9 Best Practices for Software Deployment in 2025
 By opsmoon
By opsmoonDiscover the top 9 best practices for software deployment. This in-depth guide covers CI/CD, IaC, and monitoring for more reliable releases.
Software deployment is no longer a simple act of moving code from a developer’s machine to a server. It has evolved into a sophisticated, high-stakes process that directly impacts user experience, system stability, and business velocity. In a competitive market, a flawed deployment can trigger costly downtime, introduce critical security vulnerabilities, and damage brand reputation. The core differentiator between high-performing engineering teams and their counterparts often boils down to a disciplined, automated, and resilient deployment strategy.
This guide moves beyond generic advice to offer a curated roundup of the most essential and actionable best practices for software deployment. We will dissect the technical specifics of modern release methodologies, providing concrete implementation details, practical code examples, and strategic insights to help you engineer a deployment workflow that is both fast and robust. Whether you're a startup CTO or an enterprise IT leader, mastering these techniques will transform your release process from a source of anxiety into a strategic advantage.
The goal is to build a system where shipping code is a routine, low-risk event, not a monumental effort. As you master the modern deployment workflow, it's worth exploring platforms that simplify DevOps tasks, potentially reducing the need for extensive dedicated DevOps efforts. From advanced CI/CD pipelines and Infrastructure as Code (IaC) to sophisticated strategies like canary releases and feature flags, this article provides a comprehensive blueprint. We will cover:
- Continuous Integration and Continuous Deployment (CI/CD)
- Blue-Green Deployment
- Canary Deployment
- Infrastructure as Code (IaC)
- Automated Testing in Deployment Pipelines
- Feature Flags and Toggle Management
- Proactive Monitoring and Alerting
- Database Migration and Schema Versioning
- Secure Configuration Management
Prepare to gain the technical knowledge needed to build a deployment machine that supports rapid innovation while ensuring rock-solid reliability.
1. Continuous Integration and Continuous Deployment (CI/CD)
At the core of modern software delivery lies the practice of Continuous Integration and Continuous Deployment (CI/CD). This methodology automates the software release process, transforming it from a high-risk, infrequent event into a routine, low-risk activity. CI/CD establishes an automated pipeline that builds, tests, and deploys code changes, enabling development teams to deliver value to users faster and more reliably. This approach is fundamental among the best practices for software deployment because it directly addresses speed, quality, and efficiency.
How CI/CD Pipelines Work
The process begins when a developer commits code to a version control repository like Git. This action automatically triggers a series of orchestrated steps:
- Continuous Integration (CI): The system automatically builds the application (e.g., compiling code, creating a Docker image) and runs a comprehensive suite of automated tests (unit, integration, static code analysis). A failed build or test immediately alerts the team via Slack or email, enabling rapid fixes before the faulty code is merged into the main branch.
- Continuous Deployment (CD): Once the CI phase passes successfully, the pipeline automatically deploys the validated artifact to a staging environment for further testing (e.g., end-to-end tests, performance load tests). Upon passing all checks, it can then be promoted and deployed directly to production without manual intervention.
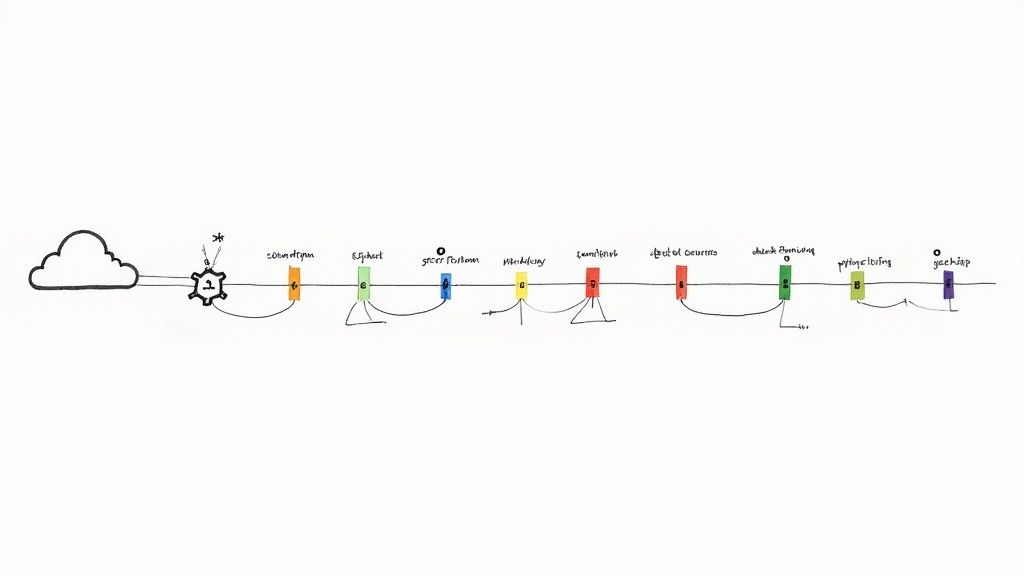
The following infographic illustrates the essential stages of a CI/CD pipeline and the key metrics used to measure its health and efficiency.
This visualization highlights how successful pipelines depend on high test pass rates and deployment success rates to maintain a high frequency of builds moving through the system. By monitoring these metrics, teams can quickly identify bottlenecks and improve the reliability of their release process, creating a virtuous cycle of improvement. Companies like Netflix and Amazon leverage highly sophisticated CI/CD pipelines to deploy thousands of times per day, demonstrating the scalability and power of this practice.
2. Blue-Green Deployment
Blue-Green deployment is a powerful release strategy that minimizes downtime and reduces risk by maintaining two identical, isolated production environments named "Blue" and "Green." At any given moment, only one environment, the active one (e.g., Blue), serves live user traffic. The other, idle environment (e.g., Green), acts as a staging ground for the next software version. This technique is a cornerstone among the best practices for software deployment because it provides an immediate, one-step rollback capability, making releases significantly safer.
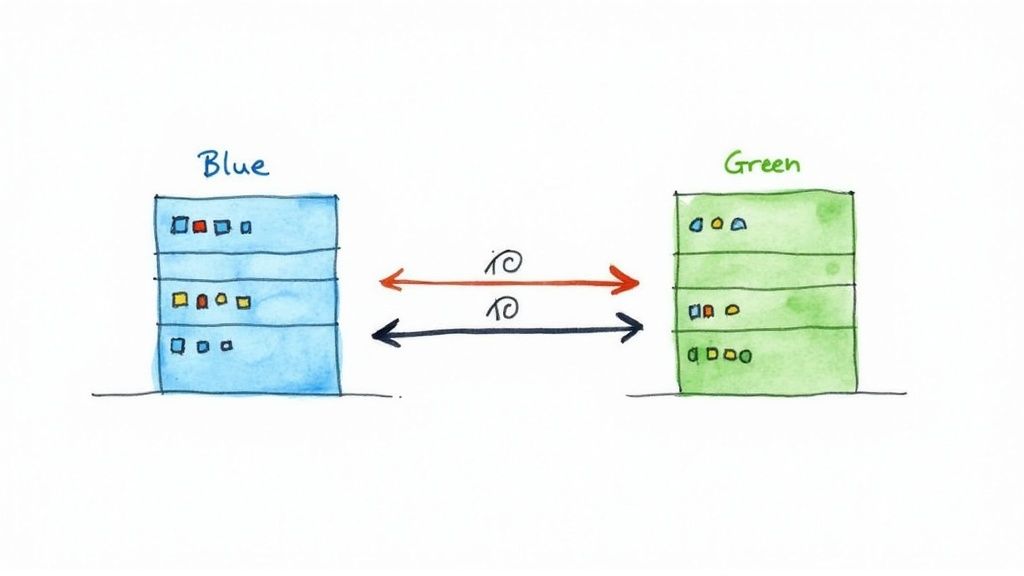
How Blue-Green Deployment Works
The deployment process follows a structured, controlled sequence. When a new version is ready, it is deployed to the idle Green environment. Here, it undergoes a full suite of automated tests, smoke tests, and quality assurance checks, all while being completely isolated from live users. Once the new version is fully validated, the magic happens:
- Traffic Routing: A router or load balancer is reconfigured to instantly switch all incoming traffic from the old Blue environment to the new Green environment. In a Kubernetes environment, this can be achieved by updating a Service's
selectorto point to the pods with the new version's label. - Instant Rollback: If any issues arise post-release, rolling back is as simple as switching the router back to the original Blue environment, which is still running the stable, previous version. The old Blue environment is kept on standby until the new Green version is deemed stable.
This near-instantaneous switchover ensures zero downtime for users and provides a robust safety net. Organizations like Netflix and platforms like AWS CodeDeploy leverage this technique to manage updates across their distributed systems reliably.
The following video from Martin Fowler offers a deeper technical explanation of the mechanics and strategic benefits of implementing this deployment pattern.
Implementing this strategy requires careful planning, particularly around stateful applications and database migrations, but the resulting increase in deployment reliability is a significant advantage. It transforms high-stakes release events into low-stress, routine operations.
3. Canary Deployment
Canary deployment is a strategic, risk-averse release technique where a new software version, the "canary," is incrementally rolled out to a small subset of production traffic. This method allows teams to test new features and monitor performance in a live environment with a limited user base, significantly reducing the blast radius of potential bugs or performance issues. Originating from the "canary in a coal mine" analogy, this practice is a cornerstone among the best practices for software deployment because it provides a safety net for introducing change, enabling teams to validate stability and gather real-world feedback before a full-scale release.
This gradual exposure is a powerful way to de-risk deployments. By directing a small percentage of users (e.g., 1%, 5%, or even just internal employees) to the new version while the majority remains on the stable version, teams can compare performance metrics like error rates, latency, and resource utilization side-by-side. If the canary version performs as expected against predefined success metrics, traffic is progressively shifted until 100% of users are on the new version. If issues arise, the traffic can be quickly redirected back to the old version with minimal user impact.
Implementing a Canary Strategy
A successful canary deployment depends on a well-defined process and robust automation. The key is to establish objective criteria for promoting the canary, rather than relying on manual checks or gut feelings.
- Define Clear Metrics: Before deployment, establish specific Service Level Objectives (SLOs) for key performance indicators. This could include a 99.9% success rate for HTTP requests, a P95 latency below 200ms, and a CPU utilization below 75%. The canary must meet or exceed these SLOs to be considered successful.
- Automate Analysis and Rollback: Use monitoring and observability tools (like Prometheus and Grafana) to automatically compare the canary’s performance against the stable version. If the canary violates the predefined SLOs (e.g., error rate spikes by more than 2%), an automated rollback mechanism should be triggered immediately to reroute all traffic back to the stable version.
- Segment Your Audience: Start the rollout with low-risk user segments. Service mesh tools like Istio or Linkerd can route traffic based on HTTP headers, allowing you to target internal users (
X-Internal-User: true) or users in a specific geographic region before expanding to a wider audience.
Organizations like Google use canary releases for Chrome browser updates, and Netflix gradually rolls out new recommendation algorithms to subsets of users. These tech giants demonstrate how canary deployments can facilitate rapid innovation while maintaining exceptional system reliability and a positive user experience.
4. Infrastructure as Code (IaC)
A pivotal best practice for software deployment is managing infrastructure through code. Infrastructure as Code (IaC) is the practice of provisioning and managing computing infrastructure (like servers, databases, and networks) using machine-readable definition files, rather than manual configuration. This approach treats infrastructure with the same discipline as application code, enabling versioning, automated testing, and repeatable deployments, which eliminates configuration drift and ensures consistency across environments.
How IaC Transforms Infrastructure Management
The process begins when an engineer defines the desired state of their infrastructure in a declarative language like HCL (HashiCorp Configuration Language) for Terraform or YAML for Kubernetes manifests. This code is stored in a version control system such as Git, providing a single source of truth and a complete audit trail of all changes.
- Declarative Provisioning: Tools like Terraform, Pulumi, or AWS CloudFormation read these definition files and automatically provision the specified resources in the target cloud or on-premise environment. The tool manages the state, understanding what resources currently exist and calculating the necessary changes (create, update, or destroy) to match the desired state. For example, a Terraform plan (
terraform plan) shows a preview of changes before they are applied. - Immutable Infrastructure: IaC promotes the concept of immutable infrastructure, where servers are never modified after deployment. Instead of patching a running server, a new server is built from an updated image (e.g., an AMI built with Packer) defined in code, tested, and swapped into the production pool. This drastically reduces configuration errors and simplifies rollbacks.
By codifying infrastructure, teams achieve unprecedented speed and reliability. Companies like Uber leverage Terraform to manage complex, multi-cloud infrastructure, while NASA uses Ansible playbooks for automated configuration management. This practice is foundational for scalable DevOps because it makes infrastructure provisioning a predictable, automated part of the CI/CD pipeline. Implementing Infrastructure as Code necessitates robust IT infrastructure management practices. Learn more about effective IT infrastructure management to build a solid foundation.
5. Automated Testing in Deployment Pipeline
Automated testing is the practice of integrating a comprehensive suite of tests directly into the deployment pipeline to validate code quality at every stage. This approach systematically catches bugs, regressions, and performance issues before they can impact users, serving as a critical quality gate. By automating unit, integration, functional, and performance tests, teams can move with speed and confidence, knowing that a safety net is in place. This makes automated testing one of the most essential best practices for software deployment, as it directly underpins the reliability and stability of the entire release process.
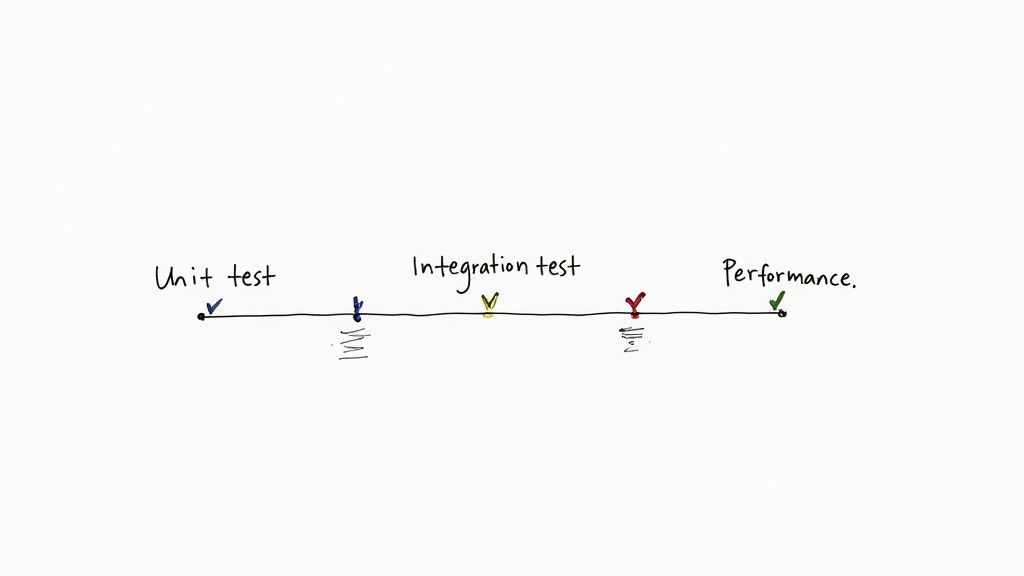
This process ensures that every code commit is rigorously vetted, transforming quality assurance from a manual, end-of-cycle bottleneck into a continuous, automated activity. Successful implementation, like at Google or Microsoft, involves building a culture where developers own the quality of their code by writing and maintaining tests alongside their features.
How to Implement Automated Testing Effectively
Integrating automated tests requires a strategic approach that balances test coverage with pipeline speed. The goal is to maximize defect detection without creating an overly slow feedback loop for developers.
- Implement the Testing Pyramid: Structure your tests according to the classic pyramid model. Focus on a large base of fast, isolated unit tests (e.g., using Jest or JUnit), a smaller layer of integration tests that verify component interactions (e.g., testing a service and its database in a Docker Compose setup), and a very small number of comprehensive end-to-end (E2E) tests for critical user workflows (e.g., using Cypress or Selenium).
- Parallelize Test Execution: To keep the pipeline efficient, run independent tests in parallel. Most CI/CD platforms like Jenkins, GitLab CI, and GitHub Actions support test sharding and parallel execution, which can reduce a 40-minute test suite down to 10 minutes by running it across four parallel jobs.
- Manage Test Environments and Data: Ensure your testing environments are consistent and closely mirror production. Use IaC to spin up ephemeral test environments for each pull request. For test data, use libraries like Faker.js to generate realistic data or tools like Testcontainers to spin up real dependencies like databases in a controlled, isolated manner. For microservices, consider contract testing with a tool like Pact to validate API interactions without needing to spin up every dependent service.
6. Feature Flags and Toggle Management
Feature flags, also known as feature toggles, are a powerful technique that decouples code deployment from feature release. This practice allows teams to turn specific functionalities on or off during runtime without deploying new code. By wrapping new features in a conditional block (a flag), developers can deploy dark code to production safely. This approach is a cornerstone among the best practices for software deployment because it dramatically reduces the risk associated with releases and enables more dynamic, controlled rollouts.
How Feature Flags Work
The core concept involves a centralized configuration service that the application queries to determine whether a feature should be enabled for a specific user, a group of users, or globally. This allows for dynamic control over application behavior without code changes.
- Decoupled Releases: Code can be deployed to production long before it is ready for users. The feature remains "off" until it is complete and has been tested in the production environment by internal teams. This eliminates the need for long-lived feature branches, reducing merge conflicts.
- Controlled Rollouts: Instead of a high-risk "big bang" release, features can be gradually rolled out. A team might enable a feature for 1% of users, then 10%, then 50%, monitoring for issues at each stage. This is often called a percentage-based rollout.
- A/B Testing and Experimentation: Flags enable running experiments by showing different versions of a feature to different user segments. This provides valuable data to make informed product decisions. For example,
if (featureFlags.isNewCheckoutEnabled(userId)) { // show new checkout } else { // show old checkout }.
Pioneered by companies like Flickr and Facebook for continuous deployment and gradual rollouts, this methodology is now widely adopted. GitHub, for example, uses feature flags to test new functionality with internal staff and a small subset of users before a full public release. For a deeper dive into implementation strategies, you can learn more about feature flag best practices on opsmoon.com. Proper management, including regular cleanup of old flags to prevent technical debt, is crucial for long-term success with this powerful deployment strategy.
7. Monitoring and Alerting
Deploying software successfully is only half the battle; ensuring it performs as expected in production is equally critical. Comprehensive monitoring and alerting provide the necessary visibility into an application's health and behavior post-deployment. This practice involves setting up systems to track key performance indicators (KPIs), infrastructure metrics, and user experience data in real-time. By establishing automated alerts for anomalies, teams can proactively identify and address issues before they impact users, making this a non-negotiable component of modern software deployment.
How to Implement Effective Monitoring
A robust monitoring strategy begins with identifying what to measure. The Google SRE team popularized the "Four Golden Signals" as a starting point for monitoring any user-facing system. These signals provide a high-level overview of system health and serve as a foundation for more detailed observability.
- Latency: The time it takes to service a request. Monitor the P95 and P99 latencies for key API endpoints, not just the average.
- Traffic: A measure of demand on your system, typically measured in requests per second (RPS) for web services.
- Errors: The rate of requests that fail, either explicitly (e.g., HTTP 5xx status codes) or implicitly (e.g., a 200 OK response with malformed JSON). Monitor this as a percentage of total traffic.
- Saturation: How "full" your service is, focusing on its most constrained resources like CPU, memory, or database connection pool utilization. A common metric is queue depth for asynchronous workers.
By instrumenting your application to collect these metrics using libraries like Prometheus client or OpenTelemetry and feeding them into platforms like DataDog, New Relic, or a Prometheus/Grafana stack, you can build dashboards that provide immediate feedback during and after a deployment. A sudden spike in the error rate or P99 latency right after a release is a clear indicator that the new code has introduced a problem, triggering an automated alert to an on-call engineer via PagerDuty. For a deeper dive into setting up these systems, you can learn more about infrastructure monitoring best practices.
8. Database Migration and Schema Versioning
While application code deployments have become highly automated, database changes often remain a source of significant risk and downtime. Database migration and schema versioning addresses this challenge by treating database changes with the same rigor as application code. This practice involves managing and applying database schema modifications through a series of version-controlled, incremental scripts, ensuring that the database state is consistent, repeatable, and aligned with the application version across all environments. This is a critical component among the best practices for software deployment as it decouples database evolution from application deployment risk.
How Database Migrations Work
The core idea is to codify every database schema change (like adding a table, altering a column, or creating an index) into a script. These scripts are versioned alongside the application code in a source control system. An automated migration tool (like Flyway, Liquibase, or the migration tool built into a framework like Django) then applies these scripts in a specific order to bring the database schema from its current version to the desired new version.
- Version Control: Each migration script is given a unique, sequential version number (e.g.,
V1__Create_users_table.sql). The database maintains a special table (e.g.,schema_version) to track which migrations have already been applied. - Automated Execution: During the deployment pipeline, the migration tool checks the database's current version and automatically applies any pending migration scripts in sequential order to bring it up to date before the new application code is deployed.
- Rollback Capability: Each migration script should ideally have a corresponding "down" script that can reverse its changes, allowing for controlled rollbacks if a deployment fails. For zero-downtime deployments, favor additive, backward-compatible changes (e.g., add a new column but make it nullable) over destructive ones.
This systematic process prevents manual database errors and ensures that every environment is running a consistent schema. For instance, tools like GitHub's gh-ost and Percona's pt-online-schema-change enable large-scale, zero-downtime migrations on massive tables by performing changes on a copy of the table and then swapping it into place. This structured approach is essential for any application that requires high availability and data integrity.
9. Configuration Management
Effective configuration management is a critical practice that involves systematically handling application and infrastructure settings. This approach decouples configuration from the codebase, allowing for dynamic adjustments across different environments like development, staging, and production without requiring code changes. As one of the core best practices for software deployment, it ensures that an application's behavior can be modified reliably and securely, which is essential for building scalable and maintainable systems. Adhering to this principle prevents sensitive data from being hardcoded and simplifies environment-specific deployments.
How Configuration Management Works
The fundamental principle of modern configuration management is to store configuration in the environment, a concept popularized by the Twelve-Factor App methodology. Instead of embedding settings like database credentials, API keys, or feature flags directly into the code, these values are supplied externally to the application at runtime. This separation provides several key benefits, including improved security and enhanced portability between environments.
Key techniques and tools for implementing this practice include:
- Environment Variables: For simple configurations, using environment variables is a straightforward and platform-agnostic method. They can be easily set in container orchestration platforms like Kubernetes (via
envin the pod spec) or loaded from.envfiles for local development. - Centralized Configuration Services: For complex systems, especially microservices architectures, centralized services like HashiCorp Vault for secrets, AWS Parameter Store, or Azure App Configuration provide a single source of truth. These tools manage configuration for all services, support dynamic updates without a restart, and encrypt secrets at rest.
- Configuration Validation: At startup, the application should validate its required configuration using a library like Pydantic (Python) or Viper (Go). If a necessary variable is missing or malformed, the application should fail fast with a clear error message, preventing runtime failures in production.
This systematic approach makes deployments more predictable and less error-prone. For instance, many organizations leverage Kubernetes ConfigMaps for non-sensitive configuration data and Secrets (often populated from a tool like Vault) to inject configuration and sensitive information into their application pods, cleanly separating operational concerns from application logic. By adopting these strategies, teams can ensure their deployment process is both flexible and secure.
Best Practices Deployment Comparison
| Item | Implementation Complexity | Resource Requirements | Expected Outcomes | Ideal Use Cases | Key Advantages |
|---|---|---|---|---|---|
| Continuous Integration and Continuous Deployment (CI/CD) | High – initial setup and cultural shift | Moderate – automation tools, robust testing | Faster delivery, higher code quality | Frequent releases, collaborative teams | Automated pipelines, quick rollback, fast feedback |
| Blue-Green Deployment | Moderate – managing dual environments | High – double infrastructure needed | Zero downtime, reduced deployment risk | High-availability systems | Instant traffic switch, easy rollback |
| Canary Deployment | High – complex traffic and monitoring | Moderate – advanced monitoring and traffic control | Early issue detection, gradual rollout | Risk-sensitive deployments | Reduced blast radius, real user feedback |
| Infrastructure as Code (IaC) | Moderate to High – learning curve for tools | Moderate – automation infrastructure | Consistent, repeatable infrastructure provisioning | Multi-cloud, scalable infrastructure | Version control, faster provisioning, reduced errors |
| Automated Testing in Deployment Pipeline | High – test automation setup and maintenance | Moderate to High – test environments and tools | Early defect detection, improved quality | Ensuring code quality in CI/CD | Fast feedback, consistent tests, quality gates |
| Feature Flags and Toggle Management | Moderate – requires flag lifecycle management | Low to Moderate – runtime controls | Safer, decoupled feature releases | Gradual rollouts, A/B testing | Quick rollback, controlled experiments |
| Monitoring and Alerting | Moderate – complex setup and tuning | Moderate to High – metrics storage and tools | Faster incident response, improved reliability | Production systems requiring stability | Real-time metrics, alert automation |
| Database Migration and Schema Versioning | Moderate – coordination and tooling | Low to Moderate – migration scripts and backups | Consistent database state, safe rollbacks | Frequent schema changes | Versioned changes, automated migrations |
| Configuration Management | Moderate – managing environment configs | Low to Moderate – config stores and validation | Environment consistency, easier deployments | Multi-environment setups | Dynamic updates, externalized secrets |
Synthesizing Your Strategy for Elite Deployment Performance
Navigating the complex landscape of modern software delivery requires more than just good code; it demands a strategic, disciplined approach to deployment. Throughout this guide, we have explored a comprehensive suite of practices designed to transform your release process from a source of anxiety into a competitive advantage. These are not isolated tactics but interconnected components of a holistic system, each reinforcing the others to build a resilient, predictable, and highly efficient delivery pipeline.
Moving beyond theory, the true value of these best practices for software deployment emerges when they are synthesized into a cohesive strategy. Your CI/CD pipeline is the automated backbone, but its effectiveness is magnified by the risk mitigation strategies of blue-green and canary deployments. Infrastructure as Code (IaC) provides the stable, version-controlled foundation upon which these automated processes run, ensuring consistency from development to production.
From Individual Tactics to a Unified System
The journey to deployment excellence is not about adopting every practice overnight. Instead, it's about understanding how these elements work in concert to create a virtuous cycle of improvement.
- Automation as the Foundation: CI/CD pipelines (Item 1) and IaC with tools like Terraform or Pulumi (Item 4) are the non-negotiable starting points. They eliminate manual toil and create a repeatable, auditable process that serves as the bedrock for all other practices.
- De-risking the Release: Progressive delivery techniques like blue-green (Item 2) and canary deployments (Item 3) are your primary tools for minimizing the blast radius of a failed release. They allow you to validate changes with a subset of users before committing to a full rollout, turning deployments into controlled experiments rather than all-or-nothing events.
- Building Inherent Quality Gates: Automated testing (Item 5) is the immune system of your pipeline. Integrating unit, integration, and end-to-end tests ensures that code quality is continuously validated, catching regressions and bugs long before they impact users. This is not a post-deployment activity; it is an integral gate within the deployment process itself.
- Decoupling Deployment from Release: Feature flags (Item 6) represent a paradigm shift. By separating the technical act of deploying code from the business decision of releasing a feature, you empower product teams, reduce merge conflicts, and enable safer, more frequent deployments.
- Closing the Feedback Loop: A deployment is not "done" when the code is live. Comprehensive monitoring and alerting (Item 7) provide the real-time visibility needed to understand application performance and user impact. This data is the critical feedback that informs your rollback decisions and validates the success of a release.
Your Actionable Path Forward
Adopting these best practices for software deployment is an iterative journey, not a destination. The goal is to cultivate a culture of continuous improvement where deployments become a routine, low-stress, and frequent activity that accelerates innovation. Start by assessing your current state and identifying the most significant bottleneck or source of risk in your process.
Is it manual infrastructure provisioning? Begin with IaC. Are releases causing frequent downtime? Implement a blue-green strategy. Is your team afraid to deploy? Introduce feature flags to build confidence. By focusing on one area at a time, you can build momentum and demonstrate value, making the case for broader adoption. Ultimately, mastering these practices means transforming your engineering organization into a high-velocity, quality-driven engine capable of delivering exceptional value to your users, reliably and at scale.
Ready to implement these advanced strategies but lack the specialized in-house expertise? OpsMoon connects you with the world's top 0.7% of elite, remote DevOps and SRE engineers who specialize in architecting and optimizing these exact systems. Let us help you build a world-class deployment pipeline by visiting OpsMoon to schedule a free work planning session today.