How to Choose a Cloud Provider: A Technical Guide
 By opsmoon
By opsmoonhow to choose cloud provider: Use our concise framework to compare AWS, Azure, and GCP on cost, performance, security, and services.

Choosing a cloud provider is a foundational engineering decision with long-term consequences, impacting everything from application architecture to operational overhead. A superficial comparison of pricing tables is insufficient. A robust selection process requires defining precise technical requirements, building a data-driven evaluation framework, and executing a rigorous proof-of-concept (PoC) to validate vendor claims against real-world workloads. This methodology ensures your final choice aligns with your architectural principles, operational capabilities, and strategic business objectives.
Building Your Cloud Decision Framework
Selecting an infrastructure partner requires cutting through marketing hype and building a technical framework for an informed, defensible decision. A structured, three-stage workflow is the most effective approach to manage the complexity of this process.
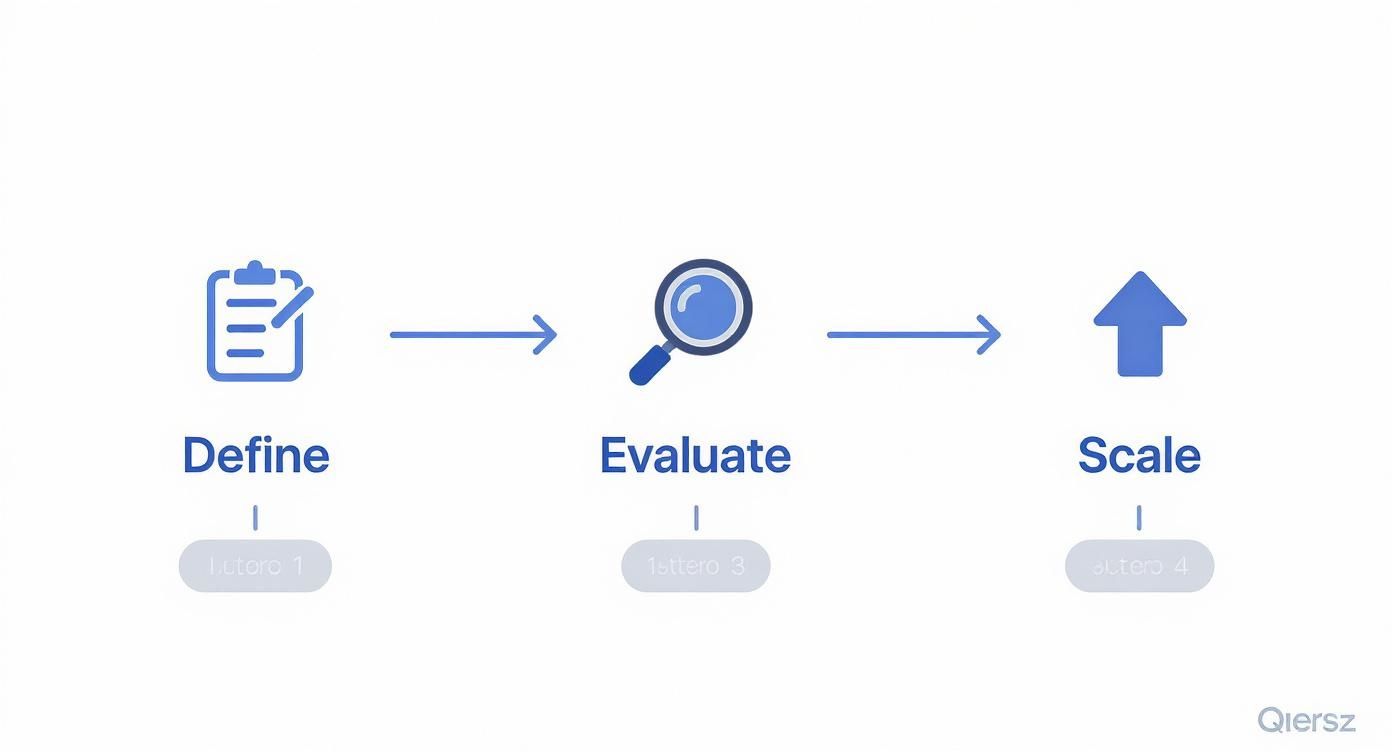
This workflow deconstructs the decision into three logical phases: defining technical specifications, evaluating providers against those specifications, and planning for architectural scalability and cost management.
This table provides a high-level roadmap for the core pillars of the selection process.
Quick Decision Framework Overview
| Evaluation Pillar | Key Objective | Primary Considerations |
|---|---|---|
| Requirements Definition | Translate business goals into quantifiable technical specifications. | Performance metrics (latency, IOPS), security mandates (IAM policies, network segmentation), compliance frameworks (SOC 2, HIPAA). |
| Evaluation Criteria | Compare providers objectively using a weighted scoring matrix. | Cost models (TCO analysis including egress), SLA guarantees (service-specific uptime, credit terms), managed service capabilities. |
| Future Scalability | Assess long-term architectural viability and mitigate strategic risks. | Vendor lock-in (proprietary APIs vs. open standards), migration complexity, ecosystem maturity, and IaC support. |
Each pillar is critical; omitting one introduces a significant blind spot into your decision-making process.
The most common strategic error is engaging with vendor demos prematurely. This approach allows vendor-defined features to dictate your requirements. The process must begin with an internally-generated requirements document, not a provider's product catalog.
Understanding the Market Landscape
The infrastructure-as-a-service (IaaS) market is dominated by three hyperscalers. As of Q2 2024, Amazon Web Services (AWS) leads with 30% of the market. Microsoft Azure (Azure) holds 20%, and Google Cloud (GCP) has 13%.
Collectively, they control 63% of the market, making them the default shortlist for most organizations. For a granular breakdown, refer to this cloud provider market share analysis on SlickFinch.
This guide provides a detailed methodology to technically dissect providers like AWS, Azure, and GCP, ensuring your final decision is backed by empirical data and a clear architectural roadmap.
Defining Your Technical and Business Requirements
Before engaging any cloud provider, you must construct a detailed blueprint of your technical and business needs. This document serves as the objective standard against which all potential partners will be measured. The first step is to translate high-level business goals into specific, measurable, achievable, relevant, and time-bound (SMART) technical specifications.
For example, a business objective to "improve user experience" must be decomposed into quantifiable engineering targets:
- Target p99 latency: API gateway endpoint
/api/v1/checkoutmust maintain a p99 latency below 150ms under a load of 5,000 concurrent users. - Required IOPS: The primary PostgreSQL database replica must sustain 15,000 IOPS with sub-10ms read latency during peak load simulations.
- Uptime SLA: Critical services require a 99.99% availability target, necessitating a multi-AZ or multi-region failover architecture.
This quantification process enforces precision and focuses the evaluation on metrics that directly impact application performance and business outcomes.
Auditing Your Current Application Stack
A comprehensive audit of your existing applications and infrastructure is non-negotiable. This involves mapping every dependency, constraint, and integration point to preempt migration roadblocks.
Your audit must produce a detailed inventory of the following:
- Application Dependencies: Document all internal and external service endpoints, APIs, and data sources. Identify tightly coupled components that may require re-architecting from a monolith to microservices before migration.
- Data Sovereignty and Residency: Enumerate all legal and regulatory constraints on data storage locations (e.g., GDPR, CCPA). This will dictate the viable cloud regions and may require specific data partitioning strategies.
- Network Topology: Diagram the current network architecture, including CIDR blocks, VLANs, VPN tunnels, and firewall ACLs. This is foundational for designing a secure and performant Virtual Private Cloud (VPC) structure.
- CI/CD Pipeline Integration: Analyze your existing continuous integration and delivery toolchain. The target cloud must offer robust integration with your source control (e.g., Git), build servers (Jenkins, GitLab CI), and deployment automation (GitHub Actions).
A critical pitfall is underestimating legacy dependencies. One client discovered mid-evaluation that a critical service relied on a specific kernel version of an outdated Linux distribution, invalidating their initial compute instance selection and forcing a re-evaluation.
Documenting Compliance and Team Skills
Security, compliance, and team capabilities are as critical as technical performance in selecting a cloud provider.
Begin by cataloging every mandatory compliance framework.
Mandatory Compliance Checklist:
- SOC 2: Essential for SaaS companies handling customer data.
- HIPAA: Required for applications processing protected health information (PHI).
- PCI DSS: Mandatory for systems that process, store, or transmit cardholder data.
- FedRAMP: A prerequisite for solutions sold to U.S. federal agencies.
Review each provider's documentation and shared responsibility model for these standards.
Finally, perform an objective skills assessment of your engineering team. A team proficient in PowerShell and .NET will have a shorter learning curve with Azure. Conversely, a team with deep experience in Linux and open-source ecosystems may find AWS or GCP more aligned with their existing workflows. This analysis informs the total cost of ownership by identifying needs for training or external expertise from partners like OpsMoon.
This comprehensive technical blueprint becomes the definitive guide for all subsequent evaluation stages.
Establishing Your Core Evaluation Criteria
With your requirements defined, you can construct an evaluation matrix. This is a structured, data-driven framework for comparing providers. The objective is to create a weighted scoring system based on your specific needs, preventing decisions based on marketing claims or generic feature sets.
A robust evaluation matrix allows for objective comparison across several critical dimensions.
Deconstructing Total Cost of Ownership
Analyzing on-demand instance pricing is a superficial approach that leads to inaccurate cost projections. A thorough Total Cost of Ownership (TCO) model is required, which accounts for various pricing models, data transfer fees, and storage I/O costs for a representative workload.
Frame your cost analysis with these components:
- Reserved Instances (RIs) vs. Savings Plans: Model your baseline, predictable compute workload using one- and three-year commitment pricing. Compare the effective discounts and flexibility of AWS Savings Plans, Azure Reservations, and GCP's Committed Use Discounts.
- Spot Instances: For fault-tolerant, interruptible workloads like batch processing or CI/CD jobs, model costs using Spot Instances (AWS), Spot VMs (Azure), or Spot VMs (GCP). Architect your application to handle interruptions to leverage potential savings of up to 90%.
- Data Egress Fees: Estimate monthly outbound data transfer volumes (GB/month) to different internet destinations. Calculate the cost using each provider's tiered pricing structure, as this is a frequently overlooked and significant expense.
Cloud adoption trends reflect significant financial commitment. Projections show 33% of organizations will spend over $12 million annually on public cloud by 2025. This underscores the importance of accurate TCO modeling. Further insights are available in these public cloud spending trends on Veritis.com.
Accurate TCO modeling is labor-intensive but essential. For more detailed methodologies, review our guide on effective cloud cost optimization strategies.
Benchmarking Real-World Performance
Vendor performance claims must be validated against your specific workload profiles. Not all vCPUs are equivalent; performance varies significantly based on the underlying hardware generation and hypervisor.
Execute targeted benchmarks for different workload types:
- CPU-Bound Workloads: Use a tool like
sysbench(sysbench cpu --threads=16 run) to benchmark compute-optimized instances (e.g., AWS c6i, Azure Fsv2, GCP C3). Measure metrics like events per second and prime numbers computation time to determine the optimal price-to-performance ratio. - Memory-Bound Workloads: For in-memory databases or caching layers, benchmark memory-optimized instances (e.g., AWS R-series, Azure E-series, GCP M-series) using tools that measure memory bandwidth and latency, such as
STREAM. - Network Latency: Use
pingandiperf3to measure round-trip time (RTT) and throughput between Availability Zones (AZs) within a region. Low inter-AZ latency (<2ms) is critical for synchronous replication and high-availability architectures.
Dissecting SLAs and Financial Risk
A 99.99% uptime SLA translates to approximately 52.6 minutes of potential downtime per year. You must calculate the financial impact of such an outage on your business.
For each provider, analyze the SLA documents to answer:
- What services are covered? The SLA for a compute instance often differs from that of a managed database or a load balancer.
- What are the credit terms? SLA breaches typically result in service credits, which are a fraction of the actual revenue lost during downtime.
- How is downtime calculated? Understand the provider's definition of "unavailability" and the specific process for filing a claim, which often requires detailed logs and is time-sensitive.
By quantifying your revenue loss per minute, you can convert abstract SLA percentages into concrete financial risk assessments.
Putting It All Together: The Scoring Matrix
Consolidate your data into a weighted scoring matrix. This tool provides an objective, quantitative basis for your final decision. Assign a weight (1-5) to each criterion based on its importance to your business, then score each provider (1-10) against that criterion.
Cloud Provider Scoring Matrix Template
| Criteria | Weight (1-5) | Provider A Score (1-10) | Provider B Score (1-10) | Weighted Score |
|---|---|---|---|---|
| Total Cost of Ownership | 5 | 8 | 6 | A: 40, B: 30 |
| CPU Performance (sysbench) | 4 | 7 | 9 | A: 28, B: 36 |
| Inter-AZ Network Latency | 3 | 9 | 8 | A: 27, B: 24 |
| Uptime SLA & Credit Terms | 4 | 8 | 8 | A: 32, B: 32 |
| Compliance Certifications | 5 | 9 | 7 | A: 45, B: 35 |
| Total Score | A: 172, B: 157 |
This quantitative methodology ensures the selection is defensible and aligned with your unique technical and business requirements.
Running an Effective Proof of Concept
Your scoring matrix is a well-informed hypothesis. A Proof of Concept (PoC) is the experiment designed to validate it. The goal is not a full migration but to deploy a representative, technically challenging slice of your application to pressure-test your assumptions and collect empirical performance data.
An ideal PoC candidate is a single microservice with a database dependency. This allows for controlled testing of compute, database I/O, and network performance.
Designing Your Benchmark Tests
Effective benchmarking simulates real-world conditions to measure KPIs relevant to your application's health. Your objective is to collect performance data under significant, scripted load.
For a typical web service, the PoC must measure:
- API Response Latency: Use load testing tools like K6 or JMeter to simulate concurrent user traffic against your API endpoints. Capture not just the average response time but also the p95 and p99 latencies, as these tail latencies are more indicative of user-perceived performance.
- Database Query Times: Execute your most frequent and resource-intensive queries against the provider's managed database service (e.g., Amazon RDS, Google Cloud SQL) while the system is under load. Monitor query execution plans and latency to validate performance against your specific schema.
- Managed Service Performance: If using a managed Kubernetes service like EKS, AKS, or GKE, test its auto-scaling capabilities. Measure the time required for the cluster to provision and schedule new pods in response to a sudden traffic spike. This "time-to-scale" directly impacts performance and cost.
This data-driven approach moves the evaluation from subjective "feel" to objective metrics: "Provider A delivered a sub-100ms p99 latency for our checkout service under 5,000 concurrent requests, while Provider B's latency exceeded 250ms."
Uncovering Hidden Hurdles
A PoC is also a diagnostic tool for identifying operational friction and unexpected implementation challenges that are never mentioned in marketing materials.
During one PoC, we discovered that a provider's IAM policy structure was unnecessarily complex. Granting a service account read-only access to a specific object storage path required a convoluted policy document, indicating a steeper operational learning curve for the team.
To systematically uncover these blockers, your PoC should include a checklist of common operational tasks.
PoC Operational Checklist:
- Deployment: Integrate the PoC microservice into your existing CI/CD pipeline. Document the level of effort and any required workarounds.
- Monitoring and Logging: Configure basic observability. Test the ease of exporting logs and metrics from managed services into your preferred third-party monitoring platform.
- Security Configuration: Implement a sample network security policy using the provider's security groups or firewall rules. Evaluate the intuitiveness and power of the tooling.
- Cost Monitoring: Track the PoC's spend in near-real-time using the provider's cost management tools. Investigate any unexpected or poorly documented line items on the daily bill.
Executing these hands-on tests provides a realistic assessment of the day-to-day operational experience on each platform, which is a critical factor in the final decision. For a broader context, our guide on how to properly migrate to the cloud integrates these PoC principles into a comprehensive migration strategy.
Analyzing Specialized Services and Ecosystem Fit
https://www.youtube.com/embed/WJGhWNOPrK8
While core compute and storage services have become commoditized, the higher-level managed services and surrounding ecosystem are the primary differentiators and sources of potential vendor lock-in. Choosing a cloud provider is an investment in a specific technical ecosystem and operational philosophy. This decision has far-reaching implications for development velocity, operational overhead, and long-term innovation capacity.
Comparing Managed Kubernetes Services
For containerized applications, a managed Kubernetes service is a baseline requirement. However, the implementations from the "Big Three" have distinct characteristics.
- Amazon EKS (Elastic Kubernetes Service): EKS provides a highly available, managed control plane but delegates significant responsibility for worker node management to the user. This offers granular control, ideal for teams requiring custom node configurations (e.g., custom AMIs, GPU instances), but entails higher operational overhead for patching and upgrades.
- Azure AKS (Azure Kubernetes Service): AKS excels in its deep integration with the Microsoft ecosystem, particularly Azure Active Directory for RBAC and Azure Monitor. Its developer-centric features and streamlined auto-scaling provide a low-friction experience for teams heavily invested in Azure.
- Google GKE (Google Kubernetes Engine): As the originator of Kubernetes, GKE is widely considered the most mature and feature-rich offering. Its Autopilot mode, which abstracts away all node management, is a compelling option for teams seeking to minimize infrastructure operations and focus exclusively on application deployment.
Our in-depth comparison of AWS vs Azure vs GCP services provides a more detailed analysis of their respective strengths.
Evaluating the Serverless Ecosystem
Serverless platforms like AWS Lambda, Azure Functions, and Google Cloud Run offer abstraction from infrastructure management, but their performance characteristics and developer experience differ significantly.
Cold starts—the latency incurred on the first invocation of an idle function—are a critical performance consideration for synchronous, user-facing APIs. This latency is influenced by the runtime (Go and Rust typically have lower cold start times than Java or .NET), memory allocation, and whether the function needs to initialize connections within a VPC.
Do not rely on simplistic "hello world" benchmarks. A meaningful test involves a function that reflects your actual workload, including initializing database connections and making downstream API calls. This is the only way to measure realistic cold-start latency.
Consider the provider's industry focus. AWS has a strong presence in retail, media, and technology startups. Azure is dominant in enterprise IT and hybrid cloud environments. Google Cloud is a leader in data analytics, AI/ML, and large-scale data processing. Aligning your workload with a provider's core competencies can provide access to a more mature and relevant ecosystem. Case studies like Alphasights' tech stack choices offer valuable insights into how these ecosystem factors influence real-world architectural decisions.
A Few Lingering Questions
Even with a rigorous evaluation framework, several strategic questions inevitably arise during the final decision-making phase.
How Much Should I Worry About Vendor Lock-In?
Vendor lock-in is a significant strategic risk that must be actively managed, not ignored. It occurs when an application becomes dependent on proprietary services (e.g., AWS DynamoDB, Google Cloud's BigQuery), making migration to another provider prohibitively complex and expensive. The objective is not to avoid proprietary services entirely, but to make a conscious, risk-assessed decision about where to use them.
Employ a layered architectural strategy to mitigate lock-in:
- Utilize Open-Source Technologies: For critical data layers, prefer open-source solutions like PostgreSQL or MySQL running on managed instances over proprietary databases. This ensures data portability.
- Embrace Infrastructure-as-Code (IaC): Use cloud-agnostic tools like Terraform with a modular structure. This abstracts infrastructure definitions, facilitating recreation in a different environment.
- Implement an Abstraction Layer: Isolate proprietary service integrations behind your own internal APIs (an anti-corruption layer). This decouples your core application logic from the specific cloud service, allowing the underlying implementation to be swapped with less friction.
Vendor lock-in is fundamentally a negotiation problem. The more integrated you are with proprietary services, the less leverage you have during contract renewals. Managing this risk preserves future strategic options.
Should I Start with a Multi-Cloud or Hybrid Strategy?
For most companies, the answer is a definitive "no." The most effective strategy is to select a single primary cloud provider and develop deep expertise. A single-provider approach simplifies architecture, reduces operational complexity, and allows for more effective cost optimization.
A multi-cloud strategy (using services from different providers for different workloads) is a tactical choice, justified only by specific technical or business drivers.
When Multi-Cloud Makes Sense:
- Best-of-Breed Services: Using a specific service where one provider has a clear technical advantage (e.g., running primary applications on AWS while using Google Cloud's BigQuery for data warehousing).
- Data Residency Requirements: Using a local provider in a region where your primary vendor does not have a presence to comply with data sovereignty laws.
- Strategic Risk Mitigation: For very large enterprises, it can be a strategy to avoid over-reliance on a single vendor and improve negotiation leverage.
Similarly, a hybrid cloud architecture (integrating public cloud with on-premises infrastructure) is a solution for specific use cases, such as legacy systems that cannot be migrated, stringent regulatory requirements, or workloads that require low-latency connectivity to on-premises hardware.
Start with a single provider and only adopt a multi-cloud or hybrid strategy when a clear, data-driven business case emerges.
What Are the Sneakiest "Hidden" Costs on a Cloud Bill?
Cloud bills can escalate unexpectedly if not monitored carefully. The most common sources of cost overruns are data transfer, I/O operations, and orphaned resources.
Data egress fees (costs for data transfer out of the cloud provider's network) are a notorious source of surprise charges. For applications with high outbound data volumes, like video streaming or large file distribution, egress can become a dominant component of the monthly bill.
Storage costs are multifaceted. Beyond paying for provisioned gigabytes, you are also charged for API requests (GET, PUT, LIST operations on object storage) and provisioned IOPS on block storage volumes. Over-provisioning IOPS for a database that doesn't require them is a common and costly mistake.
Finally, idle or "zombie" resources represent a persistent financial drain. These include unattached Elastic IPs, unmounted EBS volumes, and oversized VMs with low CPU utilization. A robust FinOps practice, including automated tagging, monitoring, and alerting, is essential for identifying and eliminating this waste and ensuring your choice of cloud provider remains cost-effective.
Navigating this complex process requires deep technical expertise. OpsMoon provides the DevOps proficiency needed to build a data-driven evaluation framework, execute a meaningful proof of concept, and select the optimal cloud partner for your long-term success.
It all starts with a free work planning session to map out your cloud strategy. Learn more at OpsMoon.