Master the Release Life Cycle: Key Stages & Technical Best Practices
 By opsmoon
By opsmoonLearn about the release life cycle, its stages, and best practices to optimize your software delivery process effectively.
The release life cycle is the technical blueprint that governs how software evolves from an initial concept to a production-grade application serving users, and how it is maintained and improved over time. It is the essential engineering framework that structures every phase, from architectural planning and coding to automated deployment and operational monitoring.
What Is a Software Release Life Cycle?
The software release life cycle (SRLC) is an engineering process model, not a loose set of guidelines. It's the architectural plan that imposes order on the inherent complexity of software development. Without a defined SRLC, teams operate reactively, leading to release delays, production instability, and technical debt. With one, a complex project becomes a predictable, repeatable, and optimizable engineering process.
The primary objective of the release life cycle is to manage complexity, mitigate deployment risk, and ensure that technical execution is tightly aligned with product requirements. By decomposing the software delivery process into discrete, manageable phases, engineering teams can focus on specific technical objectives at each stage, ensuring critical activities like code review, security scanning, and performance testing are never bypassed.
The Foundational Stages
The SRLC is architected around distinct stages, each with specific inputs, outputs, and quality gates. This structured methodology builds quality into the development process from the outset, rather than treating it as a final, pre-deployment checklist. For a deeper dive into the operational mechanics, review this guide on Application Deployment and Release Management.
At a high level, the process is segmented into five core technical stages:
- Planning: The architectural and scoping phase where functional requirements are translated into a technical specification, user stories, and an engineering roadmap.
- Development: The implementation phase where engineers write, review, and merge code into a central version control repository.
- Testing: The quality assurance (QA) phase where automated tests—unit, integration, and end-to-end—are executed to validate functionality and prevent regressions.
- Deployment: The release phase where the tested software artifact is deployed to the production environment and made available to end-users.
- Maintenance: The operational phase focused on monitoring the application's health, responding to incidents, fixing bugs, and deploying patches.
This diagram illustrates how these stages are logically grouped within the overarching release life cycle.
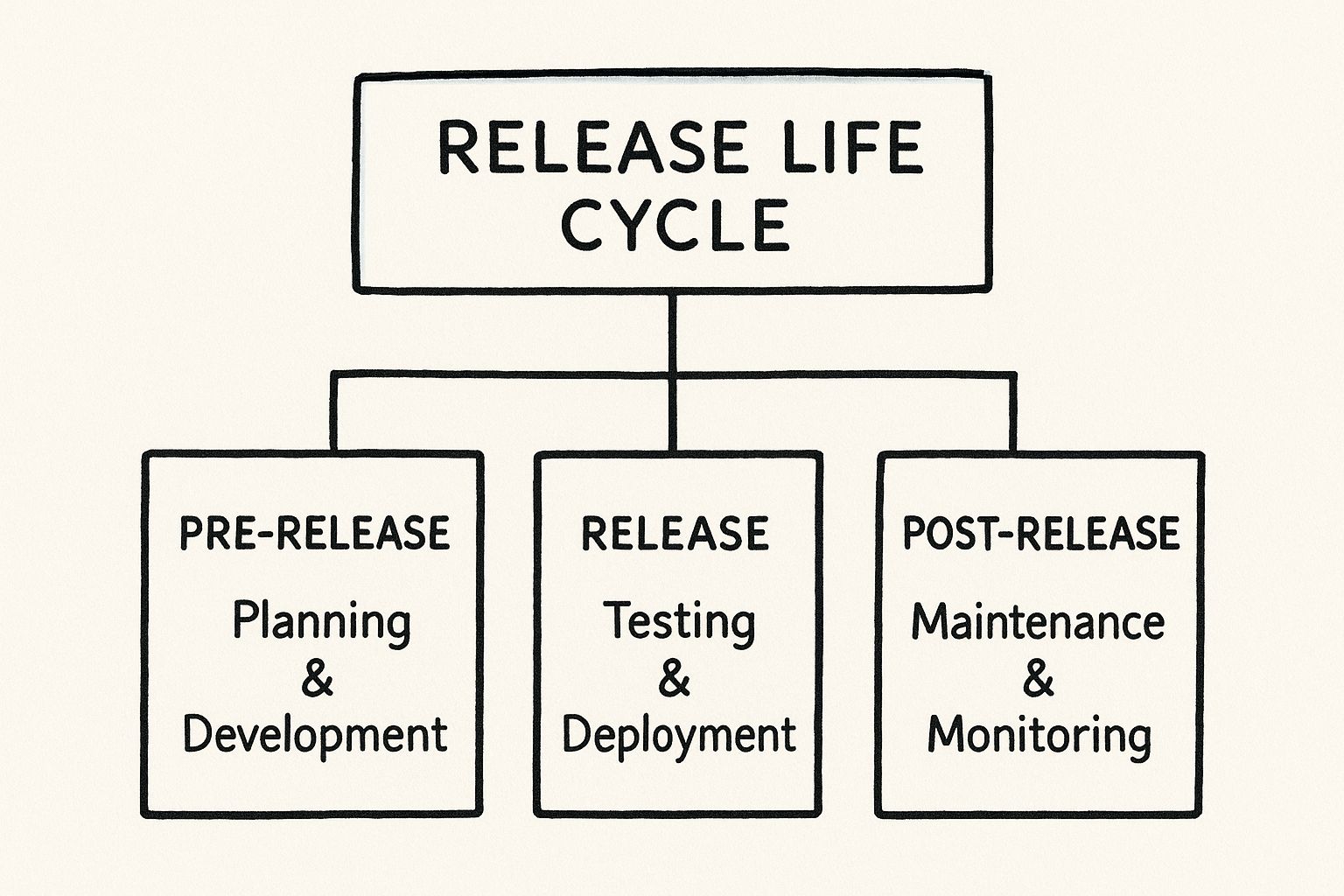
This demonstrates a clear, logical flow: pre-release encompasses all development and testing; the release stage is the deployment event; and post-release is the continuous operational support required to ensure system reliability.
To get a quick overview of the technical activities within each stage, consult the table below.
Core Stages of the Release Life Cycle at a Glance
| Stage | Primary Objective | Key Technical Activities |
|---|---|---|
| Planning | Define technical scope, architecture, and engineering tasks. | Decomposing epics into user stories, technical design, dependency analysis, resource allocation. |
| Development | Implement features according to technical specifications. | Writing code, peer code reviews, adhering to branching strategy (e.g., GitFlow), static code analysis. |
| Testing | Validate code quality and prevent regressions through automation. | Writing unit tests, integration testing against services, E2E testing user flows, security scanning (SAST/DAST). |
| Deployment | Release the application to production safely and reliably. | Building artifacts (e.g., Docker images), running CI/CD pipelines, executing blue-green or canary deployments. |
| Maintenance | Ensure production stability and performance. | Application performance monitoring (APM), log aggregation, incident response, hotfix deployments. |
This table provides a concise summary of the engineering journey from a technical specification to a live, monitored product. Adhering to this structure is what differentiates a disciplined, high-velocity engineering organization from one plagued by chaotic releases.
A Technical Breakdown of Each Release Stage
A well-defined release life cycle is not an abstract framework; it is a sequence of concrete technical executions. Each stage requires specific tools, methodologies, and engineering discipline to function effectively. Let's dissect the five core stages to examine the technical mechanics that drive a release from concept to production.
Stage 1: Planning and Technical Scoping
The planning stage is where technical strategy is defined to meet business objectives. This is more than deciding what to build; it’s about architecting how it will be built and identifying engineering risks before a line of code is written.
A primary output is a well-groomed backlog. In a tool like Jira, this means translating high-level features into granular user stories with explicit, testable acceptance criteria. Each story must be small enough to be completed by a single developer within a sprint, ensuring a continuous flow of work.
Equally critical is the technical risk assessment, which involves:
- Dependency Mapping: Identifying all external API dependencies, third-party libraries, and internal microservices. This analysis informs contract testing and potential performance bottlenecks.
- Complexity Analysis: Evaluating algorithmic complexity (Big O notation) for performance-critical components and identifying areas requiring new technologies or specialized expertise.
- Scalability Projections: Performing back-of-the-envelope calculations for expected load (e.g., requests per second) and designing the system architecture to handle peak capacity without performance degradation.
A robust planning phase is proactive, not reactive. It's where you solve problems on a whiteboard, which is far cheaper and faster than solving them in a production environment.
Stage 2: Development and Version Control
With a technical plan in place, implementation begins. This phase is defined by disciplined coding practices and, most critically, a rigorous version control strategy to manage concurrent contributions from multiple engineers.
The choice of a Git branching strategy is fundamental. A battle-tested model is GitFlow, which provides a structured approach using dedicated branches:
mainbranch: Represents the production-ready state of the codebase. Direct commits are forbidden; changes are only merged from release or hotfix branches.developbranch: Serves as the primary integration branch where all completed feature branches are merged.feature/*branches: Branched fromdevelopfor new, isolated feature development.release/*branches: Created fromdevelopto prepare for a new production release, allowing for final testing and bug fixing.hotfix/*branches: Branched frommainto address critical production bugs, then merged back into bothmainanddevelop.
To maintain code quality, teams enforce coding standards programmatically using linters (like ESLint for JavaScript or Black for Python) and static analysis tools. These are configured as pre-commit hooks to catch issues before code ever reaches the central repository.
Stage 3: Automated Testing and Quality Assurance
The testing stage is where quality assurance is transformed from a manual, error-prone activity into an automated, integral part of the development pipeline. The objective is to create a robust safety net that detects defects early and prevents regressions.
This is achieved by constructing a comprehensive automated test suite.
- Unit Tests: The first line of defense, verifying that individual functions, methods, or components operate correctly in isolation. They are executed on every commit and must be fast.
- Integration Tests: Validate the interaction between different components or services. For example, testing whether an API endpoint correctly fetches data from a database and formats the response.
- End-to-End (E2E) Tests: Simulate real user workflows in a production-like environment. Frameworks like Cypress or Selenium are used to automate browser interactions, verifying critical paths like user authentication or the checkout process.
These tests are integrated into the CI/CD pipeline, acting as automated quality gates. A pull request that breaks any test is automatically blocked from being merged, enforcing a high standard of quality.
Stage 4: Automated Deployment Strategies
Deployment is the technical process of releasing new code to users. Modern deployment strategies focus on minimizing risk and eliminating downtime, replacing the "big bang" releases of the past. Two key technical approaches are dominant.
Blue-Green Deployment
This strategy leverages two identical production environments, designated "Blue" and "Green."
- The "Blue" environment is live, serving 100% of user traffic.
- The new application version is deployed to the "Green" environment, which receives no live traffic.
- Automated tests and health checks are run against the "Green" environment.
- Once validated, the load balancer or router is reconfigured to switch all incoming traffic from "Blue" to "Green."
The key benefit is near-instantaneous rollback. If an issue is detected, traffic can be switched back to the "Blue" environment immediately, minimizing impact.
Canary Deployment
This strategy involves a phased rollout where the new version is gradually exposed to a subset of users.
- The new version (the "canary") is deployed to a small portion of the production infrastructure.
- A small percentage of traffic (e.g., 5%) is routed to the canary.
- Monitoring systems closely observe the canary's error rates, latency, and resource utilization.
- If metrics remain healthy, traffic is incrementally increased until 100% of users are on the new version.
Both strategies are orchestrated within CI/CD platforms like GitLab CI or Jenkins, automating the entire release process. This level of automation is central to modern software delivery, and specialized CI/CD services can accelerate your pipeline development and ensure deployment reliability.
Stage 5: Maintenance and Monitoring
The release life cycle is continuous; it does not end at deployment. The maintenance stage is an ongoing loop of monitoring system health, responding to incidents, and optimizing performance.
Robust Application Performance Monitoring (APM) is essential. Tools like Datadog or New Relic provide deep visibility into application health by tracking key metrics:
- Request latency (p95, p99) and error rates (per endpoint)
- CPU and memory utilization per service
- Database query performance and transaction traces
When production bugs are identified, a formal hotfix process is executed. This typically involves creating a hotfix branch from main, implementing the fix, deploying it immediately, and critically, ensuring the fix is also merged back into the develop branch to prevent regression in future releases. This discipline ensures production stability without disrupting ongoing feature development.
Choosing the Right Release Methodology
Selecting a release methodology is a critical technical and cultural decision. It functions as the operating system for an engineering team, defining the cadence of work, communication patterns, and the process for delivering value.
The right choice acts as a force multiplier, accelerating delivery and improving quality. The wrong choice introduces friction, delays, and developer frustration. This decision is not merely about process; it's a philosophical choice that dictates how teams collaborate, respond to change, and manage technical risk. Let's analyze the three primary models.
The Waterfall Model: Structured and Sequential
Waterfall is the traditional, linear approach to software development. It operates like a manufacturing assembly line where each phase—requirements, design, implementation, verification, and maintenance—must be fully completed before the next begins. Progress flows sequentially downwards, like a waterfall.
This rigid structure is well-suited for projects with fully defined, static requirements where changes are not anticipated. Examples include developing firmware for embedded systems or software for mission-critical hardware where requirements are fixed from the start.
- Best For: Projects with immutable requirements and a low degree of uncertainty.
- Key Characteristic: A strict, phase-gated progression.
- Major Drawback: Extreme inflexibility. Adapting to changes mid-project is costly and often impossible.
Because all planning is done upfront, there is no mechanism for incorporating feedback or altering course once development is underway. This makes it unsuitable for most modern software products in competitive markets.
The Agile Framework: Iteration and Feedback
Agile is an iterative framework designed to thrive in environments where change is constant. Instead of a single, long-term plan, Agile breaks down work into short, time-boxed cycles called "sprints," typically lasting one to four weeks. At the end of each sprint, the team delivers a potentially shippable increment of the product.
The entire methodology is built on a tight feedback loop, enabling continuous adaptation based on stakeholder input. Frameworks like Scrum and Kanban provide the structure for managing this iterative flow, allowing teams to pivot as new information emerges. It is the dominant methodology in modern software, with 71% of organizations reporting its use.
Agile is not just a process; it's a mindset that embraces uncertainty. It accepts that you won't have all the answers at the start and provides a framework to discover them along the way.
This makes it the standard for most software products, from mobile applications to complex SaaS platforms, where market responsiveness is a key competitive advantage.
The DevOps Culture: Automation and Collaboration
DevOps is a cultural and engineering practice that extends Agile's principles by breaking down the silos between Development (Dev) and Operations (Ops) teams, fostering a single, collaborative unit responsible for the entire application lifecycle.
The technical foundation of DevOps is automation, implemented through Continuous Integration and Continuous Delivery (CI/CD) pipelines. DevOps doesn't replace Agile; it accelerates it. While Agile focuses on iterating the product, DevOps focuses on automating and optimizing the release process itself.
- Continuous Integration (CI): Developers merge code changes into a central repository multiple times a day. Each merge triggers an automated build and a suite of tests to detect integration errors quickly.
- Continuous Delivery (CD): Once code passes all automated tests, it is automatically deployed to a staging or production environment, ensuring it is always in a releasable state.
The objective is to ship higher-quality software faster and more reliably by treating infrastructure as code and automating every repetitive task. This focus on automation is central to modern operations. Teams adopting this model must master declarative infrastructure, and can streamline your operations with GitOps as a service.
A product's position in the software product lifecycle—Introduction, Growth, Maturity, Decline—also influences the choice of methodology. A new product may benefit from Agile's flexibility, while a mature, stable product might require the stringent process controls of a DevOps culture.
Methodology Comparison: Waterfall vs. Agile vs. DevOps
To understand the practical differences, it's best to compare these models directly across key engineering attributes.
| Factor | Waterfall | Agile | DevOps |
|---|---|---|---|
| Pace of Delivery | Very slow; single monolithic release. | Fast; frequent releases on a sprint cadence. | Very fast; on-demand, continuous releases. |
| Flexibility | Extremely rigid; changes are resisted. | Highly flexible; change is expected and managed. | Extremely flexible; built for rapid adaptation. |
| Feedback Loop | Late; feedback only after final product delivery. | Early and continuous; feedback after each sprint. | Constant; real-time monitoring and user feedback. |
| Team Structure | Siloed teams (Dev, QA, Ops). | Cross-functional, self-organizing teams. | A single, integrated Dev & Ops team. |
| Risk | High; integration issues discovered late. | Low; risks are identified and mitigated each sprint. | Very low; automated gates catch issues instantly. |
| Core Focus | Adherence to the initial plan. | Responding to changing requirements. | Automating the entire software delivery pipeline. |
| Best For | Projects with fixed, well-defined requirements. | Projects with evolving requirements and uncertainty. | Complex systems requiring high speed and reliability. |
Each methodology has a valid use case. Waterfall provides predictability for stable projects, Agile offers the adaptability required for innovation, and DevOps delivers the velocity and reliability demanded by modern digital services. The optimal choice depends on project goals, team culture, and market dynamics.
Essential Metrics to Measure Release Performance
You cannot optimize what you do not measure. A data-driven approach to the release life cycle is a necessity for any high-performing engineering organization.
By tracking key performance indicators (KPIs), you replace subjective assessments with objective data, enabling you to pinpoint bottlenecks, quantify deployment risk, and systematically improve your delivery process. This is where engineering excellence is forged.
The industry standard for measuring software delivery performance is the set of metrics defined by the DevOps Research and Assessment (DORA) team. These four metrics provide a comprehensive view of both development velocity and operational stability.
The Four DORA Metrics
The DORA metrics are widely adopted because they are strongly correlated with high-performing organizations. They provide a clear framework for teams to ship better software, faster.
-
Deployment Frequency: Measures how often an organization successfully releases to production. Elite performers deploy on-demand, multiple times a day. This can be measured by querying the API of your CI/CD tool (GitLab, Jenkins, etc.) to count successful pipeline executions on the
mainbranch. -
Lead Time for Changes: Measures the time it takes for a commit to get into production. This is calculated from the first commit on a feature branch to the successful deployment of that code. Measuring this requires correlating commit timestamps from Git with deployment timestamps from pipeline logs.
-
Mean Time to Recovery (MTTR): Measures how long it takes to restore service after a production failure. This is calculated from the time an incident is detected (e.g., a monitoring alert is triggered) to the time a fix is deployed.
-
Change Failure Rate: Measures the percentage of deployments that cause a failure in production, requiring a hotfix or rollback. This is calculated by dividing the number of failed deployments by the total number of deployments. A "failure" is typically defined as any deployment that results in a P1 or P2 incident.
Beyond DORA: Other Vital Engineering Metrics
While DORA provides a high-level view, other granular metrics offer deeper insight into the development process itself, acting as leading indicators of potential issues.
- Cycle Time: A subset of Lead Time, measuring the duration from when an engineer begins active work on a task (e.g., ticket moved to "In Progress" in Jira) to when the code is merged. It helps identify bottlenecks in the development and code review stages.
- Escaped Defect Rate: The number of bugs that are not caught by QA and are discovered in production post-release. A high rate indicates weaknesses in the automated testing strategy or QA processes.
Instrumenting your pipelines to automatically collect these metrics is the first step toward continuous improvement. Data, not opinions, should drive changes to your release life cycle.
Implementing this level of tracking requires a robust monitoring and observability platform. For teams looking to build this capability, professional observability services can provide the expertise needed to achieve a clear, data-driven view of the entire system.
How to Instrument and Track KPIs
Manual tracking of these metrics is not scalable or reliable. Automation is the only viable solution.
Here is a technical implementation plan:
- Integrate Your Tools: Use webhooks and APIs to link your version control system (GitHub), CI/CD platform, and project management software.
- Tag Everything: Enforce a policy that all commit messages must reference a ticket ID. Deployment scripts should tag each release with a version number and timestamp.
- Build a Central Dashboard: Ingest this data into a centralized visualization tool like Grafana or a dedicated engineering intelligence platform. This allows you to visualize trends and correlate process changes with performance metrics.
How Modern Technology Is Reshaping Releases
The release life cycle is not static; it is continually evolving with technological advancements. Artificial intelligence, low-code platforms, and sophisticated automation are fundamentally reshaping how software is built, tested, and deployed, leading to compressed timelines and more intelligent workflows.

These are not incremental improvements but paradigm shifts that embed intelligence directly into the engineering process. Let's examine how these technologies are making a practical impact.
AI in Development and QA
Artificial intelligence has moved from a theoretical concept to a practical tool integrated into the developer's workflow. AI-powered assistants are directly accelerating code implementation and quality assurance.
Tools like GitHub Copilot function as an AI pair programmer, suggesting entire functions and code blocks in real-time. This significantly reduces the time spent on writing boilerplate code and common algorithms, allowing engineers to focus on higher-level architectural challenges.
Beyond code generation, AI is revolutionizing QA. Instead of relying solely on predefined test scripts, AI-driven testing tools can:
- Predict high-risk areas by analyzing the complexity and history of code changes to focus testing efforts where they are most needed.
- Automate test generation by observing user interaction patterns to create realistic E2E test scenarios.
- Perform visual regression testing with pixel-level accuracy, identifying subtle UI defects that human testers would likely miss.
The impact is substantial. A recent survey found that 92% of US developers are using AI coding tools, with some codebases reportedly containing up to 95% AI-generated code.
The Rise of Low-Code Platforms
Low-code and no-code platforms are another significant trend, abstracting away much of the underlying code complexity through visual interfaces and pre-built components.
For specific use cases like internal tooling or basic customer-facing applications, this approach drastically shortens the release life cycle. By empowering non-technical users to build their own solutions, these platforms offload work from core engineering teams, freeing them to concentrate on complex, high-performance systems that provide a competitive advantage.
Low-code doesn't replace traditional development; it complements it. It enables rapid delivery for standard business needs, allowing expert developers to focus their efforts on complex, high-performance code that drives unique value.
Advanced CI/CD and DevSecOps
Automation, the core of a modern release life cycle, continues to advance in sophistication. For a look at some practical applications, you can find great workflow automation examples that show what’s possible today.
A transformative development is Infrastructure as Code (IaC). Using tools like Terraform or Pulumi, operations teams define their entire infrastructure—servers, databases, networks—in declarative configuration files stored in Git. This eliminates manual configuration, prevents environment drift, and allows for the reproducible creation of environments in minutes.
Simultaneously, security is "shifting left" by integrating directly into the CI/CD pipeline through DevSecOps. Security is no longer a final gate but a continuous, automated process:
- Static Application Security Testing (SAST) tools scan source code for vulnerabilities on every commit.
- Software Composition Analysis (SCA) tools check open-source libraries for known vulnerabilities.
- Dynamic Application Security Testing (DAST) tools probe the running application for security flaws in a staging environment.
By integrating these automated checks into the pipeline, teams can identify and remediate security issues early in the development cycle, building a more secure and resilient product by design.
Common Release Management Pitfalls and How to Fix Them
Even disciplined teams encounter technical challenges. A resilient release life cycle is designed to manage these issues, but several common pitfalls can derail releases, extend timelines, and compromise quality. Addressing these technical weak points is critical for building a reliable delivery process.
Let's examine the most frequent technical problems that disrupt software releases and discuss specific, actionable solutions.
Poor Version Control and Merge Conflicts
Symptom: The main branch is frequently broken. Developers spend significant time resolving complex merge conflicts instead of developing features. There is no single source of truth for stable code.
This is a direct result of a lack of a standardized Git branching strategy. Uncontrolled commits directly to main or the use of long-lived, divergent feature branches inevitably lead to code collisions and integration hell.
The fix is to enforce a strict branching model like GitFlow. Mandate that all new development occurs on isolated feature/* branches, which are then merged into a develop branch. Protect the main branch using repository rules, requiring pull requests and successful CI builds before any code can be merged. This ensures main remains pristine and perpetually deployable.
The Dangers of Manual Deployments
Symptom: Deployments are high-stress, manual events that rely on lengthy checklists and direct server access (SSH). This results in configuration drift between environments and production outages caused by human error.
The root cause is a reliance on manual, imperative actions. Any process that requires an engineer to manually execute commands on a server is neither repeatable nor scalable and carries a high risk of error.
The fix is to begin automating the deployment process with a simple script. A shell script that automates the core steps (git pull, npm install, pm2 restart) is a significant improvement. The next step is to integrate this script into a CI/CD tool like GitLab CI or Jenkins to create a one-click deployment pipeline. This ensures every release follows an identical, version-controlled process.
The goal is to make deployments boring. When a process is fully automated, repeatable, and predictable, it removes the fear and risk associated with releasing new code.
Ignoring Technical Debt and Scope Creep
Symptom: The team is bogged down by maintenance tasks and bug fixes in legacy code, slowing down new feature development. Simultaneously, product stakeholders frequently introduce "small" requests mid-sprint, causing churn and release delays.
This is a combination of two issues: Technical debt, which accumulates when expediency is prioritized over code quality, and scope creep, which occurs without a formal process for managing new requests during an active sprint.
Both must be addressed systematically.
- For Tech Debt: Allocate a fixed capacity in every sprint—typically 10-20%—exclusively for refactoring and paying down technical debt. This prevents it from compounding into an unmanageable problem.
- For Scope Creep: Implement a formal change request process. All new requests must be added to the backlog for prioritization in a future sprint. This protects the team's focus and ensures the predictability of the release schedule.
Frequently Asked Questions
A deep dive into the release life cycle often raises practical, implementation-specific questions. Addressing these technical details is crucial for transforming theory into a smooth, predictable engineering process. Here are answers to common questions from engineers and technical leads.
How Do You Choose the Right Release Cadence?
The choice between a weekly or monthly release cadence represents a fundamental trade-off between velocity and stability.
A weekly cadence maximizes the speed of the feedback loop, allowing for rapid feature delivery and user validation. This is common in early-stage startups where market adaptation is paramount. However, it significantly compresses testing cycles and requires a high degree of test automation to mitigate the risk of shipping defects.
A monthly cadence provides more time for comprehensive regression testing, manual QA, and stakeholder reviews, generally resulting in more stable releases. This is often preferred in enterprise environments where system stability and reliability are non-negotiable. The optimal choice depends on the maturity of your automation, the risk tolerance of your business, and user expectations.
What Is the Role of a Release Manager in a DevOps Environment?
In a mature DevOps culture, the role of a release manager evolves from a gatekeeper to a process architect. They no longer manually approve deployments but instead focus on designing, building, and optimizing the automated release pipeline.
Their responsibilities shift to monitoring release health using DORA metrics, coordinating complex releases that span multiple teams, and ensuring the automated quality gates (e.g., test suites, security scans) are effective. Their goal is to empower development teams with a self-service, safe, and efficient path to production, not to act as a bottleneck.
How Can a Small Team Implement a Formal Release Process?
A formal release process does not require a large team or expensive tooling. For small teams, the key is to adopt foundational practices that build discipline.
- Adopt a consistent Git workflow: Start with a simple model like GitHub Flow, which mandates that all changes go through a pull request for peer review. This single practice dramatically improves code quality.
- Set up a simple CI pipeline: Use free tiers of tools like GitHub Actions or GitLab CI to automatically run unit tests on every commit. This establishes your first automated quality gate.
- Create a deployment checklist: Even for manual deployments, a version-controlled checklist ensures critical steps are not forgotten and reduces human error.
These fundamental practices provide the necessary structure to build a scalable and reliable release life cycle.
Ready to build a high-performing release pipeline without the overhead? OpsMoon connects you with the top 0.7% of remote DevOps engineers to accelerate your delivery, optimize your infrastructure, and implement best practices from day one. Start with a free work planning session and see how our experts can transform your process. Learn more at OpsMoon.