A Technical Guide to Service Reliability Engineering
 By opsmoon
By opsmoonA technical guide to Service Reliability Engineering (SRE). Learn core principles, SLIs/SLOs, and how to implement SRE to build resilient systems.
Traditional IT operations often devolve into a reactive cycle of firefighting: an alert fires, a team scrambles, and everyone hopes for the best until the next incident. This approach is stressful, unscalable, and inefficient. Service reliability engineering (SRE) offers a fundamentally different paradigm.
SRE applies a software engineering discipline to infrastructure and operations problems. The core principle is to treat operations as a software engineering challenge. This means systematically engineering reliability into systems from the ground up, rather than treating it as an afterthought.
What Is Service Reliability Engineering?
Service Reliability Engineering (SRE) is not just a rebranding of an operations team; it's a profound cultural and procedural shift. It dismantles the traditional model where a development team builds features and an operations team manages the resulting failures. In an SRE model, reliability is a core feature, and its implementation is a shared responsibility.
The analogy is civil engineering. One wouldn't construct a bridge by placing planks over a canyon and hoping they hold. An engineer calculates load capacities, analyzes material stress points, and defines precise failure tolerances. Reliability is designed in from the outset.
SRE applies this same engineering rigor to the complex and dynamic environment of running large-scale software services.
A Data-Driven Approach to Reliability
At its heart, service reliability engineering replaces subjective operational goals with quantitative, data-driven metrics. It forces engineering teams to define, measure, and manage reliability with numerical precision. What does "reliability" mean for a specific service? How is it measured? What is the acceptable threshold for failure?
"SRE is what you get when you treat operations as a software problem." – Ben Treynor Sloss, VP of Engineering, Google
This foundational definition from the creator of SRE emphasizes a shift from manual intervention to automated solutions. This approach inherently leads to several key outcomes:
- Automating Toil: Any manual, repetitive, and automatable operational task—termed "toil"—is systematically identified and eliminated through software solutions. This frees engineers to focus on high-value, long-term engineering problems.
- Decisions Backed by Data: Intuition is replaced by evidence. Decisions regarding feature rollouts, maintenance windows, or incident response strategies are driven by explicit reliability metrics and error budgets.
- Breaking Down Silos: The "wall of confusion" between developers and SREs is dismantled. Both teams share ownership of a service's reliability, aligning their incentives and fostering collaboration toward common, data-defined goals.
The Core Principles of SRE
The effectiveness of SRE is rooted in a set of core principles that provide a universal framework for building and operating dependable systems. These principles guide every technical and strategic decision.
Here is a breakdown of the pillars that constitute the SRE discipline.
Core SRE Principles Explained
| SRE Principle | Core Concept | Practical Application |
|---|---|---|
| Embrace Risk | Achieving 100% reliability is an anti-pattern; its cost is prohibitive and it stifles innovation. SRE defines an acceptable level of unreliability and manages against that target. | Creating an Error Budget—a quantifiable measure of permissible downtime or performance degradation (e.g., in minutes or number of failed requests) over a defined period. |
| Set Service Level Objectives (SLOs) | Transition from ambiguous promises to specific, measurable, data-driven targets for service performance and availability. | Defining an SLO such as "99.9% of login API requests, measured at the load balancer, will complete with a 2xx status code in under 200ms over a rolling 30-day window." |
| Eliminate Toil | Toil is manual, repetitive, tactical work with no enduring value. The goal is to keep toil below 50% of an engineer's time by automating it away. | Writing a Python script using a cloud provider's SDK to automate the provisioning and configuration of a new database replica, replacing a multi-step manual process. |
| Automate Everything | Apply software engineering practices to solve operational problems. The objective is to build systems that are self-healing, self-scaling, and self-managing. | Implementing a Kubernetes Horizontal Pod Autoscaler that automatically scales web server deployments based on CPU utilization metrics, eliminating manual intervention during traffic spikes. |
| Measure Everything | You cannot improve what you do not measure. Comprehensive monitoring and observability are prerequisites for effective SRE. | Implementing detailed instrumentation using a tool like Prometheus to track latency, traffic, errors, and saturation (the "Four Golden Signals") for every microservice. |
| Share Ownership | Developers and SREs are mutually accountable for a service's reliability, performance, and scalability throughout its entire lifecycle. | Developers participate in the on-call rotation for the services they build and are required to lead the post-mortem analysis for incidents involving their code. |
These principles are not isolated concepts; they form an integrated system. SLOs are used to calculate the Error Budget, which quantifies acceptable risk. To meet these SLOs, automation is used to eliminate toil, and the entire process is guided by comprehensive measurements and a culture of shared ownership.
Redefining Operations with Engineering
By operationalizing these principles, SRE redefines IT operations. It shifts the focus from reactive firefighting to proactive, preventative engineering, emphasizing modern operational practices. The outcomes are measurable: reduced mean time to recovery (MTTR), improved user satisfaction, and increased trust in your platform.
In an increasingly complex digital landscape with escalating user expectations, a structured, engineering-led approach to reliability is not a luxury—it is a competitive necessity. To see these principles in practice, explore our guide on implementing SRE services and observe how these concepts translate into real-world strategies.
The Technical Pillars of SRE
To implement SRE effectively, you must move beyond abstract goals and adopt a framework built on quantitative, verifiable data. This is the primary differentiator between SRE and traditional IT operations. This framework is constructed upon three interdependent concepts: Service Level Indicators (SLIs), Service Level Objectives (SLOs), and Error Budgets.
Consider this the instrumentation for flying a complex aircraft. A pilot relies on an altimeter, airspeed indicator, and fuel gauge—not intuition. For an SRE, SLIs, SLOs, and Error Budgets are the critical instruments for navigating the complexities of maintaining a healthy, available service.
Defining Service Level Indicators
A Service Level Indicator (SLI) is a direct, quantitative measure of a specific aspect of your service's performance. It is raw data, a factual statement about your system's behavior at a point in time. An SLI is not a goal; it is a measurement.
Effective SLIs must measure what the user experiences. Internal metrics like CPU utilization or memory pressure are poor SLIs because they do not directly reflect the user's journey. A good SLI focuses on user-centric outcomes.
Technically, a good SLI is often expressed as a ratio of good events to the total number of valid events. Common examples include:
- Availability:
(Number of successful HTTP requests [e.g., 2xx/3xx status codes]) / (Total number of valid HTTP requests). This is typically measured at the load balancer. - Latency:
(Number of requests served faster than a threshold) / (Total number of valid requests). For example, the proportion of requests completed in under 300ms. This is often measured as a percentile (e.g., 95th or 99th). - Quality:
(Number of API calls returning a complete, uncorrupted payload) / (Total number of valid API calls). This can be measured by having the client or a monitoring agent validate the response payload against a schema.
Clear documentation is essential for SLIs to be effective. Every engineer must understand precisely what each SLI measures and why it matters. For guidance on creating this clarity, review these technical writing best practices.
This infographic illustrates the feedback loop created by these concepts.
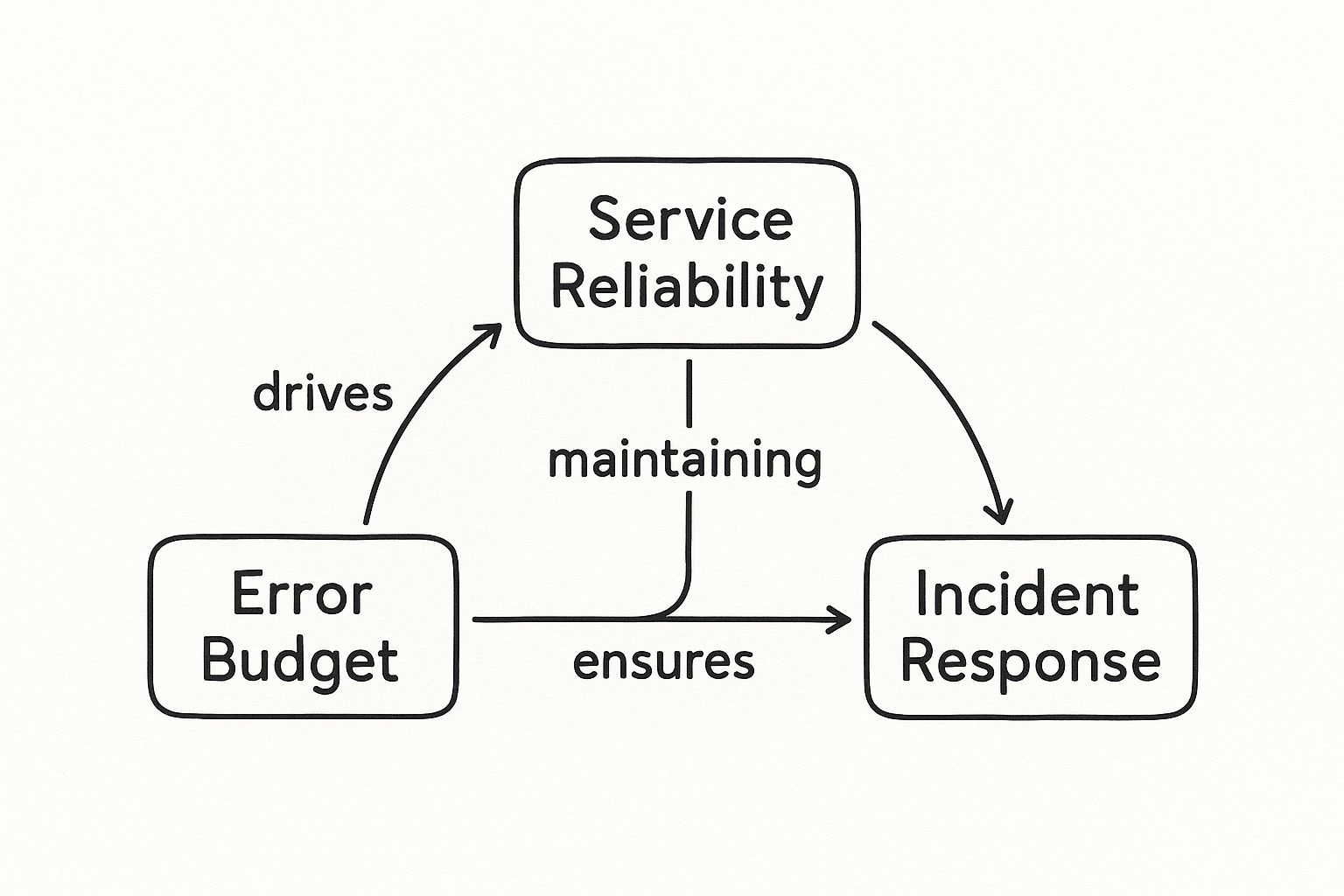
The error budget serves as the automated trigger for action, which in turn preserves the long-term reliability defined by the SLO.
Setting Service Level Objectives
With well-defined SLIs, the next step is to set a Service Level Objective (SLO). An SLO is a target value or range for an SLI, measured over a specific time window. This is where you numerically define "reliable enough" for your service.
An SLO is a data-backed promise to your users. It is a specific, negotiated agreement on the level of reliability a service is expected to deliver.
Crucially, an SLO is never 100%. Pursuing perfection is an anti-pattern that stifles innovation and leads to diminishing returns. A well-designed SLO balances user happiness with the engineering team's need to innovate and deploy new features.
For example, a robust SLO might be: "99.95% of payment processing API requests will return a success code (HTTP 200) within 500ms, as measured over a rolling 28-day window."
Calculating the Error Budget
The direct mathematical consequence of an SLO is your Error Budget. If your SLO defines 99.95% reliability, your error budget is the remaining 0.05%. This is the acceptable quantity of unreliability you are permitted to "spend" over the SLO's time window without violating your user promise.
Let's operationalize this with a concrete example. Consider a payment API handling 10,000,000 transactions per quarter.
- Select the SLI: The percentage of API calls that successfully process a transaction and return a
200 OKstatus. - Define the SLO: The product and engineering teams agree that 99.9% of transactions must succeed each quarter.
- Calculate the Error Budget:
100% - 99.9% = 0.1%(This is the acceptable failure rate).0.1% * 10,000,000 transactions = 10,000 transactions.
The team now has a concrete error budget of 10,000 failed transactions for the quarter. This number becomes a critical input for data-driven decision-making. As long as the budget is positive, the team is empowered to release new features and take calculated risks. If the budget is exhausted, a pre-agreed policy takes effect: all new feature development ceases, and the team's sole priority becomes improving reliability until the service is back within its SLO.
Balancing Feature Velocity and System Stability
Every engineering organization faces a fundamental tension: the business demand for rapid feature delivery versus the operational need for system stability. Leaning too far in either direction creates problems—either stagnant product development or an unreliable user experience.
This is precisely the conflict that service reliability engineering is designed to resolve. Instead of relying on subjective arguments or political influence, SRE introduces a neutral, data-driven arbiter: the error budget.
The Error Budget as the Final Arbiter
The error budget is more than a metric; it is a governance tool. It represents a pre-negotiated agreement among product, development, and operations stakeholders on the acceptable level of risk. This transforms the conversation about release readiness from a subjective debate into an objective, data-based decision.
The rule is mechanically simple. If a service's performance (as measured by its SLIs) is better than its SLO, you have a positive error budget. This budget is your quantified permission to take risks. A healthy budget signals a green light for innovation, empowering developers to deploy new code, conduct A/B tests, and perform system upgrades, knowing a safety margin exists for minor, acceptable failures.
This framework directly addresses the friction between speed and stability. Despite advancements in automation, operational toil has reportedly increased, indicating that tools alone do not solve this core conflict. You can find more data on this in The SRE Report 2025, which highlights critical trends in site reliability engineering. The error budget provides a robust mechanism to manage this tension.
When the Budget Runs Out
The power of the error budget is most evident when it is exhausted. When incidents, latency regressions, or other issues cause the service to breach its SLO, the budget is consumed. When it reaches zero, it should trigger an automated, non-negotiable policy.
A depleted error budget acts as an automated circuit breaker for new feature releases. It forces a hard stop on shipping new functionality and mandates an immediate pivot to focus exclusively on reliability.
Once the budget is spent, the development team's priorities are automatically re-aligned. All engineering effort is redirected toward activities that restore service health and replenish the budget. This typically involves:
- Bug Fixes: Prioritizing the resolution of issues that directly contributed to the budget burn.
- Performance Optimization: Profiling and tuning code paths causing latency.
- Toil Reduction: Automating manual procedures that introduced risk or errors.
- Monitoring Enhancements: Improving alert precision and dashboard visibility to detect issues earlier.
This hard stop removes emotion and politics from the decision-making process. The data, via the error budget policy, makes the call.
Fostering a Culture of Shared Ownership
This data-driven approach profoundly impacts team culture. By directly tying the freedom to release new features to the health of the error budget, SRE creates a system of shared ownership. Developers and operations engineers are now aligned, both incentivized to protect the service's reliability.
Developers quickly learn that high-quality, well-tested code that adheres to the SLO is the fastest path to continuous delivery. They begin to consider the operational implications of their code as a primary concern. Conversely, SREs are motivated to build robust platforms and tooling that make it easy for developers to build reliable software by default.
The error budget becomes a shared resource that all stakeholders are responsible for managing. When it is healthy, everyone benefits. When it is depleted, everyone shares the responsibility of restoring it. This collaborative model is a cornerstone of a mature service reliability engineering practice.
A Phased Roadmap to Implementing SRE
Adopting service reliability engineering is an incremental process, not a sudden transformation. The most successful SRE adoptions build on a series of small, concrete wins that create momentum and demonstrate value.
This roadmap is designed to guide a team from foundational concepts to a mature, proactive reliability practice.
Phase 1: Establish Baseline Reliability
Your journey begins with selecting a suitable pilot service. Attempting a broad, simultaneous rollout of SRE across your entire architecture is a common and costly mistake.
Choose a single, user-facing service that is business-critical enough for improvements to be meaningful, but not so fragile that experimentation is impossible. A new feature's backend API or an internal authentication service are often ideal candidates.
With your pilot service chosen, the objective is to establish a data-driven baseline of its health. This requires two key actions:
- Instrument the Service: Implement monitoring to collect meaningful Service Level Indicators (SLIs). Focus on user-centric metrics like request latency, error rate, and application throughput. Avoid infrastructure-level metrics like CPU usage, which do not directly represent the user experience.
- Define Initial SLOs: With SLI data available, collaborate with product owners to define your first Service Level Objectives (SLOs). Set realistic and achievable targets initially; they can be tightened over time. A good starting SLO might be: "99.5% of API requests should complete successfully over a 7-day period."
The outcome of this phase is clarity: an objective, numerical definition of what "good enough" performance looks like for that service.
Phase 2: Introduce Error Budgets and On-Call
With your first SLOs defined, it's time to make them actionable. This phase turns reliability targets into a practical tool for decision-making and incident management via the error budget.
Your error budget is the inverse of your SLO. An SLO of 99.5% availability yields an error budget of 0.5%. This is your quantifiable allowance for failure. To make this effective, you must create an error budget policy—a clear, documented agreement on the consequences of consuming the budget.
For example, a policy might state: "If more than 75% of the weekly error budget is consumed, all new feature deployments to this service are frozen for the remainder of the week. All engineering effort must pivot to reliability work."
This policy empowers the team to protect reliability without political debate. It also necessitates a structured on-call rotation. A sustainable SRE on-call practice includes:
- Defined Playbooks: Create step-by-step technical guides for diagnosing and mitigating common alerts. No engineer should be guessing at 3 AM.
- Shared Responsibility: The software engineers who build the service must participate in the on-call rotation for it, fostering a "you build it, you run it" culture.
- Sustainable Rotations: Implement short on-call shifts with adequate recovery time to prevent burnout, which is a direct threat to reliability.
Phase 3: Automate Toil and Institute Blameless Postmortems
With an SLO-driven incident response process in place, the next step is to reduce the frequency and impact of those incidents. This phase focuses on learning from failure and automating manual work—two pillars of service reliability engineering.
First, establish a formal process for blameless postmortems following every significant incident. The objective is not to assign blame but to perform a root cause analysis of the systemic issues and contributing factors that allowed the failure to occur. Every postmortem must conclude with a list of concrete, tracked action items to mitigate the risk of recurrence.
Simultaneously, aggressively identify and eliminate toil. Toil is any operational task that is manual, repetitive, and automatable. A core SRE principle dictates that engineers should spend no more than 50% of their time on toil.
- How to Spot Toil: Conduct a "toil audit." Have engineers track time spent on tasks like manual deployments, password resets, provisioning virtual machines, or restarting a database.
- How to Kill It: Prioritize engineering effort to automate these tasks using scripts, internal tools, or infrastructure-as-code platforms like Terraform or Ansible.
This creates a virtuous cycle: postmortems identify systemic weaknesses, and the engineering time reclaimed from automating toil provides the capacity to implement permanent fixes.
Phase 4: Embrace Proactive Reliability
This final phase represents the transition from a reactive to a proactive reliability posture. Your team no longer just responds to failures; it actively seeks to discover and remediate weaknesses before they impact users. The primary tool for this is Chaos Engineering.
Chaos Engineering is the disciplined practice of conducting controlled experiments to inject failure into your systems, thereby verifying your assumptions about their resilience. It is how you build confidence that your system can withstand turbulent real-world conditions.
Begin with small, controlled experiments in a staging environment:
- Latency Injection: What is the impact on your service if a critical dependency, like a database, experiences a 300ms increase in response time?
- Instance Termination: Does your service gracefully handle the sudden termination of a node in its cluster, or does it suffer a cascading failure?
- Resource Exhaustion: How does your application behave under CPU or memory starvation?
The findings from these experiments become direct inputs into your development backlog, enabling you to build more resilient systems by design. This is the hallmark of a mature service reliability engineering practice: reliability is not an accident but a direct result of deliberate, focused engineering.
Advanced SRE and Incident Management

This is the stage of SRE maturity where the practice shifts from reacting to outages to proactively engineering resilience. It involves intentionally stress-testing for failure and learning from every incident with rigorous discipline.
Practices like Chaos Engineering and blameless postmortems are what distinguish a good SRE culture from a great one. They transform the team's mindset from merely "keeping the lights on" to building anti-fragile systems—systems designed not just to survive but to improve from the chaos of production environments.
Proactive Failure Testing with Chaos Engineering
Chaos Engineering is the practice of running controlled, well-planned experiments designed to reveal system weaknesses before they manifest as customer-facing incidents. It applies the scientific method to system reliability.
You begin with a hypothesis about your system's behavior under specific failure conditions, inject that failure in a controlled manner, and observe the outcome.
The goal is to proactively discover hidden failure modes. However, there is a significant adoption gap in the industry. One analysis found that only 37% of teams regularly conduct chaos engineering exercises, a major disconnect between established best practices and daily operations. You can discover more insights from the SRE report for a complete analysis.
Designing Your First Chaos Experiment
A successful chaos experiment is precise and follows a clear structure:
- Define a Steady State: First, establish a quantifiable baseline of "normal" behavior using your SLIs. For instance, "The API's p95 latency is consistently below 250ms, and the error rate is below 0.1%."
- Formulate a Hypothesis: State a specific, falsifiable prediction. For example, "If we inject an additional 100ms of latency into the primary database connection, p95 API latency will increase but remain below our 400ms SLO, and the error rate will not increase."
- Inject the Failure: Introduce the variable using a chaos engineering tool. This could involve killing a pod, simulating a dependency outage, or adding network latency with
tc. Always start in a non-production environment. - Measure and Verify: Monitor your observability dashboards. Was the hypothesis correct, or did an unexpected failure mode emerge? Did your monitoring and alerting systems function as expected?
- Learn and Improve: Use the findings to strengthen your system. This may lead to implementing more aggressive timeouts, improving retry logic, or fixing a cascading failure you uncovered.
The Discipline of Blameless Postmortems
When an incident occurs—and it will—the objective must be learning, not assigning blame. A blameless postmortem is a structured, technical investigation focused on identifying the systemic and contributing factors that led to an outage. It operates on the principle that systems, not people, are the root cause of failures.
The primary output of a postmortem is not a document. It is a set of concrete, assigned, and tracked action items that measurably reduce the risk of a similar incident recurring.
To achieve operational excellence, it is critical to adopt effective Incident Management Best Practices that prioritize minimizing mean time to recovery (MTTR) and ensuring a swift, systematic return to normal operations.
This table contrasts the traditional reactive approach with the proactive SRE model.
Reactive vs Proactive Reliability Strategies
| Aspect | Reactive Approach (Traditional Ops) | Proactive Approach (SRE) |
|---|---|---|
| Incident Response | Focus on immediate fix (reboot, rollback). | Focus on understanding the "why" to prevent recurrence. |
| Failure Mindset | Failure is an anomaly to be avoided at all costs. | Failure is an inevitable event to be planned for. |
| Tooling | Primarily monitoring and alerting for when things are broken. | Observability, Chaos Engineering, and automated remediation tools. |
| Improvement Cycle | Fixes are often tactical and localized. | Improvements are strategic, targeting systemic weaknesses. |
| Learning | Informal, often based on tribal knowledge or blame-oriented reviews. | Formalized via blameless postmortems with tracked action items. |
Transitioning to a proactive model is essential for building truly resilient, scalable services.
A Technical Postmortem Template
A robust postmortem follows a consistent template to ensure a thorough analysis.
- Summary: A concise, one-paragraph overview of the incident, its business impact (e.g., SLO breach, user impact), and its duration.
- Lead-up: A timeline of events preceding the incident, including deployments, configuration changes, or traffic anomalies.
- Fault: The specific technical trigger. For example, "A misconfiguration in the Terraform module for the load balancer directed 100% of traffic to a single, under-provisioned availability zone."
- Impact: A data-driven account of the user experience and which SLOs were breached (e.g., "The login availability SLO of 99.9% was breached, with availability dropping to 87% for 25 minutes").
- Detection: How was the incident detected? An automated alert from Prometheus? A customer support ticket? What was the mean time to detect (MTTD)?
- Response: A detailed timeline of key actions taken by the on-call team, from the initial alert to full resolution.
- Root Causes: A list of the underlying systemic issues that allowed the fault to have a significant impact. This should go beyond the immediate trigger.
- Action Items: A checklist of engineering tasks (e.g.,
JIRA-123: Add validation to the CI pipeline for load balancer configuration) with assigned owners and due dates to address the root causes.
Running a DevOps maturity assessment can quickly identify gaps in your incident response process and highlight the value a structured, blameless postmortem culture can provide.
Frequently Asked Technical Questions About SRE
As teams begin their SRE journey, practical questions about implementation invariably arise. This section addresses some of ahe most common technical and organizational questions from engineers and managers adopting SRE.
How Is SRE Different from DevOps?
This is a frequent point of confusion. While SRE and DevOps share common goals—such as automation and breaking down organizational silos—they are not interchangeable.
DevOps is a broad cultural philosophy focused on improving collaboration and communication across the entire software development lifecycle. It defines the "what" and the "why": what we should do (work together) and why (to deliver value to users faster and more reliably).
SRE is a specific, prescriptive engineering discipline that provides a concrete implementation of the reliability aspects of DevOps. If DevOps is the high-level strategy, SRE offers the battle-tested tactics and engineering practices.
Think of it this way: DevOps is the constitution outlining the principles for building and running software. SRE is the specific legal code and implementation framework that enforces those principles, particularly the right to a reliable service, using tools like SLOs and error budgets.
While DevOps addresses the entire delivery pipeline, SRE brings a laser focus to production operations and reliability, treating them as software engineering problems to be solved with data and automation.
Do We Need a Dedicated SRE Team to Start?
No, and in fact, creating a dedicated team prematurely can be counterproductive. You do not need a fully staffed SRE team to begin realizing the benefits of the practice. A grassroots effort within an existing engineering team is often a more effective starting point than a top-down mandate.
SRE is fundamentally a mindset and a set of practices that can be adopted incrementally. The key is to start small and demonstrate tangible value.
Here is a practical, actionable plan to begin without a formal team:
- Select a Pilot Service: Choose one important service as your initial project.
- Define an SLO: Collaborate with the product owner and stakeholders to define one or two meaningful Service Level Objectives (SLOs) for that service.
- Track the Error Budget: Implement a simple dashboard (e.g., in Grafana) to visualize the SLO and its corresponding error budget. Make it highly visible to the entire team.
- Conduct a Postmortem: The next time an incident affects that service, conduct your first blameless postmortem. Focus rigorously on identifying systemic issues and creating actionable follow-up tasks.
This approach builds practical, hands-on expertise and creates internal champions for the SRE practice. Once you have documented success stories with clear reliability improvements, the business case for a dedicated team becomes much stronger. Prioritize adopting the principles first, not the job titles.
What Is Toil and How Do We Quantify It?
In the SRE lexicon, toil has a precise definition. It is not merely "grunt work." For a task to be classified as toil, it must meet specific criteria.
Toil is operational work that is:
- Manual: A human must execute the steps.
- Repetitive: The same task is performed repeatedly.
- Automatable: An engineering solution could perform the task.
- Tactical: It is reactive and lacks enduring value.
- Scales Linearly: The amount of work grows in direct proportion to service growth. If adding 100 new customers requires 100 manual account setups, that is pure toil.
Examples of toil include manually applying a database schema change, SSH-ing into a server to restart a process, or manually provisioning a new virtual machine. This work is detrimental because it consumes engineering time that could be invested in permanent, scalable solutions.
A core SRE principle is that an engineer's time spent on toil should be capped at 50%. Exceeding this limit creates a vicious cycle where there is no time available to build the automation needed to reduce toil.
To quantify it, teams must track the time spent on these tasks. This can be done using tickets in systems like Jira, time-logging tools, or periodic team surveys ("toil audits"). Once measured, it can be managed. The objective is to systematically engineer toil out of existence.
Can SRE Principles Apply to Monolithic Systems?
Absolutely. While SRE gained prominence in the context of large-scale, distributed microservices at companies like Google, its core philosophy is architecture-agnostic. The central tenet—treating operations as a software engineering problem—is universally applicable.
Defining SLIs and SLOs is as critical for a monolithic e-commerce application as it is for a cloud-native microservice. An error budget is an equally potent tool for managing risk and release velocity for an on-premise legacy system. Blameless postmortems and the systematic elimination of toil provide significant value regardless of the technology stack.
The implementation details will differ based on the architecture:
- Automation: For a monolith on bare metal, automation might rely on tools like Ansible or Chef. For a cloud-native application, it would likely involve Terraform and Kubernetes operators.
- Monitoring: Extracting metrics from a monolith might require different agents and logging configurations, but the objective of capturing user-centric SLIs remains identical.
- Deployment: Even with a monolith, deployment safety can be dramatically improved. Adopting CI/CD pipeline best practices is crucial for introducing safer, more automated release cycles for any architecture.
The fundamental shift is cultural and procedural. By defining reliability with data, managing risk with budgets, and applying engineering discipline to operations, you can enhance the stability of any system, monolithic or otherwise.
Ready to build a culture of reliability without the guesswork? At OpsMoon, we connect you with the top 0.7% of DevOps and SRE experts to accelerate your journey. We'll help you define your SLOs, automate away toil, and implement the engineering practices that matter.
Start with a free work planning session to map your path to elite reliability. Find your expert SRE team at OpsMoon.