Slack channel with a link to the relevant cost dashboard. This ensures immediate investigation by the team with the most context.
For advanced engagement, introduce gamification. Develop dashboards that publicly track and celebrate the most cost-efficient teams or highlight individuals who identify significant savings. Run internal "cost optimization hackathons" with prizes for the most innovative and impactful solutions. This transforms cost management from a mandate into a competitive engineering challenge, embedding the FinOps mindset into your team's DNA.
Hands-On Guide to Automating Resource Management
Theoretical frameworks are important, but tangible cloud computing cost reduction is achieved through automation embedded in daily operations. Manual cleanups are inefficient and temporary. Automation builds a self-healing system that prevents waste from accumulating.
This section shifts from strategy to execution, providing specific, technical methods for automating resource management and eliminating payment for idle infrastructure.
Proactive Prevention with Infrastructure as Code
The most effective cost control is preventing overprovisioning at the source. This is a core strength of Infrastructure as Code (IaC) tools like Terraform. By defining infrastructure in code, you can enforce cost-control policies within your version-controlled development workflow.
For example, create a standardized Terraform module for deploying EC2 instances that only permits instance types from a predefined, cost-effective list. You can enforce this using validation blocks in your variable definitions:
variable "instance_type" {
type = string
description = "The EC2 instance type."
validation {
condition = can(regex("^(t3|t4g|m5|c5)\\.(micro|small|medium|large)$", var.instance_type))
error_message = "Only approved instance types (t3, t4g, m5, c5 in smaller sizes) are allowed."
}
}
If a developer attempts to deploy a m5.24xlarge for a development environment, the terraform plan command will fail, preventing the costly mistake before it occurs. If your team is new to this, a good https://opsmoon.com/blog/terraform-tutorial-for-beginners can help build these foundational guardrails.
By codifying infrastructure, you shift cost control from a reactive, manual cleanup to a proactive, automated governance process. Financial discipline becomes an inherent part of the deployment pipeline.
Automating the Cleanup of Idle Resources
Despite guardrails, resource sprawl is inevitable. Development environments are abandoned, projects are de-prioritized, and resources are left running. Manually hunting for these "zombie" assets is slow, error-prone, and unscalable.
Automation using cloud provider CLIs and SDKs is the only viable solution. You can write scripts to systematically identify and manage this waste.
Here are specific commands to find common idle resources:
- Find Unattached AWS EBS Volumes:
aws ec2 describe-volumes --filters Name=status,Values=available --query "Volumes[*].{ID:VolumeId,Size:Size,CreateTime:CreateTime}" --output table - Identify Old Azure Snapshots (PowerShell):
Get-AzSnapshot | Where-Object { $_.TimeCreated -lt (Get-Date).AddDays(-90) } | Select-Object Name,ResourceGroupName,TimeCreated - Locate Unused GCP Static IPs:
gcloud compute addresses list --filter="status=RESERVED AND purpose!=DNS_RESOLVER" --format="table(name,address,region,status)"
Your automation workflow should not immediately delete these resources. A safer, two-step process is recommended:
- Tagging: Run a daily script that finds idle resources and applies a tag like
deletion-candidate-date:YYYY-MM-DD. - Termination: Run a weekly script that terminates any resource with a tag older than a predefined grace period (e.g., 14 days). This provides a window for teams to reclaim resources if necessary. Integrating Top AI Workflow Automation Tools can enhance these scripts with more complex logic and reporting.
The contrast between manual and automated approaches highlights the necessity of the latter for sustainable cost management.
Manual vs. Automated Rightsizing Comparison
| Aspect | Manual Rightsizing | Automated Rightsizing |
|---|---|---|
| Process | Ad-hoc, reactive, often triggered by budget overruns. Relies on an engineer manually reviewing CloudWatch/Azure Monitor metrics and applying changes via the console. | Continuous, proactive, and policy-driven. Rules are defined in code (e.g., Lambda functions, IaC) and executed automatically based on real-time monitoring data. |
| Accuracy | Prone to human error and biased by short-term data analysis (e.g., observing a 24-hour window misses weekly or monthly cycles). | Data-driven decisions based on long-term performance telemetry (e.g., P95, P99 metrics over 30 days). Highly accurate and consistent. |
| Speed & Scale | Extremely slow and unscalable. A single engineer can only analyze and modify a handful of instances per day. Impossible for fleets of hundreds or thousands. | Instantaneous and infinitely scalable. Can manage thousands of resources concurrently without human intervention. |
| Risk | High risk of under-provisioning, causing performance degradation, or over-correction, leaving performance on the table. | Low risk. Automation includes safety checks (e.g., respect "do-not-resize" tags), adherence to maintenance windows, and gradual, canary-style rollouts. |
| Outcome | Temporary cost savings. Resource drift and waste inevitably return as soon as manual oversight ceases. | Permanent, sustained cost optimization. The system is self-healing and continuously enforces financial discipline. |
Manual effort provides a temporary fix, while a well-architected automated system creates a permanent solution that enforces financial discipline across the entire infrastructure.
Implementing Event-Driven Autoscaling and Rightsizing
Basic autoscaling, often triggered by average CPU utilization, is frequently too slow or irrelevant for modern, I/O-bound, or memory-bound applications. A more intelligent and cost-effective approach is event-driven automation.
This involves triggering actions based on specific business events or a combination of granular performance metrics. A powerful pattern is invoking an AWS Lambda function from a custom CloudWatch alarm.
This flow chart illustrates the concept: a system monitors specific thresholds, scales out to meet demand, and, critically, scales back in aggressively to minimize cost during idle periods.
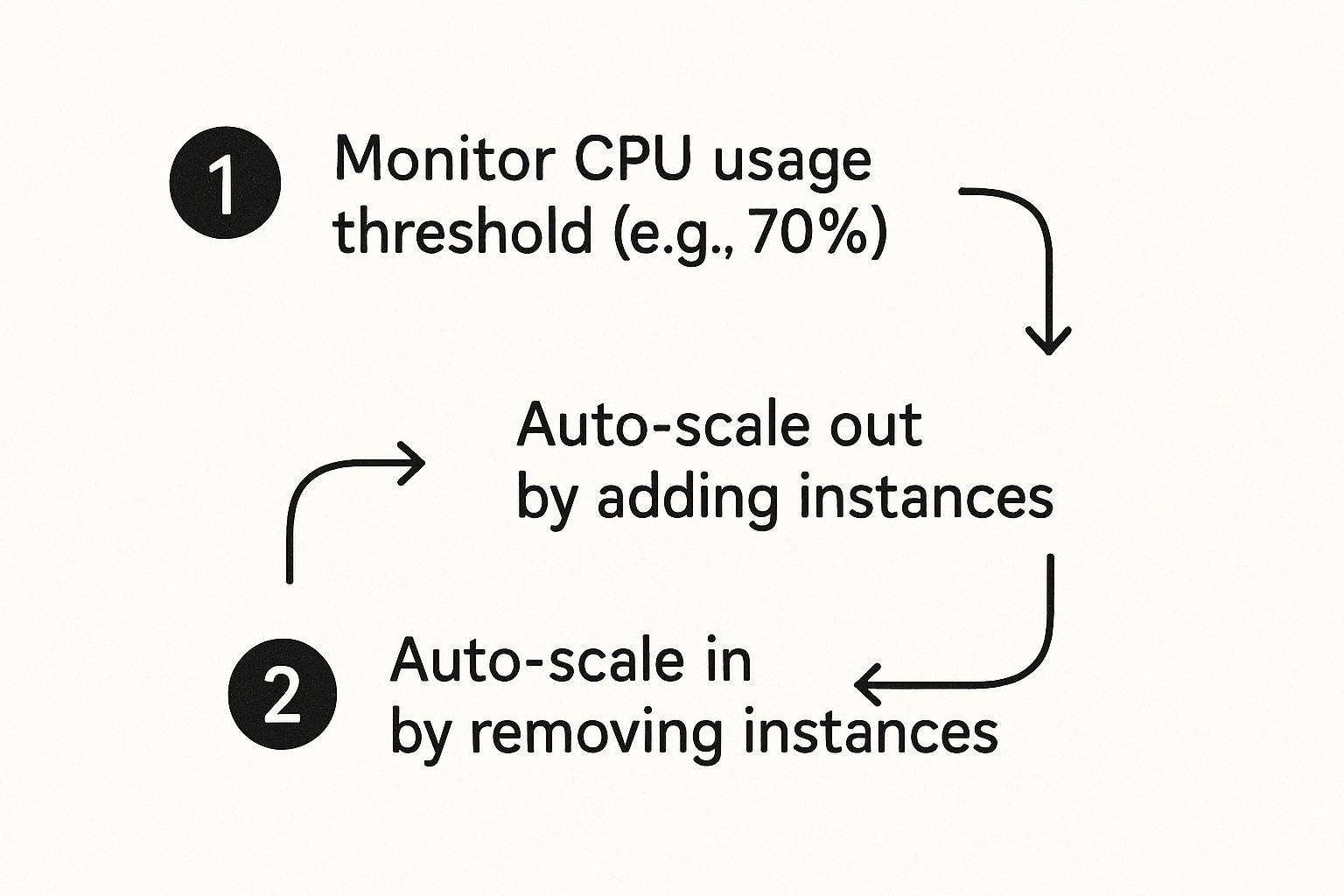
Consider a real-world scenario where an application's performance is memory-constrained. You can publish custom memory utilization metrics to CloudWatch and create an alarm that fires when an EC2 instance's memory usage exceeds 85% for a sustained period (e.g., ten minutes).
This alarm triggers a Lambda function that executes a sophisticated, safety-conscious workflow:
- Context Check: The function first queries the instance's tags. Does it have a
do-not-touch: trueorcritical-workload: prod-dbtag? If so, it logs the event and exits, preventing catastrophic changes. - Maintenance Window Verification: It checks if the current time falls within a pre-approved maintenance window. If not, it queues the action for later execution.
- Intelligent Action: If all safety checks pass, the function can perform a rightsizing operation. It could analyze recent performance data to select a more appropriate memory-optimized instance type and trigger a blue/green deployment or instance replacement during the approved window.
This event-driven, programmatic approach ensures your cloud computing cost reduction efforts are both aggressive in optimizing costs and conservative in protecting production stability.
Tapping Into AI and Modern Architectures for Deeper Savings
Once foundational automation is in place, the next frontier for cost reduction lies in predictive systems and architectural modernization. AI and modern design patterns are powerful levers for achieving efficiencies unattainable through simple rightsizing.
AI plays a dual role: while training large models can be a significant cost driver, applying AI to infrastructure management unlocks profound savings. It enables a shift from reactive to predictive resource scaling—a game-changer for cost control. This is not a future concept; projections show that AI-driven tools are already enabling predictive analytics that can reduce cloud waste by up to 30%.
Predictive Autoscaling with AI
Traditional autoscaling is fundamentally reactive. It relies on lagging indicators like average CPU utilization, waiting for a threshold to be breached before initiating a scaling action. This latency often results in either performance degradation during scale-up delays or wasteful overprovisioning to maintain a "hot" buffer.
AI-powered predictive autoscaling inverts this model. By analyzing historical time-series data of key metrics (traffic, transaction volume, queue depth) and correlating it with business cycles (daily peaks, marketing campaigns, seasonal events), machine learning models can forecast demand spikes before they occur. This allows for precise, just-in-time capacity management.
For an e-commerce platform approaching a major sales event, an AI model could:
- Pre-warm instances minutes before the anticipated traffic surge, eliminating cold-start latency.
- Scale down capacity during predicted lulls with high confidence, maximizing savings.
- Identify anomalous traffic that deviates from the predictive model, serving as an early warning system for DDoS attacks or application bugs.
This approach transforms the spiky, inefficient resource utilization typical of reactive scaling into a smooth curve that closely tracks actual demand. You pay only for the capacity you need, precisely when you need it. Exploring the best cloud cost optimization tools can provide insight into platforms already incorporating these AI features.
Shifting Your Architecture to the Edge
Architectural decisions have a direct and significant impact on cloud spend, particularly concerning data transfer costs. Data egress fees—the cost of moving data out of a cloud provider's network—are a notorious and often overlooked source of runaway expenditure.
Adopting an edge computing model is a powerful architectural strategy to mitigate these costs.
Consider an IoT application with thousands of sensors streaming raw telemetry to a central cloud region for processing. The constant data stream incurs massive egress charges. By deploying compute resources (e.g., AWS IoT Greengrass, Azure IoT Edge) at or near the data source, the architecture can be optimized:
- Data is pre-processed and filtered at the edge.
- Only aggregated summaries or critical event alerts are transmitted to the central cloud.
- High-volume raw data is either discarded or stored locally, dramatically reducing data transfer volumes and associated costs.
This architectural shift not only slashes egress fees but also improves application latency and responsiveness by processing data closer to the end-user or device.
The core principle is technically sound and financially effective: Move compute to the data, not data to the compute. This fundamentally alters the cost structure of data-intensive applications.
How "Green Cloud" Hits Your Bottom Line
The growing focus on sustainability in cloud computing, or "Green Cloud," offers a direct path to financial savings. A cloud provider's energy consumption is a significant operational cost, which is passed on to you through service pricing. Architecting for energy efficiency is synonymous with architecting for cost efficiency.
Choosing cloud regions powered predominantly by renewable energy can lead to lower service costs due to the provider's more stable and lower energy expenses.
More technically, you can implement "load shifting" for non-critical, computationally intensive workloads like batch processing or model training. Schedule these jobs to run during off-peak hours when energy demand is lower. Cloud providers often offer cheaper compute capacity during these times via mechanisms like Spot Instances. By aligning your compute-intensive tasks with periods of lower energy cost and demand, you directly reduce your expenditure. Having the right expertise is crucial for this; hiring Kubernetes and Docker engineers with experience in scheduling and workload management is a key step.
Mastering Strategic Purchasing and Multi-Cloud Finance
Automating resource management yields significant technical wins, but long-term cost optimization is achieved through strategic financial engineering. This involves moving beyond reactive cleanups to proactively managing compute purchasing and navigating the complexities of multi-cloud finance.
Treat your cloud spend not as a utility bill but as a portfolio of financial instruments that requires active, intelligent management.
The Blended Strategy for Compute Purchasing
Relying solely on on-demand pricing is a significant financial misstep for any workload with predictable usage patterns. A sophisticated approach involves building a blended portfolio of purchasing options—Reserved Instances (RIs), Savings Plans, and Spot Instances—to match the financial commitment to the workload's technical requirements.
A practical blended purchasing strategy includes:
- Savings Plans for Your Baseline: Cover your stable, predictable compute baseline with Compute Savings Plans. This is the minimum capacity you know you'll need running 24/7. They offer substantial discounts (up to 72%) and provide flexibility across instance families, sizes, and regions, making them ideal for your core application servers.
- Reserved Instances for Ultra-Stable Workloads: For workloads with zero variability—such as a production database running on a specific instance type for the next three years—a Standard RI can sometimes offer a slightly deeper discount than a Savings Plan. Use them surgically for these highly specific, locked-in scenarios.
- Spot Instances for Interruptible Jobs: For non-critical, fault-tolerant workloads like batch processing, CI/CD builds, or data analytics jobs, Spot Instances are essential. They offer discounts of up to 90% off on-demand prices. The technical requirement is that your application must be architected to handle interruptions gracefully, checkpointing state and resuming work on a new instance.
This blended model is highly effective because it aligns your financial commitment with the workload's stability and criticality, maximizing discounts on predictable capacity while leveraging massive savings for ephemeral, non-critical tasks.
Navigating the Multi-Cloud Financial Maze
Adopting a multi-cloud strategy to avoid vendor lock-in and leverage best-of-breed services introduces significant financial management complexity. Achieving effective cloud computing cost reduction in a multi-cloud environment requires disciplined, unified governance.
When managing AWS, Azure, and GCP concurrently, visibility and workload portability are paramount. Containerize applications using Docker and orchestrate them with Kubernetes to abstract them from the underlying cloud infrastructure. This technical decision enables workload mobility, allowing you to shift applications between cloud providers to capitalize on pricing advantages without costly re-architecting.
For those starting this journey, our guide on foundational cloud cost optimization strategies provides essential knowledge for both single and multi-cloud environments.
Unifying Governance Across Clouds
Fragmented financial governance in a multi-cloud setup guarantees waste. The solution is to standardize policies and enforce them universally.
Begin with a mandatory, universal tagging policy. Define a schema with required tags (project, team, environment, cost-center) and enforce it across all providers using policy-as-code tools like Open Policy Agent (OPA) or native services like AWS Service Control Policies (SCPs). This provides a unified lens through which to analyze your entire multi-cloud spend.
A third-party cloud cost management platform is often a critical investment. These tools ingest billing data from all providers into a single, normalized dashboard. This unified view helps identify arbitrage opportunities—for example, you might discover that network-attached storage is significantly cheaper on GCP than AWS for a particular workload. This insight allows you to strategically shift workloads and realize direct savings, turning multi-cloud complexity from a liability into a strategic advantage. Knowing the specifics of provider offerings, like a Microsoft Cloud Solution, is invaluable for making these informed, data-driven decisions.
Burning Questions About Cloud Cost Reduction
As you delve into the technical and financial details of cloud cost management, specific, practical questions inevitably arise. Here are the most common ones, with technically-grounded answers.
Where Should My Team Even Start?
Your first action must be to achieve 100% visibility. You cannot optimize what you cannot measure. Before implementing any changes, you must establish a detailed understanding of your current expenditure.
This begins with implementing and enforcing a comprehensive tagging strategy. Every provisioned resource—from a VM to a storage bucket—must be tagged with metadata identifying its owner, project, environment, and application. Once this is in place, leverage native tools like AWS Cost Explorer or Azure Cost Management + Billing to analyze spend. This data-driven approach will immediately highlight your largest cost centers and the most egregious sources of waste, providing a clear, prioritized roadmap for optimization.
How Do I Get Developers to Actually Care About Costs?
Frame cost optimization as a challenging engineering problem, not a budgetary constraint. A multi-million-dollar invoice is an abstract number; the specific cost of the microservices a developer personally owns and operates is a tangible metric they can influence.
Use FinOps tools to translate raw spend data into developer-centric metrics like "cost per feature," "cost per deployment," or "cost per 1000 transactions." Integrate cost estimation tools into your CI/CD pipeline to provide immediate feedback on the financial impact of a code change at the pull request stage.
Publicly celebrate engineering-led cost optimization wins. When a team successfully refactors a service to reduce its operational cost while maintaining or improving performance, recognize their achievement across the organization. This fosters a culture where financial efficiency is a mark of engineering excellence.
Are Reserved Instances Still a Good Idea?
Yes, but their application is now more nuanced and strategic. With the advent of more flexible options like Savings Plans, the decision requires careful analysis of workload stability.
Here is the technical trade-off:
- Savings Plans offer flexibility. They apply discounts to compute usage across different instance families, sizes, and regions. This makes them ideal for workloads that are likely to evolve over the 1- or 3-year commitment term.
- Reserved Instances (specifically Standard RIs) offer a potential for slightly deeper discounts but impose a rigid lock-in to a specific instance family in a specific region. They remain a strong choice for workloads with exceptionally high stability, such as a production database where you are certain the instance type will not change for the entire term.
What's the Biggest Mistake Companies Make?
The single greatest mistake is treating cloud cost reduction as a one-time project rather than a continuous, programmatic practice. Many organizations conduct a large-scale cleanup, achieve temporary savings, and then revert to old habits.
This approach is fundamentally flawed because waste and inefficiency are emergent properties of evolving systems.
Sustainable cost reduction is achieved by embedding cost-conscious principles into daily operations through relentless automation, a cultural shift driven by FinOps, and continuous monitoring and feedback loops. It is a flywheel of continuous improvement, not a project with a defined end date.
Ready to build a culture of cost intelligence and optimize your cloud spend with elite engineering talent? OpsMoon connects you with the top 0.7% of DevOps experts who can implement the strategies discussed in this guide. Start with a free work planning session to map out your cost reduction roadmap. Learn more and get started with OpsMoon.