A Technical Guide to Managed Kubernetes Services
 By opsmoon
By opsmoonExplore managed Kubernetes services with this practical guide. Learn to scale apps, compare providers, and reduce operational overhead with expert insights.

Managed Kubernetes services provide the full declarative power of the Kubernetes API without the immense operational burden of building, securing, and maintaining the underlying control plane infrastructure.
From a technical standpoint, this means you are delegating the lifecycle management of etcd, the kube-apiserver, kube-scheduler, and kube-controller-manager to a provider. This frees up your engineering teams to focus exclusively on application-centric tasks: defining workloads, building container images, and configuring CI/CD pipelines.
Unpacking the Managed Kubernetes Model
At its core, Kubernetes is an open-source container orchestration engine. A self-managed or "DIY" deployment forces your team to manage the entire stack, from provisioning bare-metal servers or VMs to the complex, multi-step process of bootstrapping a highly available control plane and managing its lifecycle. This includes everything from TLS certificate rotation to etcd backups and zero-downtime upgrades.
Managed Kubernetes services abstract this complexity. A cloud provider or specialized firm assumes full operational responsibility for the Kubernetes control plane. The control plane acts as the brain of the cluster, maintaining the desired state and making all scheduling and scaling decisions.
This creates a clear line of demarcation known as a shared responsibility model, defining exactly where the provider's duties end and yours begin.
Provider Responsibilities: The Heavy Lifting
With a managed service, the provider is contractually obligated to handle the most complex and failure-prone aspects of running a production-grade Kubernetes cluster.
Their core responsibilities include:
- Control Plane Availability: Ensuring the high availability of the
kube-apiserver,kube-scheduler, andkube-controller-managercomponents, typically across multiple availability zones and backed by a financially binding Service Level Agreement (SLA). - etcd Database Management: The cluster's key-value store,
etcd, is its single source of truth. The provider manages its high availability, automated backups, restoration procedures, and performance tuning. Anetcdfailure is a catastrophic cluster failure. - Security and Patching: Proactively applying security patches to all control plane components to mitigate known Common Vulnerabilities and Exposures (CVEs), often with zero downtime to the API server.
- Version Upgrades: Executing the complex, multi-step process of upgrading the Kubernetes control plane to newer minor versions, handling potential API deprecations and component incompatibilities seamlessly.
By offloading these responsibilities, you eliminate the need for a dedicated in-house team of platform engineers who would otherwise be consumed by deep infrastructure maintenance.
In essence, a managed service abstracts away the undifferentiated heavy lifting. Your team interacts with a stable, secure, and up-to-date Kubernetes API endpoint without needing to manage the underlying compute, storage, or networking for the control plane itself.
Your Responsibilities: The Application Focus
With the control plane managed, your team's responsibilities shift entirely to the data plane and the application layer. You retain full control over the components that define your software's architecture and behavior.
This means you are still responsible for:
- Workload Deployment: Authoring and maintaining Kubernetes manifest files (YAML) for Deployments, StatefulSets, DaemonSets, Services, and Ingress objects.
- Container Images: Building, scanning, and managing OCI-compliant container images stored in a private registry.
- Configuration and Secrets: Managing application configuration via ConfigMaps and sensitive data like API keys and database credentials via Secrets.
- Worker Node Management: While the provider manages the control plane, you manage the worker nodes (the data plane). This includes selecting instance types, configuring operating systems, and setting up autoscaling groups (e.g., Karpenter or Cluster Autoscaler).
This model enables a higher developer velocity, allowing engineers to deploy code frequently and reliably, backed by the assurance of a stable, secure platform managed by Kubernetes experts.
The Strategic Benefits of Adopting Managed Kubernetes
Adopting managed Kubernetes is a strategic engineering decision, not merely an infrastructure choice. It's about optimizing where your most valuable engineering resources—your people—invest their time. By offloading control plane management, you enable your engineers to shift their focus from infrastructure maintenance to building features that deliver business value.
This pivot directly accelerates the software delivery lifecycle. When developers are not blocked by infrastructure provisioning or debugging obscure etcd corruption issues, they can iterate on code faster. This agility is the key to reducing the concept-to-production time from months to days.
Slashing Operational Overhead and Costs
A self-managed Kubernetes cluster is a significant operational and financial drain. It requires a full-time, highly specialized team of Site Reliability Engineers (SREs) or platform engineers. These are the individuals responsible for responding to 3 AM kube-apiserver outages and executing the delicate, high-stakes procedure of a manual control plane upgrade.
Managed services eliminate the vast majority of this operational toil, which directly reduces your Total Cost of Ownership (TCO). While there is a management fee, it is almost always significantly lower than the fully-loaded cost of hiring, training, and retaining an in-house platform team.
The cost-benefit analysis is clear:
- Reduced Staffing Needs: Avoid the high cost and difficulty of hiring engineers with deep expertise in distributed systems, networking, and Kubernetes internals.
- Predictable Budgeting: Costs are typically based on predictable metrics like per-cluster or per-node fees, making financial forecasting more accurate.
- Elimination of Tooling Costs: Providers often bundle or deeply integrate essential tools for monitoring, logging, and security, which you would otherwise have to procure, integrate, and maintain.
The industry has standardized on Kubernetes, which holds over 90% market share in container orchestration. The shift to managed services is a natural evolution. Some platforms even offer AI-driven workload profiling that can reduce CPU requests by 20–25% and memory by 15–20% through intelligent right-sizing—a direct efficiency gain.
Gaining Superior Reliability and Security
Cloud providers offer financially backed Service Level Agreements (SLAs) that guarantee high uptime for the control plane. A 99.95% SLA is a contractual promise of API server availability. Achieving this level of reliability with a self-managed cluster is a significant engineering challenge, requiring a multi-region architecture and robust automated failover mechanisms.
This guaranteed uptime translates to higher application resiliency. Even a small team can leverage enterprise-grade reliability that would otherwise be cost-prohibitive to build and maintain.
Your security posture is also significantly enhanced. Managed providers are responsible for patching control plane components against the latest CVEs. They also maintain critical compliance certifications like SOC 2, HIPAA, or PCI DSS, a process that can take years and substantial investment for an organization to achieve independently. This provides a secure-by-default foundation for your applications.
To see how these benefits apply to other parts of the modern data stack, like real-time analytics, check out a practical guide to Managed Flink.
Choosing Your Path: Self-Managed vs. Managed Kubernetes
The decision between a self-managed cluster and a managed service is a critical infrastructure inflection point. This choice defines not only your architecture but also your team's operational focus, budget, and velocity. It's the classic trade-off between ultimate control and operational simplicity.
A proper evaluation requires a deep analysis of the total cost of ownership (TCO), the day-to-day operational burden, and whether your use case genuinely requires low-level, kernel-deep customization.
Deconstructing the Total Cost of Ownership
The true cost of a self-managed Kubernetes cluster extends far beyond the price of the underlying VMs. The most significant and often hidden cost is the specialized engineering talent required for 24/7 operations. You must fund a dedicated team of platform or SRE engineers with proven expertise in distributed systems to build, secure, and maintain the cluster.
This introduces numerous, often underestimated costs:
- Specialized Salaries: Six-figure salaries for engineers capable of confidently debugging and operating Kubernetes in a production environment.
- 24/7 On-Call Rotations: The operational burden of responding to infrastructure alerts at 3 a.m. leads to engineer burnout and high attrition rates.
- Tooling and Licensing: You bear the full cost of procuring and integrating essential software for monitoring, logging, security scanning, and disaster recovery—tools often included in managed service fees.
Managed services consolidate these operational costs into a more predictable, consumption-based pricing model. You pay a management fee for the service, not for the entire operational apparatus required to deliver it.
This decision tree illustrates the common technical and business drivers that lead organizations to adopt managed Kubernetes, from accelerating deployment frequency to reducing TCO and improving uptime.
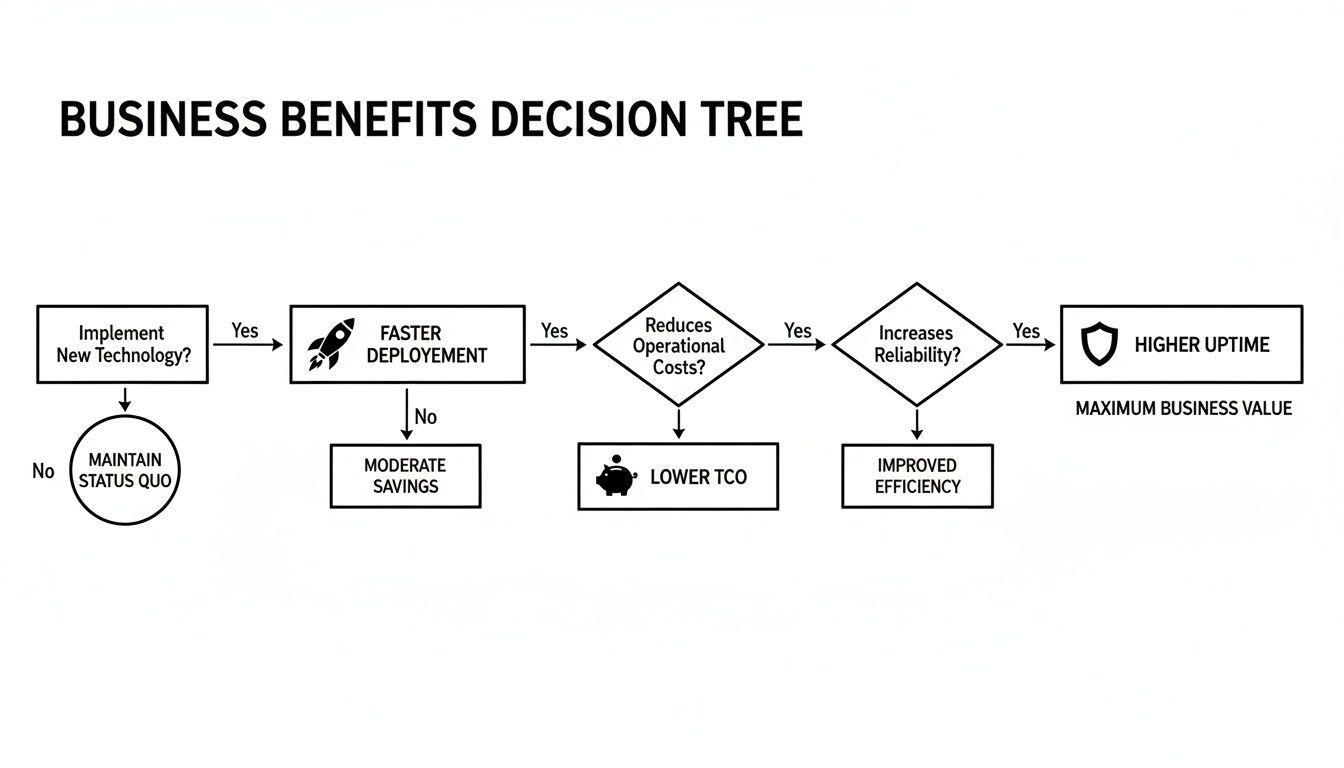
As shown, delegating infrastructure management provides a direct route to enhanced operational efficiency and tangible business outcomes.
The Relentless Grind of DIY Kubernetes Operations
With a self-managed cluster, your team is solely responsible for a perpetual list of complex, high-stakes operational tasks that are completely abstracted away by managed services.
A self-managed cluster makes your team accountable for every single component. A control plane upgrade can become a multi-day, high-stress event requiring careful sequencing and rollback planning. With a managed service, this is often reduced to a few API calls or clicks in a console.
Consider just a few of the relentless operational duties:
- Managing etcd: You are solely responsible for backup/restore procedures, disaster recovery planning, and performance tuning for the cluster's most critical component, the
etcddatabase. - Zero-Downtime Upgrades: Executing seamless upgrades of control plane components (e.g.,
kube-apiserver,kube-scheduler) is a complex procedure where a misstep can lead to a full cluster outage. - Troubleshooting CNI Plugins: When pod-to-pod networking fails or NetworkPolicies are not enforced, it is your team's responsibility to debug the intricate workings of the Container Network Interface (CNI) plugin without vendor support.
The industry trend is clear. Reports estimate that managed offerings now constitute 40–63% of all Kubernetes deployments, as organizations prioritize stability and developer velocity. The market valuation is projected to reach $7–10+ billion by 2030, underscoring this shift.
The following table provides a technical breakdown of the key differences.
Managed Kubernetes vs. Self-Managed Kubernetes: A Technical Breakdown
Choosing between these paths involves weighing different operational realities. This table offers a side-by-side comparison to clarify the technical trade-offs.
| Consideration | Managed Kubernetes Services | Self-Managed Kubernetes |
|---|---|---|
| Control Plane Management | Fully handled by the provider (upgrades, security, patching). | Your team is 100% responsible for setup (e.g., using kubeadm), upgrades, and maintenance. |
| Node Management | Simplified node provisioning and auto-scaling features. Provider handles OS patching for managed node groups. | You manage the underlying OS, patching, kubelet configuration, and scaling mechanisms yourself. |
| Security | Shared responsibility model. Provider secures the control plane; you secure workloads and worker nodes. | Your responsibility from the ground up, including network policies, RBAC, PodSecurityPolicies/Admission, and etcd encryption. |
| High Availability | Built-in multi-AZ control plane redundancy, backed by an SLA. | You must design, implement, and test your own HA architecture for both etcd and API servers. |
| Tooling & Integrations | Pre-integrated with cloud services (IAM, logging, monitoring) out of the box. | Requires manual integration of third-party tools for observability, security, and networking. |
| Cost Model | Predictable, consumption-based pricing. Pay for nodes and a management fee. | High upfront and ongoing costs for specialized engineering talent, tooling licenses, and operational overhead. |
| Expertise Required | Focus on application development, Kubernetes workload APIs, and CI/CD. | Deep expertise in Kubernetes internals, networking (CNI), storage (CSI), and distributed systems is essential. |
Ultimately, the choice comes down to a strategic decision: do you want your team building application features or becoming experts in infrastructure management?
When to Choose Each Path
Despite the clear operational benefits of managed services, certain specific scenarios necessitate a self-managed approach. The decision hinges on unique requirements for control, compliance, and operating environment.
Choose Self-Managed Kubernetes When:
- You operate in a completely air-gapped environment with no internet connectivity, precluding access to a cloud provider's API endpoints.
- Your application requires extreme kernel-level tuning or custom-compiled kernel modules on the control plane nodes themselves.
- You are bound by strict data sovereignty or regulatory mandates that prohibit the use of public cloud infrastructure.
Choose Managed Kubernetes Services When:
- Your primary objective is to accelerate application delivery and reduce time-to-market for new features.
- You want to reduce operational overhead and avoid the cost and complexity of building and retaining a large, specialized platform team.
- Your business requires high availability and reliability backed by a financially guaranteed SLA.
For most organizations, the mission is to deliver software, not to master the intricacies of container orchestration. If you need expert guidance, exploring options like specialized Kubernetes consulting services can provide clarity. To refine your resourcing model, it's also valuable to spend time understanding the distinction between staff augmentation and managed services.
How to Select the Right Managed Kubernetes Provider
Selecting a managed Kubernetes provider is a foundational architectural decision with long-term operational and financial implications. It impacts platform stability, budget, and developer velocity. A rigorous, technical evaluation is necessary to see past marketing claims.
The choice between major providers like Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), and Azure Kubernetes Service (AKS) requires a deep dive into their specific implementations of Kubernetes to find the best technical fit for your team and workloads.
Evaluate Core Technical Capabilities
First, you must analyze the core Kubernetes offering under the hood. This goes beyond a simple feature checklist. You need to understand the service's architecture and lifecycle management policies.
Key technical questions to ask include:
- Supported Kubernetes Versions: How quickly do they offer support for new Kubernetes minor releases? A significant lag can prevent access to crucial features and security patches.
- Upgrade Cadence and Control: How are cluster upgrades managed? Is it a forced, automatic process, or do you have a flexible window to initiate and control the rollout to different environments (e.g., dev, staging, prod)? Can you control node pool upgrades independently from the control plane?
- Control Plane Configuration: What level of access is provided to core component configurations? Can you enable specific API server feature gates or configure audit log destinations and formats to meet stringent compliance requirements?
A provider that offers stable, recent Kubernetes versions with a predictable and user-controlled upgrade path is essential for maintaining a healthy production environment.
Dissecting SLAs and Uptime Guarantees
Service Level Agreements (SLAs) are the provider's contractual commitment to reliability. However, the headline number, such as 99.95% uptime, often requires careful scrutiny of the fine print.
Typically, the SLA for a managed Kubernetes service covers only the availability of the control plane's API server endpoint. It does not cover your worker nodes, your applications, or the underlying cloud infrastructure components like networking and storage.
A provider's SLA is a promise about the availability of the Kubernetes API, not your application's overall uptime. This distinction is critical for designing resilient application architectures and setting realistic operational expectations.
When reviewing an SLA, look for clear definitions of "outage," the specific remedy (usually service credits), and the process for filing a claim. A robust SLA is a valuable safety net, but your application's resilience is ultimately determined by your own architecture (e.g., multi-AZ deployments, pod disruption budgets). For a deeper look, you might want to review some different Kubernetes cluster management tools that can provide greater visibility and control.
Security and Compliance Certifications
Security must be an integral part of the platform, not an afterthought. Your managed Kubernetes provider must meet the compliance standards relevant to your industry, as a missing certification can be an immediate disqualifier.
Look for essential certifications such as:
- PCI DSS: Mandatory for processing credit card data.
- HIPAA: Required for handling protected health information (PHI).
- SOC 2 Type II: An audit verifying the provider's controls for security, availability, and confidentiality of customer data.
The provider is responsible for securing the control plane, but you remain responsible for securing your workloads, container images, and IAM policies. Ensure the provider offers tight integration with their native Identity and Access Management system to enable the enforcement of the principle of least privilege through mechanisms like IAM Roles for Service Accounts (IRSA) on AWS.
Analyzing Cost Models and Ecosystem Maturity
Finally, you must deconstruct the provider's pricing model to avoid unexpected costs. The total cost is more than the advertised per-cluster or per-node fees. Significant costs are often hidden in data transfer (egress) fees between availability zones or out to the internet. Model your expected network traffic patterns to generate a realistic cost projection.
Equally important is the maturity of the provider's ecosystem. A mature platform offers seamless integrations with the tools your team uses daily for:
- Monitoring and Logging: Native support for exporting metrics to services like Prometheus or native cloud observability suites.
- CI/CD Pipelines: Smooth integration with CI/CD tools to automate build and deployment workflows.
- Storage and Networking: A wide variety of supported and optimized CSI (Container Storage Interface) and CNI (Container Network Interface) plugins.
A rich ecosystem reduces the integration burden on your team, allowing them to leverage a solid foundation rather than building everything from scratch.
Navigating the Challenges and Limitations
While managed Kubernetes services dramatically simplify operations, they are not a panacea. Adopting them without understanding the inherent trade-offs can lead to future architectural and financial challenges. Acknowledging these limitations allows you to design more resilient and portable systems.
The most significant challenge is vendor lock-in. Cloud providers compete by offering proprietary features, custom APIs, and deep integrations with their surrounding ecosystem. While convenient, these features create dependencies that increase the technical complexity and financial cost of migrating to another provider or an on-premise environment.
Another challenge is the "black box" nature of the managed control plane. Abstraction is beneficial for daily operations, but during a complex incident, it can become an obstacle. You lose the ability to directly inspect control plane logs or tune low-level component parameters, which can hinder root cause analysis and force reliance on provider support.
Proactively Managing Costs and Complexity
The ease of scaling with managed Kubernetes can be a double-edged sword for your budget. A single kubectl scale command can provision dozens of new nodes, and without strict governance, this can lead to significant cost overruns. Implementing FinOps practices is not optional; it is a required discipline.
Even with a managed service, Kubernetes itself remains a complex system. Networking, security, and storage are still significant challenges for many teams. Studies show that approximately 28% of organizations encounter major roadblocks in these areas. This has spurred innovation, with over 60% of new enterprise Kubernetes deployments now using AI-powered monitoring to optimize resource utilization and maintain uptime. You can explore these trends in market reports on the growth of Kubernetes solutions.
Strategies for Mitigation
These potential pitfalls can be mitigated with proactive engineering discipline. The goal is to leverage the convenience of managed Kubernetes while maintaining architectural flexibility and financial control.
Vendor lock-in is not inevitable; it is the result of architectural choices. By designing for portability from the outset, you retain strategic freedom and keep future options open.
Here are concrete technical strategies to maintain control:
- Embrace Open-Source Tooling: Standardize on open-source, cloud-agnostic tools wherever possible. Use Prometheus for monitoring, Istio or Linkerd for a service mesh, and ArgoCD or Jenkins for CI/CD. This minimizes dependencies on proprietary provider services.
- Design for Portability with IaC: Use Infrastructure-as-Code (IaC) tools like Terraform or OpenTofu. Defining your entire cluster configuration—including node groups, VPCs, and IAM roles—in code creates a repeatable, version-controlled blueprint that is less coupled to a specific provider's console or CLI.
- Implement Rigorous FinOps Practices: Enforce Kubernetes resource requests and limits on every workload as a mandatory CI check. Utilize cluster autoscalers effectively to match capacity to demand. Implement detailed cost allocation using labels and configure budget alerts to detect spending anomalies before they escalate.
By integrating these practices into your standard operating procedures, you can achieve the ideal balance: a powerful, managed platform that provides developer velocity without sacrificing architectural control or financial discipline.
Your Technical Checklist for Migration and Adoption

Migrating to a managed Kubernetes service is a structured engineering project, not an ad-hoc task. This checklist provides a methodical, phase-based approach to guide you from initial planning through to production operations.
A rushed migration inevitably leads to performance bottlenecks, security vulnerabilities, and operational instability. Following a structured plan is the most effective way to mitigate risk and build a robust foundation for your applications.
Phase 1: Assessment and Planning
This initial phase is dedicated to discovery and strategic alignment. Before writing any YAML, you must perform a thorough analysis of your application portfolio and define clear, measurable success criteria.
Begin with an application readiness assessment. Categorize your services: are they stateless or stateful? This distinction is critical. Stateful workloads like databases require a more complex migration strategy involving PersistentVolumeClaims, StorageClasses, and potentially a specialized operator for lifecycle management.
Next, define your success metrics with quantifiable Key Performance Indicators (KPIs). For example:
- Reduce CI/CD deployment time from 45 minutes to 15 minutes.
- Achieve a Service Level Objective (SLO) of 99.95% application uptime.
- Reduce infrastructure operational costs by 20% year-over-year.
Finally, select a pilot application. Choose a low-risk, stateless service that is complex enough to be a meaningful test but not so critical that a failure would impact the business. This application will serve as your proving ground for a new toolchain and operational model.
Phase 2: Environment Configuration
With a plan in place, the next step is to build the foundational infrastructure on your chosen managed Kubernetes service. This phase focuses on networking, security, and automation.
Start by defining your network architecture. This includes designing Virtual Private Clouds (VPCs), subnets, and security groups or firewall rules to enforce network segmentation and control traffic flow. A well-designed network topology is your first line of defense.
This is the point where Infrastructure as Code (IaC) becomes non-negotiable. Using a tool like Terraform to define your entire environment makes your setup repeatable, version-controlled, and auditable from day one. It's a game-changer.
Once the network is defined, configure Identity and Access Management (IAM). Adhere strictly to the principle of least privilege. Create specific IAM roles with fine-grained permissions for developers, CI/CD systems, and cluster administrators, and map them to Kubernetes RBAC roles. This is the most effective way to prevent unauthorized access and limit the blast radius of a potential compromise. For a practical look at this, check out our guide on Terraform with Kubernetes.
Phase 3: Application Migration
Now you are ready to migrate your pilot application. This phase involves the hands-on technical work of containerizing the application, building automated deployment pipelines, and implementing secure configuration management.
First, containerize the application by creating an optimized, multi-stage Dockerfile. The objective is to produce a minimal, secure container image. Store this image in a private container registry such as Amazon ECR or Google Artifact Registry.
Next, build your CI/CD pipeline. This workflow should automate static code analysis, unit tests, vulnerability scanning (e.g., with Trivy or Snyk), image building, and deployment to the cluster. Tools like ArgoCD for GitOps or Jenkins are commonly used. For secrets management, use a dedicated secrets store like HashiCorp Vault or the cloud provider's native secrets manager, injecting secrets into pods at runtime rather than storing them in Git.
Phase 4: Day-2 Operations
Deploying the pilot application is a major milestone, but the project is not complete. The focus now shifts to ongoing Day-2 operations: monitoring, optimization, and incident response.
First, implement robust autoscaling policies. Configure the Horizontal Pod Autoscaler (HPA) to scale application pods based on metrics like CPU utilization or custom metrics (e.g., requests per second). Simultaneously, configure the Cluster Autoscaler to add or remove worker nodes from the cluster based on aggregate pod resource requests. This combination ensures both performance and cost-efficiency.
Next, establish a comprehensive observability stack. Deploy tools to collect metrics, logs, and traces to gain deep visibility into both application performance and resource consumption. This data is essential for performance tuning and cost optimization.
Finally, create an operational runbook. This document should detail common failure scenarios, step-by-step troubleshooting procedures, and clear escalation paths. A well-written runbook is invaluable during a high-stress incident.
Let's address some common technical questions that arise during the evaluation of managed Kubernetes services.
How Do Managed Services Handle Security Patching?
The provider assumes full responsibility for patching the control plane components (kube-apiserver, etcd, etc.) for known CVEs. This is typically done automatically and with zero downtime to the control plane API.
For worker nodes, the provider releases patched node images containing the latest OS and kernel security fixes. It is then your responsibility to trigger a rolling update of your node pools. This process safely drains pods from old nodes and replaces them with new, patched ones, ensuring no disruption to your running services.
This is a clear example of the shared responsibility model in action. The provider handles the complex patching of the cluster's core, while you retain control over the timing of updates to your application fleet.
The key takeaway here is that the most complex, high-stakes patching is handled for you. Your job shifts from doing the risky manual work to simply scheduling the rollout to your application fleet.
Can I Use Custom CNI Or CSI Plugins?
The answer depends heavily on the provider. The major cloud providers—Amazon EKS, Google Kubernetes Engine (GKE), and Azure Kubernetes Service (AKS)—ship with their own tightly integrated CNI (Container Network Interface) and CSI (Container Storage Interface) plugins that are optimized for their respective cloud environments.
Some services offer the flexibility to install third-party plugins like Calico or Cilium for advanced networking features. However, using a non-default plugin can introduce complexity, and the provider may not offer technical support for issues related to it.
It is critical to verify that any required custom plugins are officially supported by the provider before committing to the platform. This is a common technical "gotcha" that can derail a migration if not addressed early in the evaluation process.
What Happens If The Managed Control Plane Has An Outage?
Even with a highly available, multi-AZ control plane, outages are possible. If the control plane (specifically the API server) becomes unavailable, your existing workloads running on the worker nodes will continue to function normally.
The data plane (where your applications run) is decoupled from the control plane. However, during the outage, all cluster management operations that rely on the Kubernetes API will fail:
- You cannot deploy new applications or update existing ones (
kubectl applywill fail). - Autoscaling (both HPA and Cluster Autoscaler) will not function.
- You cannot query the cluster's state using
kubectl.
The provider's Service Level Agreement (SLA) defines their contractual commitment to restoring control plane functionality within a specified timeframe.
How Much Control Do I Actually Lose?
By opting for a managed service, you are trading direct, low-level control of the control plane infrastructure for operational simplicity and reliability. You will not have SSH access to control plane nodes, nor can you modify kernel parameters or core component flags directly.
However, you are not left with an opaque black box. Most providers expose key configuration options via their APIs, allowing you to customize aspects like API server audit logging or enable specific Kubernetes feature gates. You are essentially trading root-level access for the significant operational advantage of not having to manage, scale, or repair that critical infrastructure yourself.
Ready to accelerate your software delivery without the infrastructure headache? OpsMoon connects you with the top 0.7% of remote DevOps engineers to build, manage, and scale your Kubernetes environment. Start with a free work planning session to map your roadmap to success. Learn more about how OpsMoon can help.